
Maison >Périphériques technologiques >IA >Lors de la conférence sur la robotique RSS 2024, la recherche chinoise sur les robots humanoïdes a remporté le prix du meilleur article
Lors de la conférence sur la robotique RSS 2024, la recherche chinoise sur les robots humanoïdes a remporté le prix du meilleur article

- 王林original
- 2024-07-22 14:56:45713parcourir
Récemment, RSS (Robotics: Science and Systems) 2024, une célèbre conférence dans le domaine de la robotique, s'est conclue avec succès à l'Université de technologie de Delft aux Pays-Bas.
Bien que l'ampleur des conférences ne soit pas comparable aux grandes conférences sur l'IA telles que NeurIPS et CVPR, RSS a fait de grands progrès ces dernières années, avec près de 900 participants cette année. 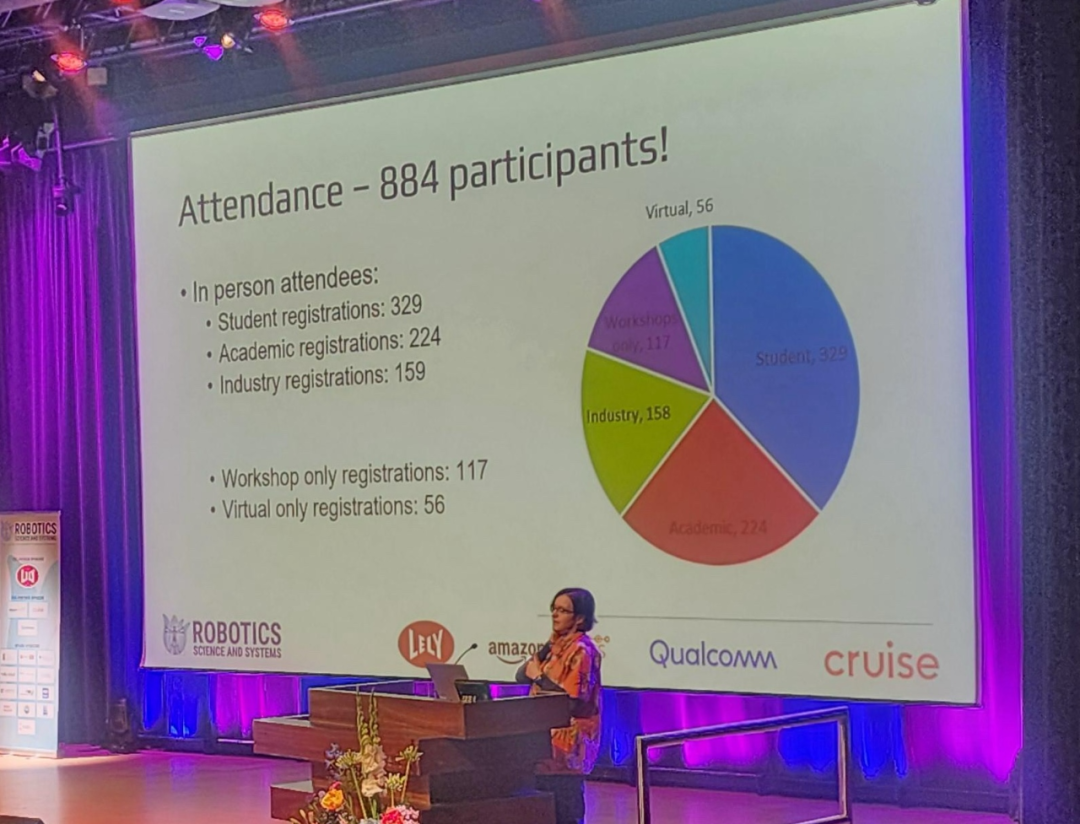
Le dernier jour de la conférence, plusieurs prix tels que le meilleur article, le meilleur article étudiant, le meilleur article système et le meilleur article de démonstration ont été annoncés en même temps. En outre, la conférence a également sélectionné le « Early Career Spotlight Award » et le « Time Test Award ».
Il convient de noter que la recherche sur les robots humanoïdes de l'Université Tsinghua et de Beijing Xingdong Era Technology Co., Ltd. a remporté le prix du meilleur article, et l'érudit chinois Ji Zhang a remporté ce prix du test du temps.
Voici les informations sur les articles gagnants :
Prix du meilleur article de démonstration

Titre de l'article : Démonstration de CropFollow++ : Robust Under-Canopy Navigation with Keypoints
Auteur : Arun Narenthiran Siv Akumar, Mateus Valverde Gasparino, Michael McGuire, Vitor Akihiro Hisano Higuti, M. Ugur Akcal, Girish Chowdhary
Institution : UIUC, Earth Sense
Lien papier : https://enriquecoronadozu.github.io/rssproceedings2024/rss20/ p023.pdf
Dans cet article, les chercheurs proposent un système de navigation visuelle robuste basé sur l'expérience pour les robots agricoles de sous-couverte utilisant des points clés sémantiques.
La navigation autonome sous le couvert des cultures est difficile en raison du faible espacement des rangées de cultures (∼ 0,75 mètres), de la précision RTK-GPS réduite en raison d'erreurs de trajets multiples et du bruit des mesures lidar causé par un encombrement excessif. Un travail antérieur appelé CropFollow a relevé ces défis en proposant un système de navigation visuelle perceptuelle de bout en bout basé sur l'apprentissage. Cependant, cette approche souffre des limites suivantes : manque de représentations interprétables et manque de sensibilité aux prédictions aberrantes lors de l'occlusion en raison d'un manque de confiance.
Le système CropFollow++ de cet article présente une architecture de perception modulaire et une représentation sémantique apprise des points clés. Comparé à CropFollow, CropFollow++ est plus modulaire, plus interprétable et offre une plus grande confiance dans la détection des occlusions. CropFollow++ a obtenu des résultats nettement meilleurs que CropFollow lors d'essais sur le terrain difficiles de fin de saison, chacun s'étendant sur 1,9 kilomètres et nécessitant 13 contre 33 collisions. Nous discutons également des principales leçons tirées d'un déploiement à grande échelle de CropFollow++ dans plusieurs robots de culture de couverture de sous-culture (longueur totale 25 km) dans diverses conditions de terrain.

Titre de l'article : Demonstrating Agile Flight from Pixels without State Estimation
Auteurs : smail Geles, Leonard Bauersfeld, Angel Romero, Jiaxu Xing, Davide Scaramuzza
Lien de l'article : https://enriquecoronadozu .github.io/rssproceedings2024/rss20/p082.pdf
Les drones quadricoptères sont l'un des robots volants les plus agiles. Bien que certaines recherches récentes aient fait progresser le contrôle basé sur l’apprentissage et la vision par ordinateur, les drones autonomes reposent toujours sur une estimation explicite de l’état. Les pilotes humains, quant à eux, ne peuvent compter que sur les flux vidéo à la première personne fournis par la caméra embarquée du drone pour pousser la plateforme dans ses retranchements et voler de manière stable dans des environnements invisibles.
Cet article présente le premier système de drone quadricoptère basé sur la vision qui peut naviguer de manière autonome à travers une série de portes à grande vitesse tout en mappant les pixels directement pour contrôler les commandes. Comme les pilotes de drones professionnels, le système n’utilise pas d’estimations d’état explicites, mais utilise les mêmes commandes de contrôle que les humains (poussée collective et vitesse du corps). Les chercheurs ont démontré un vol agile à des vitesses allant jusqu'à 40 km/h et des accélérations jusqu'à 2 g. Ceci est réalisé en formant des politiques basées sur une vision grâce à l’apprentissage par renforcement (RL). Le recours à l’Acteur-Critique asymétrique permet d’obtenir des informations privilégiées et de faciliter la formation. Pour surmonter la complexité informatique lors de la formation RL basée sur des images, nous utilisons les bords intérieurs des portes comme abstractions de capteurs. Cette représentation simple mais puissante, pertinente pour une tâche, peut être simulée sans rendu d'images pendant la formation. Au cours du processus de déploiement, les chercheurs ont utilisé un détecteur de porte basé sur Swin Transformer.
La méthode décrite dans cet article peut utiliser du matériel standard disponible dans le commerce pour réaliser un vol agile et autonome. Même si la démonstration s'est concentrée sur les courses de drones, l'approche a des implications au-delà de la compétition et peut servir de base à de futures recherches sur des applications réelles dans des environnements structurés.
Prix du meilleur article sur le système

Titre de l'article : Interface de manipulation universelle : enseignement de robots dans la nature sans robots dans la nature
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, Shuran Chanson
Institutions : Stanford University, Columbia University, Toyota Research Institute
Lien papier : https://arxiv.org/pdf/2402.10329
Cet article présente l'interface de manipulation universelle (UMI), une Un cadre de collecte de données et d'apprentissage des politiques qui transfère directement les compétences démontrées par les humains dans la nature vers des politiques de robots déployables. UMI utilise une pince portative et une conception d'interface soignée pour fournir une collecte de données portable, peu coûteuse et riche en informations pour des démonstrations difficiles de manipulation dynamique et à double bras. Pour faciliter l'apprentissage des politiques déployables, UMI utilise une interface de politique soigneusement conçue avec des capacités de correspondance de délai d'inférence et de représentation d'action de trajectoire relative. La politique apprise est indépendante du matériel et peut être déployée sur plusieurs plates-formes robotiques. Grâce à ces capacités, le cadre UMI débloque de nouvelles capacités de manipulation robotique, permettant la généralisation sans tir de comportements dynamiques, à double bras, précis et à long champ de vision en modifiant simplement les données d'entraînement pour chaque tâche. Les chercheurs ont démontré la polyvalence et l'efficacité de l'UMI grâce à des expériences complètes dans le monde réel au cours desquelles les politiques apprises avec l'UMI Zero RF se sont généralisées à de nouveaux environnements et objets lorsqu'elles étaient formées sur différentes démonstrations humaines.

Titre de l'article : Khronos : Une approche unifiée pour le SLAM métrique-sémantique spatio-temporel dans des environnements dynamiques
Auteurs : Lukas Schmid, Marcus Abate, Yun Chang, Luca Carlone
Lien de l'article : https://arxiv.org/pdf/2402.13817
La perception et la compréhension d'environnements hautement dynamiques et changeants sont des capacités clés pour l'autonomie des robots. Bien que des progrès considérables aient été réalisés dans le développement de méthodes SLAM dynamiques capables d'estimer avec précision les poses des robots, une attention insuffisante a été accordée à la construction de représentations spatio-temporelles denses des environnements des robots. Une compréhension détaillée du scénario et de son évolution dans le temps est cruciale pour l'autonomie à long terme du robot, et est également cruciale pour les tâches qui nécessitent un raisonnement à long terme, comme opérer efficacement dans un environnement partagé avec des humains et d'autres agents et donc soumis à des contraintes à court et à long terme. L’impact des changements dynamiques.
Pour relever ce défi, cette étude définit le problème spatio-temporel métrique-sémantique SLAM (SMS) et propose un cadre pour décomposer et résoudre efficacement le problème. Il est montré que la factorisation proposée suggère une organisation naturelle des systèmes de perception spatio-temporelle, où un processus rapide suit la dynamique à court terme dans la fenêtre temporelle active, tandis qu'un autre processus lent exprime les réponses aux changements à long terme dans l'environnement à l'aide d'un graphe factoriel. Faire des inférences. Les chercheurs fournissent Khronos, une méthode efficace de connaissance spatio-temporelle, et démontrent qu'elle unifie les explications existantes de la dynamique à court et à long terme et qu'elle est capable de construire des cartes spatio-temporelles denses en temps réel.
La simulation et les résultats réels fournis dans l'article montrent que la carte spatio-temporelle construite par Khronos peut refléter avec précision les changements temporels de la scène tridimensionnelle, et Khronos surpasse la ligne de base dans plusieurs indicateurs. "Prix du meilleur article étudiant"
Lien papier : https://arxiv.org/pdf/2405.08731
 Actuellement, les recherches sur les robots effectuant des actions non agrippantes se concentrent principalement sur le contact statique pour éviter les problèmes pouvant être causés par le glissement. Cependant, si le problème du « glissement des mains » est fondamentalement éliminé, c'est-à-dire que le glissement lors du contact peut être contrôlé, cela ouvrira de nouveaux domaines d'actions que le robot peut effectuer.
Actuellement, les recherches sur les robots effectuant des actions non agrippantes se concentrent principalement sur le contact statique pour éviter les problèmes pouvant être causés par le glissement. Cependant, si le problème du « glissement des mains » est fondamentalement éliminé, c'est-à-dire que le glissement lors du contact peut être contrôlé, cela ouvrira de nouveaux domaines d'actions que le robot peut effectuer.
- Dans cet article, les chercheurs proposent une tâche d'opération dynamique sans préhension exigeante qui nécessite une prise en compte approfondie de divers modes de contact mixtes. Les chercheurs ont utilisé la dernière technologie de contrôle prédictif (MPC) de modèle de contact implicite pour aider le robot à effectuer une planification multimodale pour accomplir diverses tâches. L'article explore en détail comment intégrer des modèles simplifiés pour MPC avec des contrôleurs de suivi de bas niveau et comment adapter le contact implicite MPC aux besoins des tâches dynamiques.
- Bien que les modèles de friction et de contact rigide soient connus pour être souvent imprécis, l'approche de cet article est capable de répondre avec sensibilité à ces inexactitudes tout en accomplissant la tâche rapidement. De plus, les chercheurs n’ont pas utilisé d’outils auxiliaires courants, tels que des trajectoires de référence ou des primitives de mouvement, pour aider le robot à accomplir la tâche, ce qui souligne encore la polyvalence de la méthode. C'est la première fois que la technologie MPC à contact implicite est appliquée à des tâches de manipulation dynamique dans un espace tridimensionnel.

Papiertitel: Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion
Autoren: Tairan He, Chong Zhang, Wenli Xiao, Guanqi He, Changliu Liu, Guanya Shi
-
Institution: CMU, ETH Zürich, Schweiz
Link zum Papier: https://arxiv.org/pdf/2401.17583
Wenn vierbeinige Roboter durch unübersichtliche Umgebungen reisen, müssen sie sowohl Flexibilität als auch Sicherheit haben. Sie müssen in der Lage sein, Aufgaben schnell zu erledigen und dabei Kollisionen mit Personen oder Hindernissen zu vermeiden. Die bestehende Forschung konzentriert sich jedoch oft nur auf einen Aspekt: Entweder wird aus Sicherheitsgründen eine konservative Steuerung mit einer Geschwindigkeit von nicht mehr als 1,0 m/s entworfen, oder man strebt nach Flexibilität, ignoriert aber das Problem potenziell tödlicher Kollisionen.
Dieses Papier schlägt ein Kontrollrahmenwerk namens „Agile and Secure“ vor. Dieser Rahmen ermöglicht es vierbeinigen Robotern, Hindernissen und Menschen sicher auszuweichen und gleichzeitig ihre Flexibilität zu bewahren, wodurch ein kollisionsfreies Gehen erreicht wird.
ABS umfasst zwei Sätze von Strategien: Eine besteht darin, dem Roboter beizubringen, flexibel und flink zwischen Hindernissen zu wechseln, und die andere besteht darin, dem Roboter beizubringen, wie er sich schnell erholen kann, wenn er auf ein Problem stößt, um sicherzustellen, dass der Roboter nicht herunterfällt oder etwas treffen. Die beiden Strategien ergänzen sich.
Im ABS-System wird der Strategiewechsel durch ein Kollisionsvermeidungs-Wertenetzwerk gesteuert, das auf der Theorie der lernenden Steuerung basiert. Dieses Netzwerk bestimmt nicht nur, wann die Strategie gewechselt werden muss, sondern stellt auch eine Zielfunktion für die Wiederherstellungsstrategie bereit und stellt sicher, dass der Roboter im geschlossenen Regelsystem immer sicher bleibt. Auf diese Weise können Roboter flexibel auf verschiedene Situationen in komplexen Umgebungen reagieren.
Um diese Strategien und Netzwerke zu trainieren, haben Forscher umfangreiche Schulungen in Simulationsumgebungen durchgeführt, darunter agile Strategien, Wertnetzwerke zur Kollisionsvermeidung, Wiederherstellungsstrategien und Netzwerke zur Darstellung externer Wahrnehmung usw. Diese trainierten Module können direkt auf die reale Welt angewendet werden. Dank der eigenen Wahrnehmungs- und Rechenfähigkeiten des Roboters kann er schnell und sicher handeln, egal ob er sich drinnen oder in einem begrenzten Außenbereich befindet, egal ob er auf unbewegliche oder bewegliche Hindernisse trifft ABS-Rahmen.
Wenn Sie weitere Einzelheiten erfahren möchten, können Sie sich die vorherige Einleitung zu diesem Dokument auf dieser Website ansehen.


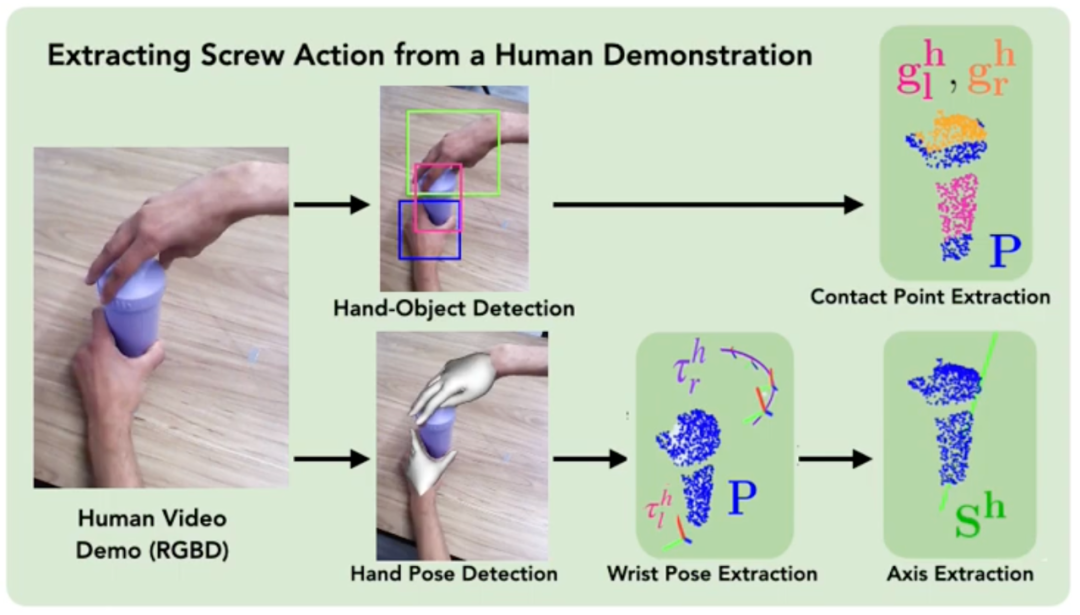
Papiertitel: ScrewMimic: Bimanual Imitation from Human Videos with Screw Space Projection
Autoren: Arpit Bahety, Priyanka Mandikal, Ben Abbatematteo, Roberto Martín-Martín
- Institution: Texas University of Austin
- Link zum Papier: https://arxiv.org/pdf/2405.03666
Methodendiagramm, die die humanoide Fortbewegung vorantreiben: Beherrschung herausfordernder Terrains mit demoinieren Weltrundmodell Learning Institution: Beijing Xingdong Era Technology Co., Ltd., Tsinghua-Universität
Pautan kertas: https://enriquecoronadozu.github.io/rssproceedings2024/rss20/p058.pdf
Teknologi semasa hanya boleh membenarkan robot humanoid berjalan di atas tanah rata dan rupa bumi yang begitu mudah. Walau bagaimanapun, masih sukar untuk membiarkan mereka bergerak bebas dalam persekitaran yang kompleks, seperti adegan luar yang sebenar. Dalam makalah ini, penyelidik mencadangkan kaedah baharu yang dipanggil denoising world model learning (DWL).
DWL ialah rangka kerja pembelajaran tetulang hujung ke hujung untuk kawalan pergerakan robot humanoid. Rangka kerja ini membolehkan robot menyesuaikan diri dengan pelbagai rupa bumi yang tidak rata dan mencabar, seperti salji, cerun dan tangga. Perlu dinyatakan bahawa robot ini hanya memerlukan satu proses pembelajaran dan boleh menangani pelbagai cabaran rupa bumi di dunia nyata tanpa latihan khas tambahan.

Penyelidikan ini telah disiapkan bersama oleh Beijing Xingdong Era Technology Co., Ltd. dan Universiti Tsinghua. Ditubuhkan pada 2023, Xingdong Era ialah sebuah syarikat teknologi yang diinkubasi oleh Institut Penyelidikan Silang Maklumat Universiti Tsinghua yang membangunkan teknologi dan produk robot humanoid dan kecerdasan yang terkandung Pengasasnya ialah Chen Jianyu, penolong profesor dan penyelia kedoktoran di Institut Penyelidikan Silang Maklumat Universiti Tsinghua. , memfokuskan pada Aplikasi canggih kecerdasan buatan am (AGI) komited untuk pembangunan robot humanoid sejagat yang boleh menyesuaikan diri dengan pelbagai bidang, pelbagai senario dan kecerdasan tinggi.

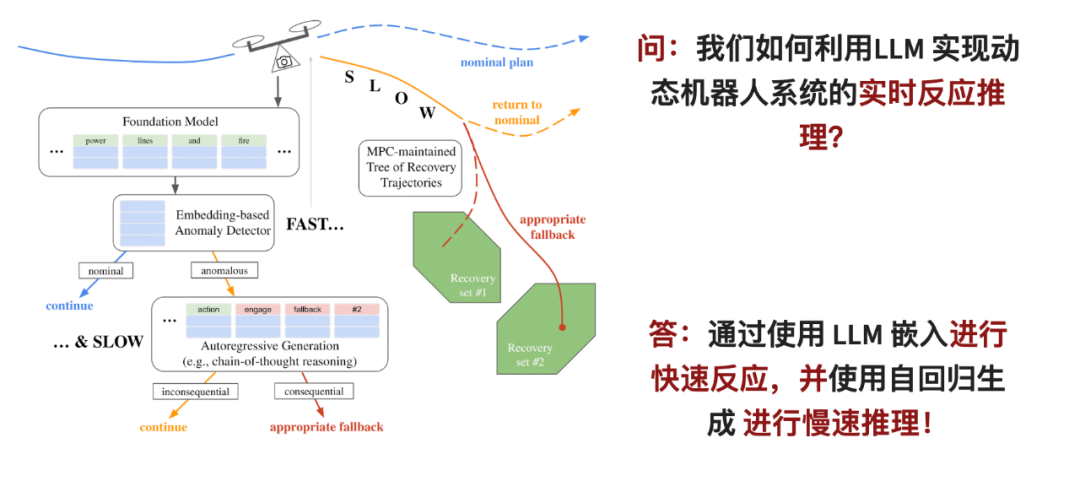
paper Tajuk: Pengesanan anomali masa nyata dan perancangan reaktif dengan model bahasa yang besar
Authors: Rohan Sinha, Amine Elhafsi, Christopher Agia, Matt Foutter, Edward Schmerling, Marco Pavone
institution :Stanford University
Pautan kertas: https://arxiv.org/pdf/2407.08735
Model Bahasa Besar (LLM), dengan keupayaan generalisasi tangkapan sifar, yang menjadikannya menjanjikan untuk robot pengesanan dan pengecualian kegagalan sistem di luar pengagihan. Walau bagaimanapun, untuk model bahasa berskala besar benar-benar berfungsi, dua masalah perlu diselesaikan: pertama, LLM memerlukan banyak sumber pengkomputeran untuk digunakan dalam talian, kedua, pertimbangan LLM perlu disepadukan ke dalam sistem kawalan keselamatan robot.
Dalam kertas kerja ini, para penyelidik mencadangkan rangka kerja penaakulan dua peringkat: untuk peringkat pertama, mereka mereka bentuk pengesan anomali pantas yang boleh menganalisis pemerhatian robot dengan cepat dalam ruang pemahaman LLM Jika masalah ditemui, seterusnya peringkat pemilihan alternatif telah dimasukkan. Pada peringkat ini, keupayaan inferens LLM digunakan untuk melakukan analisis yang lebih mendalam.
Peringkat yang dimasuki sepadan dengan titik cawangan dalam strategi kawalan ramalan model, yang boleh menjejak dan menilai pelan alternatif yang berbeza secara serentak untuk menyelesaikan masalah kependaman penaakulan perlahan. Sebaik sahaja sistem mengesan sebarang anomali atau masalah, strategi ini akan diaktifkan serta-merta untuk memastikan tindakan robot itu selamat.
Pengelas anomali pantas dalam kertas kerja ini mengatasi inferens autoregresif menggunakan model GPT terkini, walaupun menggunakan model bahasa yang agak kecil. Ini membolehkan monitor masa nyata yang dicadangkan dalam kertas kerja untuk meningkatkan kebolehpercayaan robot dinamik di bawah sumber dan masa yang terhad, seperti dalam quadcopter dan kereta tanpa pemandu. . Switzerland I DIAP Institute, Lausanne, Institut Teknologi Persekutuan Switzerland, Universiti Zhejiang

- Medan jarak bertanda (SDF) ialah perwakilan bentuk tersirat yang popular dalam robotik, yang menyediakan maklumat Geometrik tentang objek dan halangan dan boleh digabungkan dengan mudah dengan kawalan, pengoptimuman dan teknik pembelajaran. SDF biasanya digunakan untuk mewakili jarak dalam ruang tugas, yang sepadan dengan konsep jarak yang dirasakan oleh manusia dalam dunia 3D.
-
Dalam bidang robot, SDF sering digunakan untuk mewakili sudut setiap sendi robot. Pengkaji biasanya mengetahui kawasan mana dalam ruang sudut sendi robot yang selamat, iaitu sendi robot boleh berputar ke kawasan ini tanpa perlanggaran. Walau bagaimanapun, mereka tidak sering menyatakan kawasan selamat ini dari segi medan jarak.
Dalam kertas kerja ini, penyelidik mencadangkan potensi menggunakan SDF untuk mengoptimumkan ruang konfigurasi robot, yang mereka panggil medan jarak ruang konfigurasi (pendek kata CDF). Sama seperti menggunakan SDF, CDF menyediakan carian jarak sudut sendi yang cekap dan akses terus kepada derivatif (halaju sudut bersama). Biasanya, perancangan robot dibahagikan kepada dua langkah: pertama, lihat sejauh mana tindakan dari sasaran dalam ruang tugas, dan kemudian gunakan kinematik songsang untuk mengira bagaimana sendi berputar. Tetapi CDF menggabungkan kedua-dua langkah ini ke dalam satu langkah dan menyelesaikan masalah secara langsung dalam ruang bersama robot, yang lebih mudah dan lebih cekap. Dalam kertas itu, para penyelidik mencadangkan algoritma yang cekap untuk mengira dan menggabungkan CDF, yang boleh diperluaskan kepada mana-mana senario.
Mereka juga mencadangkan perwakilan CDF neural yang sepadan menggunakan perceptron berbilang lapisan (MLP) untuk mendapatkan perwakilan yang padat dan berterusan, meningkatkan kecekapan pengiraan. Makalah ini menyediakan beberapa contoh khusus untuk menunjukkan kesan CDF, seperti membiarkan robot mengelakkan halangan pada pesawat, dan membiarkan robot 7 paksi Franka menyelesaikan beberapa tugas perancangan tindakan. Contoh-contoh ini menggambarkan keberkesanan CDF.机 Lengan robotik kaedah CDF diperbuat daripada tugas kotak

SPOTLIGHT profesional awal Persidangan juga memilih Anugerah Lampu Tumpuan Awal Pemenang ini adalah pelayaran robot persekitaran yang tidak diketahui.
Stefan Leutenegger ialah penolong profesor (tenure-track) di Sekolah Pengkomputeran, Maklumat dan Teknologi (CIT) di Universiti Teknikal Munich (TUM), dan bekerja dengan Institut Robotik dan Perisikan Mesin Munich ( MIRMI) dan Institut Sains Data Munich (MDSI) dikaitkan dengan Pusat Pembelajaran Mesin Munich (MCML) dan merupakan ahli Makmal Robotik Dyson. Makmal Robot Pintar (SRL) yang dipimpinnya dikhususkan untuk penyelidikan di persimpangan persepsi, robot mudah alih, dron dan pembelajaran mesin. Selain itu, Stefan ialah pensyarah pelawat di Jabatan Pengkomputeran di Imperial College London.
Beliau mengasaskan bersama SLAMcore, sebuah syarikat spin-out yang menyasarkan pengkomersilan penyelesaian kedudukan dan pemetaan untuk robot dan dron. Stefan menerima ijazah sarjana muda dan sarjana dalam kejuruteraan mekanikal dari ETH Zurich dan menerima PhD pada tahun 2014 dengan tesis mengenai "Pesawat Suria Tanpa Pemandu: Reka Bentuk dan Algoritma untuk Operasi Autonomi yang Cekap dan Teguh".
RSS Anugerah Ujian Masa diberikan kepada kertas kerja paling berpengaruh yang diterbitkan dalam RSS (dan mungkin versi jurnalnya) sekurang-kurangnya sepuluh tahun yang lalu. Pengaruh boleh difahami dari tiga aspek: contohnya, mengubah cara orang berfikir tentang masalah atau reka bentuk robot, membawa masalah baharu kepada perhatian masyarakat, atau mencipta kaedah baharu reka bentuk robot atau penyelesaian masalah. Melalui anugerah ini, RSS berharap dapat merangsang perbincangan mengenai pembangunan jangka panjang bidang ini. Anugerah Ujian Masa tahun ini diberikan kepada Ji Zhang dan Sanjiv Singh untuk penyelidikan mereka "LOAM: Ranging LiDAR dan Pemetaan Masa Nyata." Anugerah Ujian Masa
Anugerah Ujian MasaPautan kertas: https://www.ri.cmu.edu/pub_files/2014/7/Ji_LidarMapping_RSS2014_v8.pdf
Kertas sepuluh tahun ini mencadangkan kaedah untuk menggunakan pergerakan 6-DOF kaedah masa nyata untuk odometri dan pemetaan data odometri lidar paksi. Sebab masalah ini sukar diselesaikan ialah data julat diterima pada masa yang berbeza, dan ralat dalam anggaran pergerakan boleh menyebabkan salah pendaftaran awan titik yang terhasil. Peta 3D yang koheren boleh dibina dengan kaedah kelompok luar talian, selalunya menggunakan penutupan gelung untuk membetulkan hanyut dari semasa ke semasa. Kaedah dalam kertas ini tidak memerlukan julat ketepatan tinggi atau ukuran inersia, dan boleh mencapai drift rendah dan kerumitan pengiraan rendah.
Kunci untuk mencapai tahap prestasi ini adalah dengan membahagikan masalah kedudukan dan pemetaan serentak yang kompleks kepada dua algoritma untuk mengoptimumkan sejumlah besar pembolehubah secara serentak. Satu algoritma berprestasi julat pada frekuensi tinggi tetapi ketepatan rendah untuk menganggarkan kelajuan lidar; algoritma lain beroperasi pada urutan magnitud frekuensi yang lebih rendah untuk padanan halus dan pendaftaran awan titik. Gabungan kedua-dua algoritma ini membolehkan kaedah melukis dalam masa nyata. Para penyelidik menilainya melalui eksperimen yang meluas dan penanda aras kelajuan KITTI, dan keputusan menunjukkan bahawa kaedah itu boleh mencapai tahap ketepatan SOTA kaedah kelompok luar talian.
Untuk maklumat lanjut persidangan dan anugerah, sila rujuk laman web rasmi: https://roboticsconference.org/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI