
Maison >Périphériques technologiques >IA >Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-07-26 08:40:141110parcourir
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. autre modèle d'excellentes performances. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines.
En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont également été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, InternVL 1.5 pour les tâches de langage visuel (qui est utilisé dans certains domaines comparables). à GPT-4-Turbo-2024-04-09).
En tant que « roi de la pelle à l'ère de la ruée vers l'or de l'IA », NVIDIA elle-même apporte également des contributions au domaine des modèles ouverts, comme la série de modèles ChatQA qu'elle a développée. Veuillez vous référer au rapport sur ce site ". Le nouveau modèle d'assurance qualité de dialogue de NVIDIA est plus précis que GPT-4, mais j'ai été critiqué : le code non pondéré n'a que peu de sens.》. Plus tôt cette année, ChatQA 1.5 a été publié, qui intègre la technologie de génération augmentée de récupération (RAG) et surpasse GPT-4 en matière de réponse aux questions conversationnelles.
Maintenant, ChatQA a évolué vers la version 2.0. La principale direction d'amélioration cette fois est d'élargir la fenêtre contextuelle.

Titre de l'article : ChatQA 2 : Combler l'écart avec les LLM propriétaires dans un contexte long et les capacités RAG
Adresse de l'article : https://arxiv.org/pdf/2407.14482
Récemment, L'extension de la longueur de la fenêtre de contexte de LLM est un point chaud majeur en matière de recherche et de développement. Par exemple, ce site a rapporté un jour "Agrandissement direct à l'infini, Google Infini-Transformer met fin au débat sur la longueur du contexte".
Tous les principaux LLM propriétaires prennent en charge de très grandes fenêtres contextuelles - vous pouvez lui fournir des centaines de pages de texte en une seule invite. Par exemple, les tailles de fenêtre contextuelle de GPT-4 Turbo et Claude 3.5 Sonnet sont respectivement de 128 Ko et 200 Ko. Gemini 1.5 Pro peut prendre en charge un contexte d'une longueur de 10 M, ce qui est incroyable.
Cependant, les grands modèles open source rattrapent également leur retard. Par exemple, QWen2-72B-Instruct et Yi-34B prennent respectivement en charge 128 000 et 200 000 fenêtres contextuelles. Cependant, les données de formation et les détails techniques de ces modèles ne sont pas accessibles au public, ce qui rend difficile leur reproduction. De plus, l’évaluation de ces modèles repose principalement sur des tâches synthétiques et ne peut pas représenter avec précision les performances sur des tâches réelles en aval. Par exemple, plusieurs études ont montré qu'il existe encore un écart important entre le LLM ouvert et les principaux modèles propriétaires sur les tâches réelles de compréhension de contextes longs.
Et l'équipe NVIDIA a réussi à faire en sorte que les performances de l'open Llama-3 rattrapent celles du GPT-4 Turbo propriétaire sur des tâches de compréhension de contextes longs du monde réel.
Dans la communauté LLM, les capacités de contexte long sont parfois considérées comme une technologie en concurrence avec RAG. Mais en réalité, ces technologies peuvent se renforcer mutuellement.
Pour le LLM avec une longue fenêtre contextuelle, en fonction des tâches en aval et du compromis entre précision et efficacité, vous pouvez envisager de joindre une grande quantité de texte à l'invite, ou vous pouvez utiliser des méthodes de récupération pour extraire efficacement les informations pertinentes de une grande quantité de texte. RAG présente des avantages évidents en termes d'efficacité et peut facilement récupérer des informations pertinentes à partir de milliards de jetons pour des tâches basées sur des requêtes. C’est un avantage que les modèles à contexte long ne peuvent pas avoir. Les modèles à contexte long, en revanche, sont très efficaces pour des tâches telles que la synthèse de documents, pour lesquelles RAG n'est peut-être pas doué.
Par conséquent, pour un LLM avancé, les deux capacités sont requises afin que l'une puisse être considérée en fonction des tâches en aval et des exigences de précision et d'efficacité.
Auparavant, le modèle open source ChatQA 1.5 de NVIDIA était capable de surpasser GPT-4-Turbo sur les tâches RAG. Mais ils ne se sont pas arrêtés là. Ils ont désormais ChatQA 2 open source, qui intègre également des capacités de compréhension de contexte long comparables à GPT-4-Turbo !
Plus précisément, ils sont basés sur le modèle Llama-3, étendant sa fenêtre de contexte à 128K (à égalité avec GPT-4-Turbo), tout en l'équipant du meilleur récupérateur de contexte long actuellement disponible.
Agrandissez la fenêtre contextuelle à 128K
Alors, comment NVIDIA a-t-il augmenté la fenêtre contextuelle de Llama-3 de 8K à 128K ? Tout d'abord, ils ont préparé un long corpus de pré-formation contextuel basé sur Slimpajama, en utilisant la méthode de l'article « Data Engineering for Scaling Language Models to 128k Context » de Fu et al.
Ils ont également fait une découverte intéressante au cours du processus de formation : par rapport à l'utilisation des jetons de début et de fin d'origine pour séparer différents documents aura un meilleur effet. Ils supposent que la raison est que les jetons
Utilisation de données de contexte long pour le réglage fin des instructions
L'équipe a également conçu une méthode de réglage fin des instructions qui peut simultanément améliorer les capacités de compréhension du contexte long du modèle et les performances RAG.
Secara khusus, kaedah penalaan halus arahan ini dibahagikan kepada tiga peringkat. Dua peringkat pertama adalah sama seperti dalam ChatQA 1.5, iaitu pertama melatih model pada set data pematuhan arahan berkualiti tinggi 128K, dan kemudian latihan pada campuran data Soal Jawab perbualan dan konteks yang disediakan. Walau bagaimanapun, konteks yang terlibat dalam kedua-dua peringkat adalah agak pendek - panjang jujukan maksimum tidak lebih daripada token 4K. Untuk meningkatkan saiz tetingkap konteks model kepada 128K token, pasukan itu mengumpulkan set data penalaan halus (SFT) yang diselia lama.
Ia menggunakan dua kaedah pengumpulan:
1 Untuk jujukan data SFT yang lebih pendek daripada 32k: menggunakan set data konteks panjang sedia ada berdasarkan sampel LongAlpaca12k, GPT-4 daripada Open Orca dan Pengumpulan Data Panjang.
2 Untuk data dengan panjang jujukan antara 32k dan 128k: Disebabkan kesukaran mengumpul sampel SFT sedemikian, mereka memilih set data sintetik. Mereka menggunakan NarrativeQA, yang mengandungi kedua-dua kebenaran asas dan perenggan yang berkaitan secara semantik. Mereka mengumpulkan semua perenggan yang berkaitan bersama-sama dan secara rawak memasukkan ringkasan sebenar untuk mensimulasikan dokumen panjang sebenar untuk pasangan soalan dan jawapan.
Kemudian, set data SFT penuh dan set data SFT pendek yang diperoleh dalam dua peringkat pertama digabungkan bersama dan kemudian dilatih. Di sini kadar pembelajaran ditetapkan kepada 3e-5 dan saiz kelompok ialah 32.
Retriever konteks panjang memenuhi LLM konteks panjang
Terdapat beberapa masalah dengan proses RAG yang sedang digunakan oleh LLM:
1 Untuk menjana jawapan yang tepat, pengambilan blok demi blok atas-k akan memperkenalkan bukan-. serpihan konteks yang boleh diabaikan. Sebagai contoh, retriever berasaskan benam padat terkini yang terkini hanya menyokong 512 token.
2 Top-k yang kecil (seperti 5 atau 10) akan membawa kepada kadar ingatan yang agak rendah, manakala top-k yang besar (seperti 100) akan membawa kepada hasil penjanaan yang lemah kerana LLM sebelumnya tidak dapat digunakan dengan baik. .
Untuk menyelesaikan masalah ini, pasukan mencadangkan untuk menggunakan pengutip konteks panjang terbaharu, yang menyokong beribu-ribu token. Khususnya, mereka memilih untuk menggunakan model benam E5-mistral sebagai retriever.
Jadual 1 membandingkan pengambilan top-k untuk saiz blok yang berbeza dan jumlah bilangan token dalam tetingkap konteks.

Membandingkan perubahan dalam bilangan token dari 3000 hingga 12000, pasukan mendapati bahawa lebih banyak token, lebih baik hasilnya, yang mengesahkan bahawa keupayaan konteks panjang model baharu itu memang bagus. Mereka juga mendapati bahawa jika jumlah bilangan token ialah 6000, terdapat pertukaran yang lebih baik antara kos dan prestasi. Apabila jumlah bilangan token ditetapkan kepada 6000, mereka mendapati bahawa lebih besar blok teks, lebih baik hasilnya. Oleh itu, dalam percubaan mereka, tetapan lalai yang mereka pilih ialah saiz blok 1200 dan blok teks 5 teratas.
Experiments evaluation Benchmarks urutan untuk menjalankan penilaian komprehensif dan menganalisis panjang konteks yang berbeza, pasukan menggunakan tiga jenis penanda aras penilaian:
1 2. Penanda aras konteks sederhana panjang, kurang daripada 32K token3. Penanda aras konteks pendek, kurang daripada 4K token.
Jika tugas hiliran boleh menggunakan RAG, ia akan menggunakan RAG.Keputusan
Pasukan mula-mula menjalankan ujian Needle in a Haystack berdasarkan data sintetik, dan kemudian menguji pemahaman konteks panjang dunia sebenar model dan keupayaan RAG. 1. Jarum dalam ujian tumpukan jeramiLlama3-ChatQA-2-70B Bolehkah anda mencari jarum sasaran dalam lautan teks? Ini ialah tugas sintetik yang biasa digunakan untuk menguji keupayaan konteks panjang LLM dan boleh dilihat sebagai menilai tahap ambang LLM. Rajah 1 menunjukkan prestasi model baharu dalam token 128K Dapat dilihat ketepatan model baharu itu mencapai 100%. Ujian ini mengesahkan bahawa model baharu itu mempunyai keupayaan mendapatkan semula konteks panjang yang sempurna.
2 Penilaian konteks panjang melebihi 100K token
Mengenai tugas dunia sebenar dari InfiniteBench, pasukan menilai prestasi model apabila panjang konteks melebihi 100K token. Keputusan ditunjukkan dalam Jadual 2.
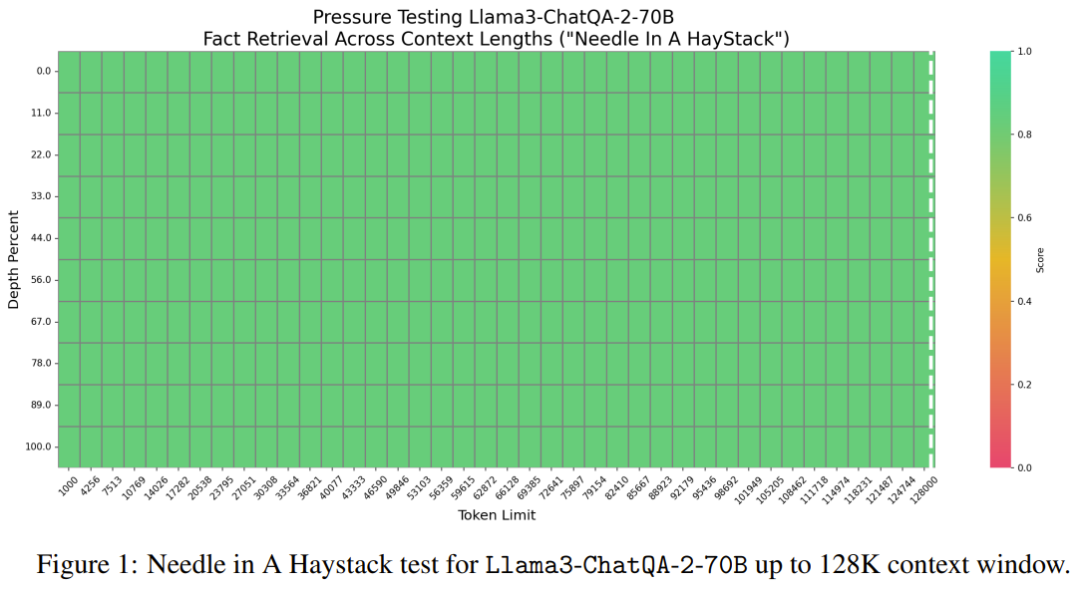 Dapat dilihat bahawa model baharu ini berprestasi lebih baik daripada kebanyakan model terbaik semasa, seperti GPT4-Turbo-2024-04-09 (33.16), pratonton GPT4-1106 (28.23), Llama-3-70B- Arahkan -Gradient-262k (32.57) dan Claude 2 (33.96). Di samping itu, skor model baharu adalah sangat hampir dengan skor tertinggi iaitu 34.88 yang diperolehi oleh Qwen2-72B-Instruct. Secara keseluruhan, model baharu Nvidia agak kompetitif.
Dapat dilihat bahawa model baharu ini berprestasi lebih baik daripada kebanyakan model terbaik semasa, seperti GPT4-Turbo-2024-04-09 (33.16), pratonton GPT4-1106 (28.23), Llama-3-70B- Arahkan -Gradient-262k (32.57) dan Claude 2 (33.96). Di samping itu, skor model baharu adalah sangat hampir dengan skor tertinggi iaitu 34.88 yang diperolehi oleh Qwen2-72B-Instruct. Secara keseluruhan, model baharu Nvidia agak kompetitif.
3 Penilaian konteks sederhana panjang dengan bilangan token dalam lingkungan 32K
Jadual 3 menunjukkan prestasi setiap model apabila bilangan token dalam konteks adalah dalam lingkungan 32K.
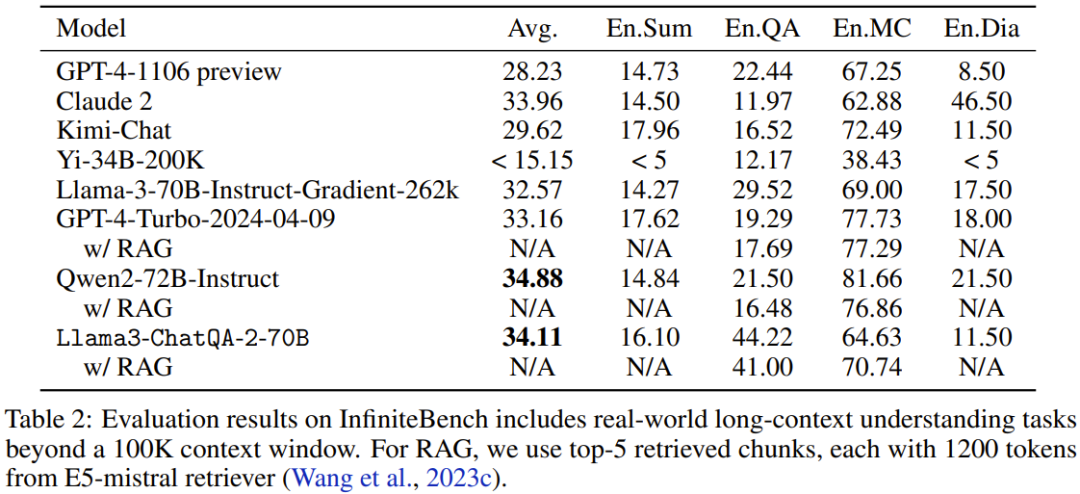
Seperti yang anda lihat, GPT-4-Turbo-2024-04-09 mempunyai markah tertinggi, 51.93. Skor model baharu ialah 47.37, iaitu lebih tinggi daripada Llama-3-70B-Instruct-Gradient-262k tetapi lebih rendah daripada Qwen2-72B-Instruct. Sebabnya mungkin pra-latihan Qwen2-72B-Instruct banyak menggunakan token 32K, manakala korpus pra-latihan berterusan yang digunakan oleh pasukan adalah jauh lebih kecil. Tambahan pula, mereka mendapati bahawa semua penyelesaian RAG berprestasi lebih teruk daripada penyelesaian konteks panjang, menunjukkan bahawa semua LLM konteks panjang terkini ini boleh mengendalikan 32K token dalam tetingkap konteksnya.
4 Bangku ChatRAG: Penilaian konteks pendek dengan bilangan token kurang daripada 4K
Di Bangku ChatRAG, pasukan menilai prestasi model apabila panjang konteks kurang daripada token 4K, lihat Jadual 4.
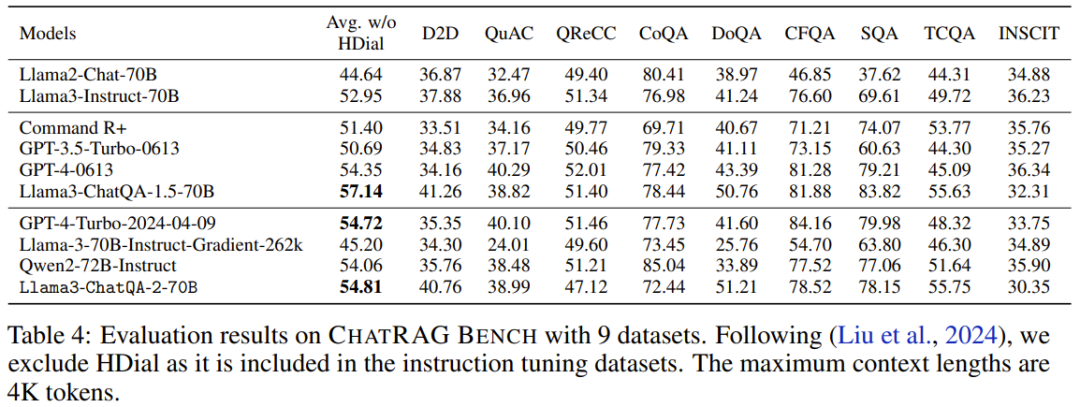
Purata markah model baharu ialah 54.81. Walaupun keputusan ini tidak sebaik Llama3-ChatQA-1.5-70B, ia masih lebih baik daripada GPT-4-Turbo-2024-04-09 dan Qwen2-72B-Instruct. Ini membuktikan maksudnya: memanjangkan model konteks pendek kepada model konteks panjang memerlukan kos. Ini juga membawa kepada arah penyelidikan yang patut diterokai: Bagaimana untuk mengembangkan lagi tetingkap konteks tanpa menjejaskan prestasinya pada tugas konteks pendek?
5. Membandingkan RAG dengan konteks yang panjang
Jadual 5 dan 6 membandingkan prestasi RAG dengan penyelesaian konteks yang panjang apabila menggunakan panjang konteks yang berbeza. Apabila panjang jujukan melebihi 100K, hanya purata markah untuk En.QA dan En.MC dilaporkan kerana tetapan RAG tidak tersedia secara langsung untuk En.Sum dan En.Dia.
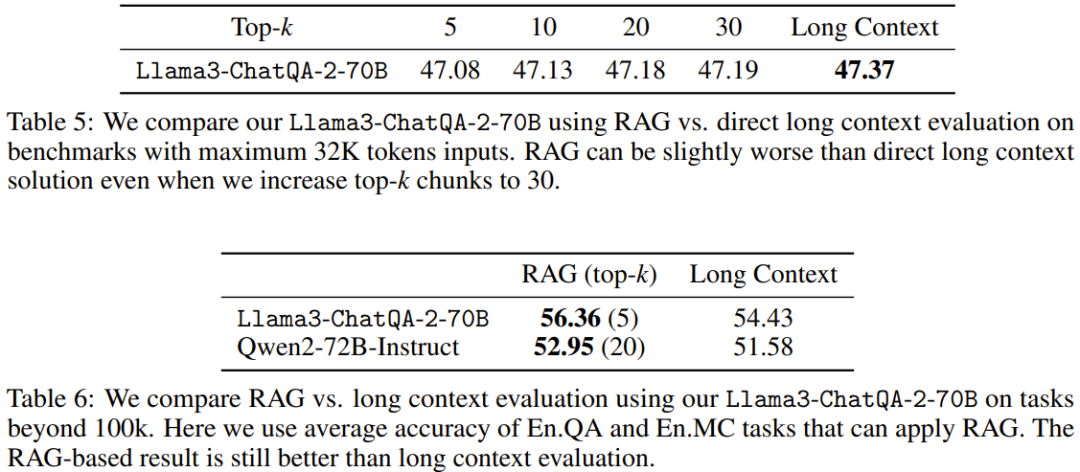
Ia boleh dilihat bahawa penyelesaian konteks panjang yang baru dicadangkan mengatasi prestasi RAG apabila panjang jujukan tugas hiliran kurang daripada 32K. Ini bermakna penggunaan RAG menghasilkan penjimatan kos, tetapi dengan mengorbankan ketepatan.
Sebaliknya, RAG (5 teratas untuk Llama3-ChatQA-2-70B dan 20 teratas untuk Qwen2-72B-Instruct) mengatasi penyelesaian konteks panjang apabila panjang konteks melebihi 100K. Ini bermakna apabila bilangan token melebihi 128K, LLM konteks panjang terbaik semasa mungkin mengalami kesukaran untuk mencapai pemahaman dan penaakulan yang berkesan. Pasukan mengesyorkan bahawa dalam kes ini, gunakan RAG apabila boleh kerana ia boleh membawa ketepatan yang lebih tinggi dan kos inferens yang lebih rendah.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI