
Maison >développement back-end >Tutoriel Python >Pile de données déclarative multi-moteurs avec Ibis
Pile de données déclarative multi-moteurs avec Ibis

- 王林original
- 2024-07-19 03:34:101627parcourir
TL;DR
Je suis tombé récemment sur la Ju Data Engineering Newsletter de Julien Hurault sur la stack de données multi-moteurs. L'idée est simple ; nous aimerions porter facilement notre code sur n'importe quel backend tout en conservant la flexibilité nécessaire pour développer notre pipeline à mesure que de nouveaux backends et fonctionnalités sont développés. Cela implique au moins les flux de travail de haut niveau suivants :
- Déchargement d'une partie d'une requête SQL vers des moteurs sans serveur avec DuckDB, polars, DataFusion, chdb etc.
- Pipeline de taille adaptée pour divers scénarios de développement et de déploiement. Par exemple, les développeurs peuvent travailler localement et passer en production en toute confiance.
- Appliquez automatiquement les optimisations de style de base de données à vos pipelines.
Dans cet article, nous expliquons comment nous pouvons implémenter le pipeline multimoteur à partir d'un langage de programmation ; Au lieu de SQL, nous proposons d'utiliser une API Dataframe qui peut être utilisée à la fois pour des cas d'utilisation interactifs et par lots. Plus précisément, nous montrons comment diviser notre pipeline en morceaux plus petits et les exécuter sur DuckDB, pandas et Snowflake. Nous discutons également des avantages d'une pile de données multimoteurs et mettons en évidence les tendances émergentes dans le domaine.
Le code implémenté dans cet article est disponible sur GitHub^[Afin d'essayer rapidement le repo, je fournis également un nix flake]. L'ouvrage de référence dans la newsletter avec mise en œuvre originale est ici.
Aperçu
Le pipeline de pile de données multimoteur fonctionne comme suit : certaines données atterrissent dans un compartiment S3, sont prétraitées pour supprimer tous les doublons, puis chargées dans une table Snowflake, où elles sont ensuite transformées avec des fonctions spécifiques à ML ou Snowflake^[Veuillez noter nous n'entrons pas dans la mise en œuvre des types de choses qui pourraient être possibles dans Snowflake et supposons que c'est une exigence pour le flux de travail]. Le pipeline prend les commandes sous forme de fichiers parquet qui sont enregistrés dans l'emplacement d'arrivée, sont prétraités puis stockés à l'emplacement intermédiaire dans un compartiment S3. Les données intermédiaires sont ensuite chargées dans Snowflake pour y connecter les outils BI en aval. Le pipeline est lié par SQL dbt avec un modèle pour chaque backend et la newsletter choisit Dagster comme outil d'orchestration.
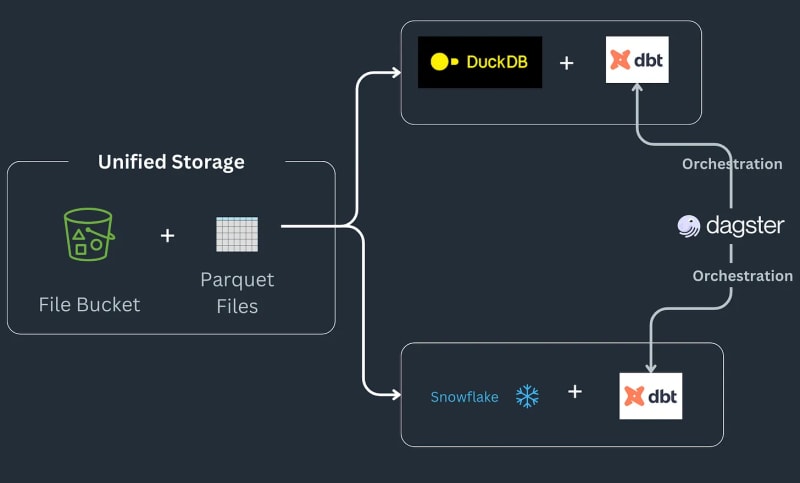
Aujourd'hui, nous allons découvrir comment convertir notre code pandas en expressions Ibis, en reproduisant l'exemple complet de l'exemple de pile multi-moteurs de Julien Hurault 1. Au lieu d'utiliser des modèles dbt et SQL, nous utilisons ibis et du Python pour compiler et orchestrer les moteurs SQL à partir d'un shell. En réécrivant notre code sous forme d'expressions Ibis, nous pouvons construire de manière déclarative nos pipelines de données avec une exécution différée. De plus, Ibis prend en charge plus de 20 backends, nous pouvons donc écrire du code une seule fois et porter notre ibis.exprs sur plusieurs backends. Pour simplifier encore, nous laissons au lecteur la planification et l'orchestration des tâches2 fournies par Dagster.
Concept de base de la pile de données multimoteur
Voici les concepts fondamentaux de la pile de données multimoteurs tels que décrits dans la newsletter de Julien :
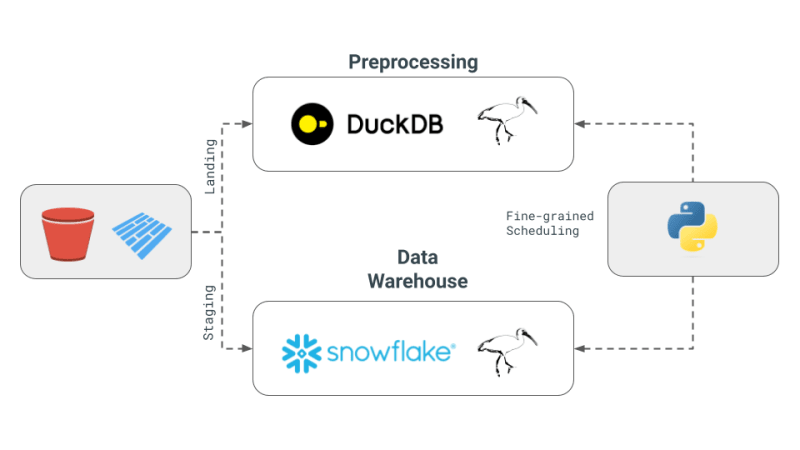
- Pile de données multi-moteurs : Le concept consiste à combiner différents moteurs de données tels que Snowflake, Spark, DuckDB et BigQuery. Cette approche vise à réduire les coûts, à limiter la dépendance vis-à-vis du fournisseur et à accroître la flexibilité. Julien mentionne que pour certaines requêtes de benchmark, l'utilisation de DuckDB pourrait permettre une réduction significative des coûts par rapport à Snowflake.
- Développement d'une couche de requête multi-moteur : La newsletter met en évidence les avancées technologiques qui permettent aux équipes de données de transpiler leur code SQL ou Dataframe d'un moteur à un autre de manière transparente. Ce développement est crucial pour maintenir l’efficacité des différents moteurs.
- Utilisation d'Apache Iceberg et alternatives : Bien qu'Apache Iceberg soit considéré comme une couche de stockage unifiée potentielle, son intégration n'est pas encore mature pour être utilisée dans un projet dbt. Au lieu de cela, Julien a choisi d'utiliser les fichiers Parquet stockés dans S3, accessibles à la fois par DuckDB et Snowflake, dans sa preuve de concept (PoC).
- Orchestration et moteurs dans PoC : Pour le projet, Julien a utilisé Dagster comme orchestrateur, ce qui simplifie la planification des tâches des différents moteurs au sein d'un projet dbt. Les moteurs combinés dans ce PoC étaient DuckDB et Snowflake.
Pourquoi DataFrames et Ibis ?
Bien que le pipeline ci-dessus soit intéressant pour ETL et ELT, nous souhaitons parfois la puissance d'un langage de programmation complet au lieu d'un langage de requête comme SQL, par exemple. débogage, tests, UDF complexes, etc. Pour l'exploration scientifique, l'informatique interactive est essentielle car les data scientists doivent rapidement itérer sur leur code, visualiser les résultats et prendre des décisions basées sur les données.
Les DataFrames sont une telle structure de données : les DataFrames sont utilisés pour traiter des données ordonnées et y appliquer des opérations de calcul de manière interactive. Ils offrent la flexibilité nécessaire pour pouvoir traiter des données volumineuses avec des opérations de style SQL, mais fournissent également un contrôle de niveau inférieur pour modifier les modifications au niveau des cellules comme dans les feuilles Excel. En général, on s'attend à ce que toutes les données soient traitées en mémoire et tiennent généralement en mémoire. De plus, les DataFrames facilitent les allers-retours entre les modes différé/batch et interactif.
DataFrames excellent^[sans jeu de mots] pour permettre aux gens d'appliquer des fonctions définies par l'utilisateur et libère un utilisateur des limitations de SQL, c'est-à-dire que vous pouvez désormais réutiliser le code, tester vos opérations, étendre facilement la machinerie relationnelle pour des opérations complexes. Les DataFrames facilitent également le passage rapide de la représentation tabulaire des données aux tableaux et tenseurs attendus par les bibliothèques de Machine Learning.
Bases de données spécialisées et en cours, par ex. DuckDB pour OLAP3, brouille la frontière entre une base de données distante lourde comme Snowflake et une bibliothèque ergonomique comme pandas. Nous pensons qu'il s'agit d'une opportunité pour permettre aux DataFrames de traiter des données plus volumineuses que la mémoire tout en conservant les attentes d'interactivité et la sensation de développement d'un shell Python local, ce qui donne l'impression que les données plus volumineuses que la mémoire sont petites.
Plongée technique approfondie
Notre mise en œuvre se concentre sur les 4 concepts présentés précédemment :
- Pile de données multi-moteurs : nous utiliserons DuckDB, pandas et Snowflake comme moteurs.
- Couche de requête Cross-Engine : Nous utiliserons Ibis pour écrire nos expressions et les compiler pour qu'elles s'exécutent sur DuckDB, pandas et Snowflake.
- Apache Iceberg et alternatives : Nous utiliserons les fichiers Parquet stockés localement comme couche de stockage en espérant qu'il sera trivial d'étendre à S3 à l'aide du package s3fs.
- Orchestration et moteurs dans PoC : nous nous concentrerons sur la planification fine des moteurs et laisserons l'orchestration au lecteur. La planification fine est plus alignée sur Ray, Dask, PySpark par rapport aux frameworks d'orchestration, par exemple. Dagster, Airflow etc.
Implémentation avec des pandas

pandas est la bibliothèque DataFrame par excellence et fournit peut-être le moyen le plus simple d'implémenter le flux de travail ci-dessus. Tout d'abord, nous générons des données aléatoires empruntant à la mise en œuvre dans la newsletter.
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
L'implémentation de pandas est de style impératif et est conçue pour que les données puissent tenir en mémoire. L'API pandas est difficile à compiler en SQL avec toutes ses nuances et se trouve en grande partie à sa place particulière, réunissant la visualisation Python, le traçage, l'apprentissage automatique, l'IA et les bibliothèques de traitement complexes.
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
Après la déduplication à l'aide des opérateurs pandas, nous sommes prêts à envoyer les données à Snowflake. Snowflake a une méthode appelée write_pandas qui s'avère utile pour notre cas d'utilisation.
Implémentation avec Ibis alias Ibisify
L'une des limites du panda est qu'il possède sa propre API qui ne correspond pas tout à fait à l'algèbre relationnelle. Ibis est une telle bibliothèque qui a été littéralement construite par des personnes qui ont construit des pandas pour fournir un système d'expressions sensé qui peut être mappé sur plusieurs backends SQL. Ibis s'inspire du package dplyr R pour créer un nouveau système d'expression qui peut facilement correspondre à l'algèbre relationnelle et ainsi compiler en SQL. Il est également de style déclaratif, nous permettant d'appliquer des optimisations de style de base de données sur le plan logique complet ou l'expression. Ibis est un composant clé pour permettre la composabilité, comme le souligne l'excellent codex composable.
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
L'expression Ibis s'imprime comme un plan qui s'apparente au plan logique traditionnel dans les bases de données. Un plan logique est un arbre d'opérateurs d'algèbre relationnelle qui décrit le calcul à effectuer. Ce plan est ensuite optimisé par l'optimiseur de requêtes et converti en un plan physique exécuté par l'exécuteur de requêtes. Les expressions Ibis sont similaires aux plans logiques dans la mesure où elles décrivent le calcul qui doit être effectué, mais elles ne sont pas exécutées immédiatement. Au lieu de cela, ils sont compilés en SQL et exécutés sur le backend en cas de besoin. Le plan logique est généralement à un niveau de granularité plus élevé qu'un DAG produit par un framework de planification de tâches comme Dask. En théorie, ce plan pourrait être compilé jusqu'au DAG de Dask.
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Multi-Engine Data Stack w/ Ibis
DuckDB + pandas + Snowflake
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
Acknowledgments
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
Resources
- The Road to Composable Data Systems
- The Composable Codex
- Apache Arrow
- Multi-Engine Data Stack Newsleter v0 v1
- Ibis, the portable dataframe library
- dbt Docs
- Dagster Docs
- LanceDB
- KuzuDB
- DuckDB
-
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
-
Orchestration Vs fine-grained scheduling: ↩
- The orchestration is left to the reader. The orchestration can be done using a tool like Dagster, Prefect, or Apache Airflow.
- The fine-grained scheduling can be done using a tool like Dask, Ray, or Spark.
-
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
-
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!