Llama 3.1 est enfin apparu, mais la source n'est pas officielle Meta. Aujourd'hui, la nouvelle de la fuite du nouveau grand modèle Llama est devenue virale sur Reddit En plus du modèle de base, elle comprend également des résultats de référence de 8B, 70B et le paramètre maximum de 405B. 
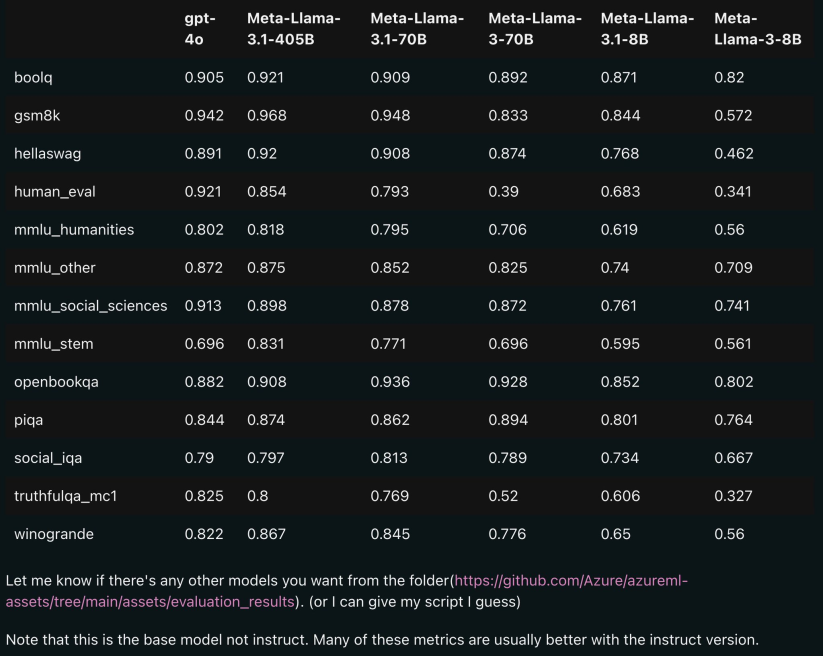
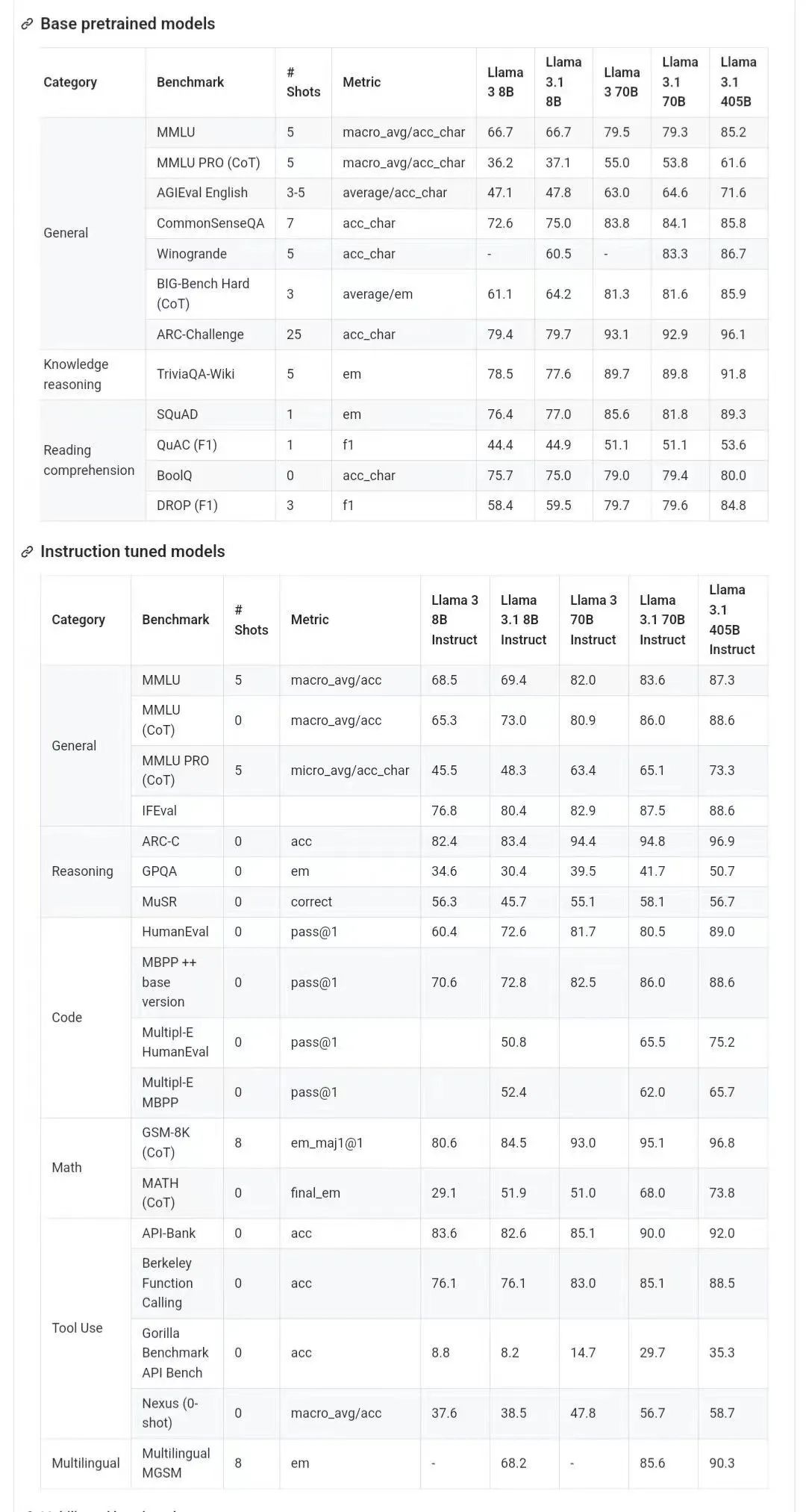
L'image ci-dessous montre les résultats de comparaison de chaque version de Llama 3.1 avec OpenAI GPT-4o et Llama 3 8B/70B. Comme vous pouvez le voir, même la version 70B surpasse GPT-4o sur plusieurs benchmarks.
, les modèles 8B et 70B de la version 3.1 sont distillés à partir du 405B, donc par rapport à la génération précédente présentaient des améliorations de performances significatives.
Certains internautes ont déclaré que c'était la première fois qu'un modèle open source surpassait les modèles fermés tels que GPT4o et Claude Sonnet 3.5 et atteignait SOTA sur plusieurs benchmarks.
Dans le même temps, la carte modèle de Llama 3.1 a fuité et les détails ont été divulgués (la date indiquée sur la carte modèle indique qu'elle est basée sur la version du 23 juillet).
Quelqu'un a résumé les points forts suivants :
Le modèle utilise plus de 15 T de jetons provenant de sources publiques pour la formation, et la date limite pour les données de pré-formation est décembre 2023
Les données de réglage fin incluent les données publiques ; Ensemble de données de réglage fin d'instructions disponible (contrairement à Llama 3) et 15 millions d'échantillons synthétiques
- Le modèle prend en charge plusieurs langues, dont l'anglais, le français, l'allemand, l'hindi, l'italien, le portugais, l'espagnol et le thaï ;
-
Bien que le lien Github divulgué soit actuellement 404, certains internautes ont donné des liens de téléchargement (cependant, pour des raisons de sécurité, il est recommandé d'attendre l'annonce officielle de la chaîne ce soir) :
Mais il s'agit d'un modèle de niveau 100 milliards après tout, veuillez préparer suffisamment d'espace disque dur avant de télécharger :
Ce qui suit est le modèle Llama 3.1 Contenu important de la carte :
Basique informations sur le modèle
La collection Meta Llama 3.1 Multilingual Large Language Model (LLM) est un ensemble de modèles génératifs pré-entraînés et réglés avec précision, chacun d'une taille de 8B, 70B et 405B (saisie de texte/sortie de texte). Les modèles texte uniquement affinés par commande Llama 3.1 (8B, 70B, 405B) sont optimisés pour les cas d'utilisation de conversations multilingues et surpassent de nombreux modèles de discussion open source et fermés disponibles sur les références courantes de l'industrie. Architecture du modèle : Llama 3.1 est un modèle de langage autorégressif d'architecture Transformer optimisé. La version affinée utilise SFT et RLHF pour aligner les préférences d'utilisabilité et de sécurité.
Langues prises en charge : anglais, allemand, français, italien, portugais, hindi, espagnol et thaï. On peut déduire des informations de la carte modèle que la longueur du contexte du modèle de la série
Llama 3.1 est de 128k. Toutes les versions du modèle utilisent Grouped Query Attention (GQA) pour améliorer l'évolutivité de l'inférence.
CAS D'UTILISATION PRÉVUE. Llama 3.1 est destiné aux applications commerciales et à la recherche multilingues. Les modèles textuels adaptés aux instructions conviennent au chat de type assistant, tandis que les modèles pré-entraînés peuvent être adaptés à une variété de tâches de génération de langage naturel. L'ensemble de modèles Llama 3.1 prend également en charge la possibilité d'exploiter la sortie de son modèle pour améliorer d'autres modèles, notamment la génération et la distillation de données synthétiques. La licence communautaire Llama 3.1 autorise ces cas d'utilisation. Llama 3.1 s'entraîne sur un ensemble de langues plus large que les 8 langues prises en charge. Les développeurs peuvent affiner les modèles Llama 3.1 pour des langues autres que les 8 langues prises en charge, à condition qu'ils respectent le contrat de licence communautaire Llama 3.1 et la politique d'utilisation acceptable, et sont responsables dans de tels cas de garantir que d'autres langues sont utilisées dans de manière sûre et responsable Langue Lama 3.1. Infrastructure logicielle et matérielleLe premier est l'élément de formation. Llama 3.1 utilise une bibliothèque de formation personnalisée, un cluster GPU méta-personnalisé et une infrastructure de production pour la pré-formation, et est également affiné sur. l'infrastructure de production, l'annotation et l'évaluation. La seconde est la consommation d'énergie de la formation. La formation Llama 3.1 utilise un total de 39,3 M d'heures de calcul GPU sur du matériel de type H100-80GB (TDP est de 700W). Ici, le temps de formation est le temps total du GPU requis pour former chaque modèle, et la consommation d'énergie est la capacité de puissance maximale de chaque périphérique GPU, ajustée en fonction de l'efficacité énergétique. Formation sur les émissions de gaz à effet de serre. Les émissions totales de gaz à effet de serre sur la base de références géographiques sont estimées à 11 390 tonnes d'équivalent CO2 pendant la période de formation de Llama 3.1. Depuis 2020, Meta a maintenu zéro émission nette de gaz à effet de serre dans l'ensemble de ses opérations mondiales et a associé 100 % de sa consommation d'électricité à des énergies renouvelables, ce qui a abouti à des émissions totales de gaz à effet de serre de référence du marché de 0 tonne d'équivalent CO2 pendant la période de formation. Les méthodes utilisées pour déterminer la consommation d'énergie et les émissions de gaz à effet de serre de la formation se trouvent dans l'article suivant. Étant donné que Meta publie ces modèles publiquement, d'autres n'ont pas besoin de supporter le fardeau de la formation sur la consommation d'énergie et les émissions de gaz à effet de serre. Adresse papier : https://arxiv.org/pdf/2204.05149Aperçu : Llama 3.1 a été réalisé en utilisant environ 1,5 billion de données symboliques provenant de sources publiques pré-. entraînement. Les données de réglage fin incluent des ensembles de données d'instructions accessibles au public et plus de 25 millions d'exemples générés synthétiquement. Fraîcheur des données : La date limite pour les données de pré-formation est décembre 2023. Dans cette section, Meta rapporte les résultats de notation du modèle Llama 3.1 sur le benchmark d'annotation. Pour toutes les évaluations, Meta utilise des bibliothèques d'évaluation internes.
Pertimbangan Risiko KeselamatanPasukan penyelidik Llama komited untuk menyediakan komuniti penyelidik dengan sumber yang berharga untuk mengkaji keteguhan penalaan halus keselamatan dan menyediakan pembangun dengan model luar yang selamat dan teguh untuk pelbagai aplikasi untuk Mengurangkan beban kerja pembangun yang menggunakan sistem AI selamat. Pasukan penyelidik menggunakan pendekatan pengumpulan data pelbagai segi, menggabungkan data yang dijana manusia daripada vendor dengan data sintetik untuk mengurangkan potensi risiko keselamatan. Pasukan penyelidik membangunkan beberapa pengelas berasaskan model bahasa besar (LLM) untuk memilih gesaan dan respons berkualiti tinggi dengan teliti, dengan itu meningkatkan kawalan kualiti data. Perlu dinyatakan bahawa Llama 3.1 sangat mementingkan penolakan model terhadap gesaan jinak dan nada penolakan. Pasukan penyelidik memperkenalkan gesaan sempadan dan gesaan lawan ke dalam dasar data selamat dan mengubah suai respons data selamat untuk mengikut garis panduan nada. Model Llama 3.1 tidak direka bentuk untuk digunakan secara bersendirian, tetapi harus digunakan sebagai sebahagian daripada keseluruhan sistem kecerdasan buatan, dengan tambahan "pengadang keselamatan" disediakan mengikut keperluan. Pembangun harus menggunakan langkah keselamatan sistem apabila membina sistem ejen. Sila ambil perhatian bahawa keluaran ini memperkenalkan ciri baharu, termasuk tetingkap konteks yang lebih panjang, input dan output berbilang bahasa, dan kemungkinan integrasi pembangun dengan alatan pihak ketiga. Apabila membina dengan ciri baharu ini, selain mempertimbangkan amalan terbaik yang biasanya digunakan untuk semua kes penggunaan AI generatif, anda juga perlu memberi perhatian khusus kepada isu berikut: Penggunaan alat: Seperti pembangunan perisian standard, pembangun bertanggungjawab Mengintegrasikan LLM dengan alatan dan perkhidmatan pilihan mereka. Mereka harus membangunkan dasar yang jelas untuk kes penggunaan mereka dan menilai integriti perkhidmatan pihak ketiga yang mereka gunakan untuk memahami had keselamatan dan keselamatan apabila menggunakan fungsi ini. Berbilang bahasa: Lama 3.1 menyokong 7 bahasa selain bahasa Inggeris: Perancis, Jerman, Hindi, Itali, Portugis, Sepanyol dan Thai. Llama mungkin boleh mengeluarkan teks dalam bahasa lain, tetapi teks ini mungkin tidak memenuhi ambang prestasi keselamatan dan kebolehbantuan. Nilai teras Llama 3.1 ialah keterbukaan, keterangkuman dan sifat membantu. Ia direka untuk memberi perkhidmatan kepada semua orang dan sesuai untuk pelbagai kes penggunaan. Oleh itu, Llama 3.1 direka bentuk untuk boleh diakses oleh semua orang dari semua latar belakang, pengalaman dan perspektif. Llama 3.1 berpusat di sekitar pengguna dan keperluan mereka, tanpa memasukkan pertimbangan atau norma yang tidak perlu, sambil juga mencerminkan pengiktirafan bahawa kandungan yang mungkin kelihatan bermasalah dalam sesetengah konteks boleh berguna dalam tujuan nilai yang lain. Llama 3.1 menghormati maruah dan autonomi semua pengguna dan, khususnya, menghormati nilai pemikiran dan ekspresi bebas yang menyemarakkan inovasi dan kemajuan. Tetapi Llama 3.1 ialah teknologi baharu, dan seperti mana-mana teknologi baharu, terdapat risiko dalam penggunaannya. Ujian yang dijalankan sehingga kini belum dan tidak boleh meliputi semua situasi. Oleh itu, seperti semua LLM, potensi keluaran Llama 3.1 tidak boleh diramalkan terlebih dahulu, dan dalam beberapa kes model mungkin bertindak balas secara tidak tepat, berat sebelah atau sebaliknya tidak menyenangkan terhadap gesaan pengguna. Oleh itu, sebelum menggunakan sebarang aplikasi model Llama 3.1, pembangun harus melakukan ujian keselamatan dan penalaan halus untuk aplikasi khusus model tersebut. Sumber kad model: https://pastebin.com/9jGkYbXYMaklumat rujukan: https://x.com/op7418/status/10315/30 https: //x.com/iScienceLuvr/status/1815519917715730702https://x.com/mattshumer_/status/1815444612414087294Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn