Actuellement, les modèles linguistiques autorégressifs à grande échelle utilisant le prochain paradigme de prédiction de jetons sont devenus populaires partout dans le monde. Dans le même temps, un grand nombre d'images et de vidéos synthétiques sur Internet nous ont déjà montré le pouvoir de la diffusion. des modèles.
Récemment, une équipe de recherche du MIT CSAIL (dont Chen Boyuan, doctorant au MIT) a intégré avec succès les puissantes capacités du modèle de diffusion de séquence complète et du prochain modèle de jeton, et a proposé une formation et un échantillonnage paradigme : Forçage de Diffusion (DF).
Titre de l'article : Forçage de diffusion : la prédiction du prochain jeton rencontre la diffusion en séquence complète
Adresse de l'article : https://arxiv.org/pdf/2407.01392
Site Web du projet : https:/ /arxiv.org/pdf/2407.01392 /boyuan.space/diffusion-forcing
Adresse du code : https://github.com/buoyancy99/diffusion-forcing
Comme indiqué ci-dessous, le forçage de diffusion surpasse clairement tout en termes de cohérence et de stabilité Deux méthodes sont la diffusion de séquences et le forçage par l'enseignant.

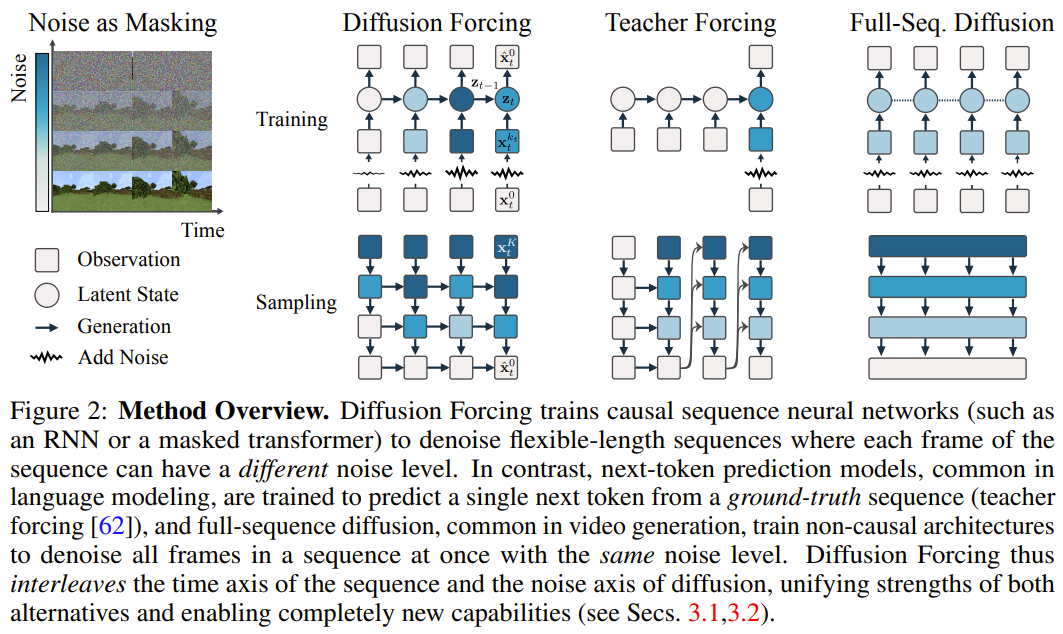
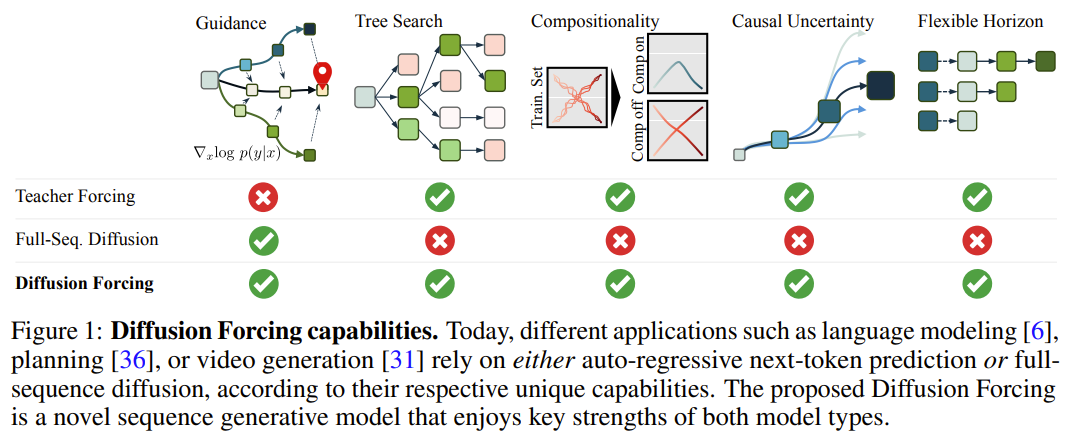
Dans ce cadre, chaque jeton est associé à un niveau de bruit aléatoire et indépendant, et un modèle de prédiction du prochain jeton partagé ou un modèle de prédiction du prochain jeton peut être utilisé selon un schéma arbitraire et indépendant par jeton pour réduire le bruit du jeton. L'inspiration de recherche de cette méthode vient de cette observation : le processus d'ajout de bruit au jeton est une forme de processus de masquage partiel - zéro bruit signifie que le jeton n'est pas masqué, tandis que le bruit complet est un jeton de masquage complet. Par conséquent, DF force le modèle à apprendre un masque qui supprime tout ensemble variable de jetons bruyants (Figure 2). Dans le même temps, en paramétrant la méthode de prédiction comme une combinaison de plusieurs modèles de prédiction de prochains jetons, le système peut générer de manière flexible des séquences de différentes longueurs et généraliser à de nouvelles trajectoires de manière combinatoire (Figure 1). L'équipe a implémenté le DF utilisé pour la génération de séquences dans le Forçage de Diffusion Causale (CDF), dans lequel les jetons futurs dépendent des jetons passés via une architecture causale. Ils ont entraîné le modèle à débruiter tous les jetons d’une séquence (chaque jeton ayant un niveau de bruit indépendant) en même temps. Pendant l'échantillonnage, CDF débruitera progressivement une séquence de trames de bruit gaussien en échantillons propres, où différentes trames peuvent avoir des niveaux de bruit différents à chaque étape de débruitage. Semblable au modèle de prédiction du prochain jeton, CDF peut générer des séquences de longueur variable ; contrairement à la prédiction du prochain jeton, les performances de CDF sont très stables, qu'il s'agisse de prédire le prochain jeton, des milliers de jetons dans le futur ou même un jeton en continu. De plus, à l'instar de la diffusion en séquence complète, il peut également recevoir des conseils, permettant de générer des récompenses élevées. En exploitant de manière collaborative la causalité, la portée flexible et la planification variable du bruit, CDF permet une nouvelle fonctionnalité : Monte Carlo Tree Guidance (MCTG). Par rapport au modèle de diffusion de séquence complète non causale, le MCTG peut considérablement améliorer le taux d'échantillonnage de génération de récompenses élevées. La figure 1 donne un aperçu de ces capacités. Forçage de diffusion (forçage de diffusion) 1 Traitez le processus d'ajout de bruit comme un masque partiel Tout d'abord, nous pouvons traiter n'importe quel ensemble de jetons (qu'il s'agisse d'une séquence ou non) comme Une collection ordonnée indexée par t. Ensuite, utiliser le forçage de l'enseignant pour entraîner la prochaine prédiction de jeton peut être interprété comme masquant chaque jeton x_t au temps t et les prédire en fonction du passé x_{1:t−1}. Pour les séquences, cette opération peut être décrite comme : effectuer un masquage le long de la timeline. Nous pouvons considérer la diffusion directe en séquence complète (c'est-à-dire le processus d'ajout progressif de bruit aux données ) comme une sorte de masquage partiel, que l'on peut appeler "effectuer un masquage le long de l'axe du bruit En fait, après avoir ajouté du bruit par K étapes, est (probablement) du bruit blanc, et il n'y a plus d'informations sur les données d'origine. Comme le montre la figure 2, l'équipe a établi une perspective unifiée pour examiner les masques pour ces deux axes. 2. Forçage de diffusion : différents jetons ont des niveaux de bruit différents Le cadre de forçage de diffusion (DF) peut être utilisé pour entraîner et échantillonner des jetons bruyants de longueurs de séquence arbitraires , où la clé est que le le niveau de bruit k_t de chaque jeton change avec les pas de temps.
Cet article se concentre sur les données de séries chronologiques, ils instancient donc DF via une architecture causale, et obtiennent ainsi un forçage de diffusion causal (CDF). implémentation minimale obtenue en utilisant un réseau neuronal récurrent de base (RNN). Un RNN de poids θ maintient un état caché z_t qui est informé de l'influence des jetons passés. Il évoluera selon la dynamique à travers une couche de boucle.입력 노이즈 관찰
을 얻으면 숨겨진 상태가 Markovian 방식으로 업데이트됩니다.
k_t=0이면 베이지안 필터링의 사후 업데이트이고, k_t=K(순수 잡음, 정보 없음)이면 "사후 분포" p_θ(z_t | z_{)를 모델링하는 것과 동일합니다. t-1}). 은닉 상태 z_t가 주어지면 관측 모델 p_θ(x_t^0 | z_t)의 목표는 x_t를 예측하는 것입니다. 이 유닛의 입출력 동작은 표준 조건부 확산 모델과 동일합니다. 조건변수 z_{t−1 } 및 노이즈 토큰을 입력으로 사용하여 노이즈가 없는 x_t=x_t^0을 예측하고 아핀 재매개변수화를 통해 노이즈 ε^{k_t}를 간접적으로 예측합니다. 따라서 우리는 (인과적인) 확산 강제력을 훈련시키기 위해 전통적인 확산 목표를 직접 사용할 수 있습니다. 잡음 예측 결과 ε_θ에 따라 위의 단위를 매개변수화할 수 있다. 그런 다음 다음 손실을 최소화하여 매개변수 θ를 찾습니다. 알고리즘 1은 의사 코드를 제공합니다. 요점은 이 손실이 베이지안 필터링과 조건부 확산의 핵심 요소를 포착한다는 것입니다. 또한 팀은 원본 논문의 부록에 자세히 설명된 대로 확산 강제에 대한 확산 모델 훈련에 사용되는 일반적인 기술을 다시 추론했습니다. 그들은 또한 비공식적인 정리에 도달했습니다. 정리 3.1(비공식). 확산 강제 훈련 절차(알고리즘 1)는 기대 로그 가능성 에 대한 증거 하한(ELBO)을 최적화하는 재가중화입니다. 여기서 기대 값은 잡음 수준에 대해 평균화되고 는 순방향 프로세스에 따라 잡음이 있습니다. 또한 적절한 조건에서 최적화(3.1)를 수행하면 모든 잡음 수준 시퀀스의 우도 하한을 동시에 최대화할 수도 있습니다. 알고리즘 2는 샘플링 프로세스를 설명하며 다음과 같이 정의됩니다. 2차원 M × T 그리드 K ∈ [K]^{M×T }는 노이즈 일정을 지정합니다. 여기서 열은 시간 단계 t에 해당하고 m으로 인덱스된 행은 노이즈 수준을 결정합니다. 길이 T의 전체 시퀀스를 생성하기 위해 토큰 x_{1:T}는 먼저 잡음 수준 k = K에 해당하는 백색 잡음으로 초기화됩니다. 그런 다음 그리드 아래로 행별로 반복하고 노이즈 수준이 K에 도달할 때까지 왼쪽에서 오른쪽으로 열별로 노이즈를 제거합니다. 마지막 행의 m = 0이 될 때까지 토큰의 노이즈는 제거되었습니다. 즉, 노이즈 수준은 K_{0,t} Д 0입니다. 이 샘플링 패러다임은 다음과 같은 새로운 기능을 제공합니다.
유연한 순서 결정을 위해 확산 강제를 사용하세요확산 강제의 새로운 능력은 또한 새로운 가능성을 가져옵니다. 이를 기반으로 연구팀은 SDM(Sequence Decision Making)을 위한 새로운 프레임워크를 설계하고 이를 로봇 및 자율행위자 분야에 성공적으로 적용했다. 먼저 동적 p(s_{t+1}|s_t, a_t), 관찰 p(o_t|s_t) 및 보상 p(r_t|s_t, a_t)를 사용하여 Markov 결정 프로세스를 정의합니다. 여기서 목표는 궤적 의 예상 누적 보상을 최대화하기 위해 정책 π(a_t|o_{1:t})를 훈련하는 것입니다. 여기서는 x_t = [a_t, r_t, o_{t+1}] 토큰이 할당됩니다. 궤도는 길이가 가변적일 수 있는 시퀀스 x_{1:T}입니다. 훈련 방법은 알고리즘 1에 나와 있습니다. 실행 프로세스의 각 단계 t에는 과거 노이즈 없는 토큰 x_{1:t-1}을 요약하는 숨겨진 상태 z_{t-1}이 있습니다.이 숨겨진 상태를 기반으로 계획 은 알고리즘 2에 따라 샘플링됩니다. 여기서 에는 예측된 행동, 보상 및 관찰이 포함됩니다. H는 모델 예측 제어의 미래 예측과 유사한 전방 관찰 창입니다. 계획된 조치를 취한 후 환경은 보상과 다음 관찰, 그리고 다음 토큰을 얻습니다. 은닉 상태는 사후 p_θ(z_t|z_{t−1}, x_t, 0)에 따라 업데이트될 수 있습니다. 프레임워크는 전략 및 계획자로 사용될 수 있으며 그 장점은 다음과 같습니다.
- 달성 가능 몬테 미래의 불확실성을 달성하기 위한 MCTG(Carlo Tree Guidance)
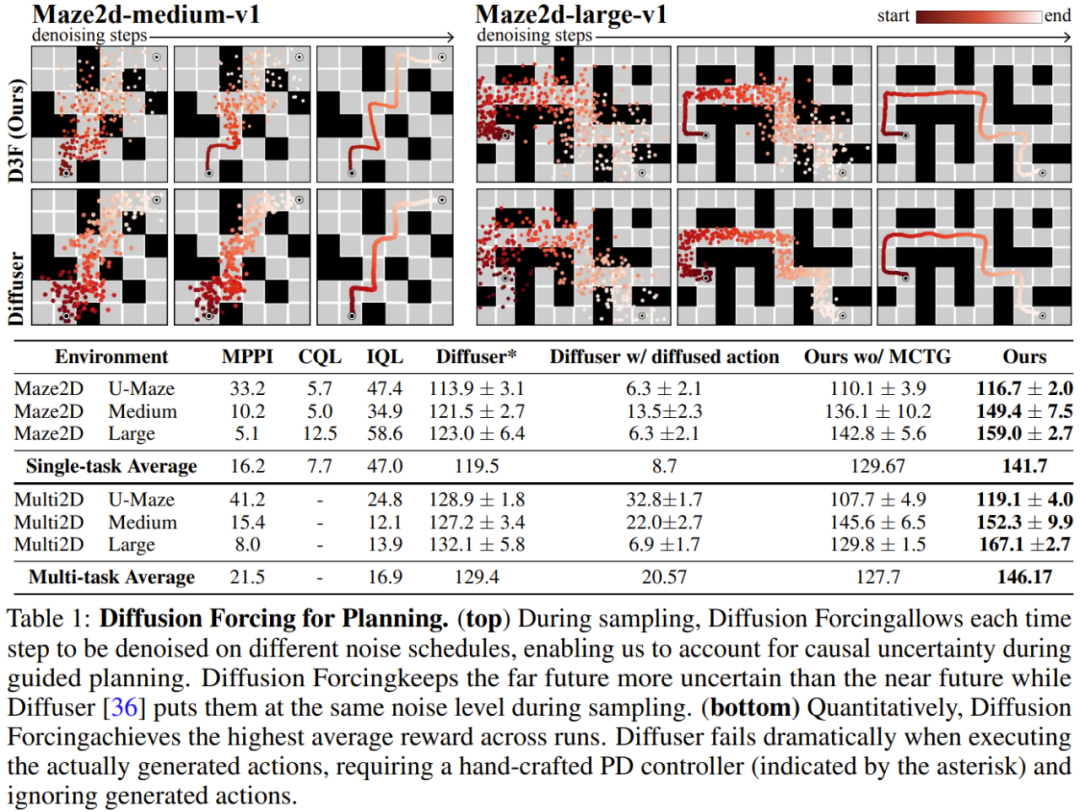
팀은 비디오 및 시계열 예측, 계획 및 모방 학습을 포함하는 생성 시퀀스 모델로서 확산강제의 장점을 평가했으며, 다른 응용 프로그램. 비디오 예측: 일관되고 안정적인 시퀀스 생성 및 무한 확장 비디오 생성 모델링 작업을 위해 Minecraft 게임 비디오 및 DMLab 탐색 수행을 기반으로 인과 확산 적용을 위한 컨벌루션 RNN을 훈련했습니다. 그림 3은 기준선 대비 확산강제력의 정성적 결과를 보여줍니다. 훈련 범위를 넘어서도 확산 강제가 안정적으로 전개될 수 있는 반면 교사 강제 및 전체 시퀀스 확산 벤치마크는 빠르게 분기되는 것을 볼 수 있습니다. 확산 계획: MCTG, 원인 불확실성, 유연한 범위 제어확산 강제 능력은 의사 결정에 고유한 이점을 가져올 수 있습니다. 팀은 표준 오프라인 강화 학습 프레임워크인 D4RL을 사용하여 새로 제안된 의사 결정 프레임워크를 평가했습니다. 표 1은 정성적, 정량적 평가 결과를 보여준다. 볼 수 있듯이 Diffusion Enforcement는 6개 환경 모두에서 Diffuser 및 모든 기준보다 성능이 뛰어납니다. 팀은 샘플링 방식을 수정하는 것만으로 훈련 시간에 관찰된 시퀀스의 하위 시퀀스를 유연하게 결합할 수 있음을 발견했습니다. 그들은 2D 궤적 데이터세트를 사용하여 실험을 수행했습니다. 정사각형 평면에서 모든 궤적은 한 모서리에서 시작하여 반대쪽 모서리에서 끝나 일종의 십자 모양을 형성합니다. 위의 그림 1과 같이 조합 동작이 필요하지 않은 경우 DF는 완전한 메모리를 유지하고 교차 분포를 복제할 수 있습니다. 조합이 필요한 경우 모델을 사용하여 MPC를 사용하여 메모리 없이 더 짧은 계획을 생성할 수 있으므로 이 십자가의 하위 궤적을 연결하여 V자형 궤적을 얻을 수 있습니다. 로봇: 장거리 모방 학습 및 강력한 시각적 모션 제어확산 강제는 실제 로봇의 시각적 모션 제어를 위한 새로운 기회도 제공합니다. 모방 학습은 전문가가 관찰한 행동의 매핑을 학습하는 일반적으로 사용되는 로봇 제어 기술입니다. 그러나 기억력 부족으로 인해 장거리 작업에 대한 모방 학습이 어려운 경우가 많습니다. DF는 이러한 단점을 완화할 수 있을 뿐만 아니라 모방 학습을 더욱 강력하게 만듭니다. 모방 학습에는 기억력을 활용하세요. Franka 로봇을 원격으로 제어하여 팀은 비디오 및 모션 데이터 세트를 수집했습니다. 그림 4에서 볼 수 있듯이 작업은 세 번째 위치를 사용하여 사과와 오렌지의 위치를 바꾸는 것입니다. 과일의 초기 위치는 무작위이므로 두 가지 가능한 목표 상태가 있습니다. 또한, 세 번째 위치에 과일이 있는 경우 현재 관찰에서 원하는 결과를 추론할 수 없습니다. 전략은 이동할 과일을 결정하기 위해 초기 구성을 기억해야 합니다.一般的に使用される動作クローン作成手法とは異なり、DF は記憶を独自の隠れた状態に自然に統合できます。 DF は 80% の成功率を達成したが、拡散戦略 (現時点で最良の記憶を持たない模倣学習アルゴリズム) は失敗したことが判明した。 さらに、DF はノイズにもより堅牢に対処し、ロボットの事前トレーニングを容易にすることもできます。 時系列予測: 拡散強制は優れた一般シーケンスモデルです多変量時系列予測タスクについては、チームの研究により、DFが以前の拡散モデルやTransformerベースのモデルと競合するのに十分であることが示されています匹敵します。 技術的な詳細と実験結果については、元の論文を参照してください。 Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn




 ) comme une sorte de masquage partiel, que l'on peut appeler "effectuer un masquage le long de l'axe du bruit
) comme une sorte de masquage partiel, que l'on peut appeler "effectuer un masquage le long de l'axe du bruit  est (probablement) du bruit blanc, et il n'y a plus d'informations sur les données d'origine. Comme le montre la figure 2, l'équipe a établi une perspective unifiée pour examiner les masques pour ces deux axes.
est (probablement) du bruit blanc, et il n'y a plus d'informations sur les données d'origine. Comme le montre la figure 2, l'équipe a établi une perspective unifiée pour examiner les masques pour ces deux axes. 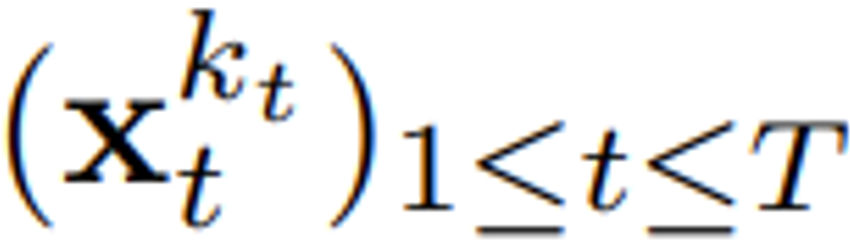 Cet article se concentre sur les données de séries chronologiques, ils instancient donc DF via une architecture causale, et obtiennent ainsi un forçage de diffusion causal (CDF). implémentation minimale obtenue en utilisant un réseau neuronal récurrent de base (RNN). Un RNN de poids θ maintient un état caché z_t qui est informé de l'influence des jetons passés. Il évoluera selon la dynamique
Cet article se concentre sur les données de séries chronologiques, ils instancient donc DF via une architecture causale, et obtiennent ainsi un forçage de diffusion causal (CDF). implémentation minimale obtenue en utilisant un réseau neuronal récurrent de base (RNN). Un RNN de poids θ maintient un état caché z_t qui est informé de l'influence des jetons passés. Il évoluera selon la dynamique 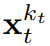 을 얻으면 숨겨진 상태가 Markovian 방식으로 업데이트됩니다.
을 얻으면 숨겨진 상태가 Markovian 방식으로 업데이트됩니다. 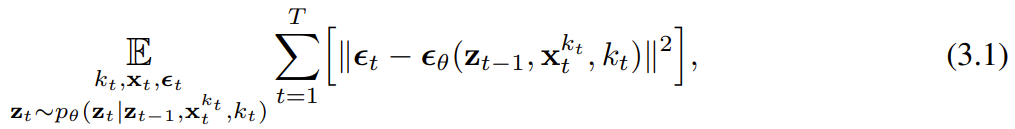

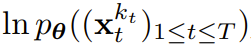 에 대한 증거 하한(ELBO)을 최적화하는 재가중화입니다. 여기서 기대 값은 잡음 수준에 대해 평균화되고
에 대한 증거 하한(ELBO)을 최적화하는 재가중화입니다. 여기서 기대 값은 잡음 수준에 대해 평균화되고 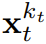 는 순방향 프로세스에 따라 잡음이 있습니다. 또한 적절한 조건에서 최적화(3.1)를 수행하면 모든 잡음 수준 시퀀스의 우도 하한을 동시에 최대화할 수도 있습니다.
는 순방향 프로세스에 따라 잡음이 있습니다. 또한 적절한 조건에서 최적화(3.1)를 수행하면 모든 잡음 수준 시퀀스의 우도 하한을 동시에 최대화할 수도 있습니다. 
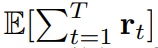 의 예상 누적 보상을 최대화하기 위해 정책 π(a_t|o_{1:t})를 훈련하는 것입니다. 여기서는 x_t = [a_t, r_t, o_{t+1}] 토큰이 할당됩니다. 궤도는 길이가 가변적일 수 있는 시퀀스 x_{1:T}입니다. 훈련 방법은 알고리즘 1에 나와 있습니다.
의 예상 누적 보상을 최대화하기 위해 정책 π(a_t|o_{1:t})를 훈련하는 것입니다. 여기서는 x_t = [a_t, r_t, o_{t+1}] 토큰이 할당됩니다. 궤도는 길이가 가변적일 수 있는 시퀀스 x_{1:T}입니다. 훈련 방법은 알고리즘 1에 나와 있습니다. 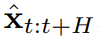 은 알고리즘 2에 따라 샘플링됩니다. 여기서
은 알고리즘 2에 따라 샘플링됩니다. 여기서 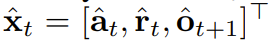 에는 예측된 행동, 보상 및 관찰이 포함됩니다. H는 모델 예측 제어의 미래 예측과 유사한 전방 관찰 창입니다. 계획된 조치를 취한 후 환경은 보상과 다음 관찰, 그리고 다음 토큰을 얻습니다. 은닉 상태는 사후 p_θ(z_t|z_{t−1}, x_t, 0)에 따라 업데이트될 수 있습니다.
에는 예측된 행동, 보상 및 관찰이 포함됩니다. H는 모델 예측 제어의 미래 예측과 유사한 전방 관찰 창입니다. 계획된 조치를 취한 후 환경은 보상과 다음 관찰, 그리고 다음 토큰을 얻습니다. 은닉 상태는 사후 p_θ(z_t|z_{t−1}, x_t, 0)에 따라 업데이트될 수 있습니다.