Les grands modèles linguistiques (LLM) sont de plus en plus utilisés dans divers domaines. Cependant, leur processus de génération de texte est coûteux et lent. Cette inefficacité est attribuée à l'algorithme de décodage autorégressif : la génération de chaque mot (jeton) nécessite un passage direct, nécessitant l'accès à un LLM comportant des milliards, voire des centaines de milliards de paramètres. Cela se traduit par un décodage autorégressif traditionnel plus lent. Récemment, l'Université de Waterloo, le Canadian Vector Institute, l'Université de Pékin et d'autres institutions ont publié conjointement EAGLE, qui vise à améliorer la vitesse d'inférence des grands modèles de langage tout en assurant une distribution cohérente du texte de sortie du modèle. Cette méthode extrapole le deuxième vecteur de fonctionnalités de haut niveau de LLM, ce qui peut améliorer considérablement l'efficacité de la génération. 
- Rapport technique : https://sites.google.com/view/eagle-llm
- Code (prend en charge Apache 2.0 commercial) : https://github.com/SafeAILab/EAGLE
EAGLE a les caractéristiques suivantes :
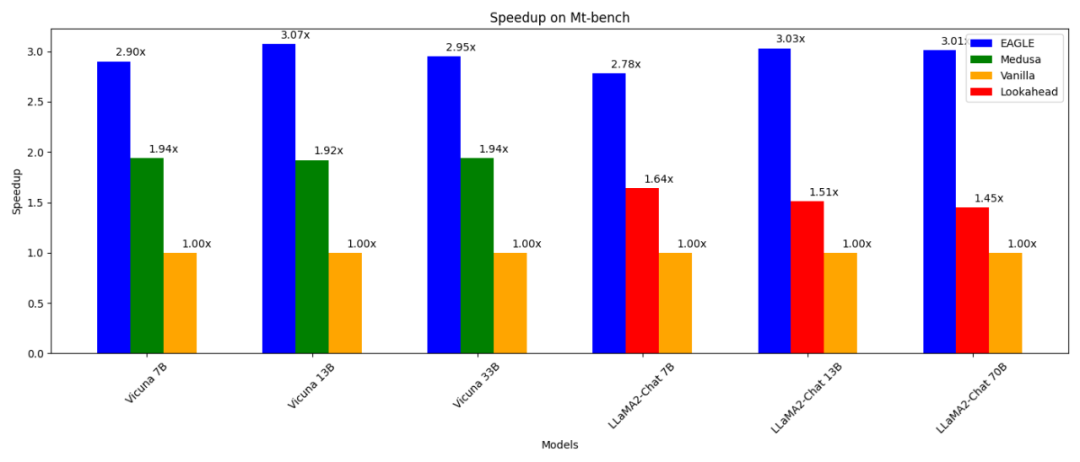
- 3 fois plus rapide que le décodage autorégressif ordinaire (13B) ; que Medusa Decode (13B) 1,6 fois plus rapide ;
- peut s'avérer cohérent avec le décodage ordinaire dans la distribution du texte généré
-
peut être entraîné (en 1 à 2 jours) et testé sur RTX 3090 ; peut être utilisé en conjonction avec d'autres technologies parallèles telles que vLLM, DeepSpeed, Mamba, FlashAttention, quantification et optimisation matérielle.
-
Une façon d'accélérer le décodage autorégressif est l'échantillonnage spéculatif. Cette technique utilise un modèle de brouillon plus petit pour deviner les prochains mots via une génération autorégressive standard. Le LLM original vérifie ensuite ces mots devinés en parallèle (nécessitant une seule passe avant pour la vérification). Si le projet de modèle prédit avec précision α mots, une seule passe avant du LLM d'origine peut générer α+1 mots.
Cette limitation a inspiré le développement d'EAGLE. EAGLE utilise les caractéristiques contextuelles extraites par le LLM d'origine (c'est-à-dire le vecteur de caractéristiques généré par la deuxième couche supérieure du modèle). EAGLE est construit sur les premiers principes suivants : Les séquences de vecteurs de caractéristiques sont compressibles, il est donc plus facile de prédire les vecteurs de caractéristiques suivants en fonction des vecteurs de caractéristiques précédents.
EAGLE entraîne un plug-in léger appelé tête de régression automatique qui, avec le mot couche d'intégration, prédit la prochaine fonctionnalité de la deuxième couche supérieure du modèle d'origine en fonction de la séquence de fonctionnalités actuelle. Le chef de classification gelé du LLM original est ensuite utilisé pour prédire le mot suivant. Les caractéristiques contiennent plus d'informations que les séquences de mots, ce qui rend la tâche de régression des caractéristiques beaucoup plus simple que la tâche de prédiction des mots. En résumé, EAGLE extrapole au niveau des fonctionnalités, en utilisant une petite tête autorégressive, puis utilise une tête de classification gelée pour générer des séquences de mots prédites. Conformément à des travaux similaires tels que Speculative Sampling, Medusa et Lookahead, EAGLE se concentre sur la latence de l'inférence par signal plutôt que sur le débit global du système.
EAGLE - une méthode pour améliorer l'efficacité de la génération de grands modèles de langage Die obige Abbildung zeigt den Unterschied in der Eingabe und Ausgabe zwischen EAGLE und der standardmäßigen spekulativen Stichprobe, Medusa und Lookahead. Die folgende Abbildung zeigt den Workflow von EAGLE. Im Vorwärtsdurchlauf des ursprünglichen LLM sammelt EAGLE Features aus der zweitobersten Ebene. Der autoregressive Kopf nimmt diese Merkmale und die Worteinbettungen zuvor generierter Wörter als Eingabe und beginnt, das nächste Wort zu erraten. Anschließend wird der eingefrorene Klassifizierungskopf (LM Head) verwendet, um die Verteilung des nächsten Wortes zu bestimmen, sodass EAGLE eine Stichprobe aus dieser Verteilung ziehen kann. Durch mehrmaliges Wiederholen der Stichproben führt EAGLE einen baumartigen Generierungsprozess durch, wie auf der rechten Seite der folgenden Abbildung dargestellt. In diesem Beispiel „erriet“ der dreifache Vorwärtspass von EAGLE einen Baum mit 10 Wörtern. 
EAGLE verwendet einen leichten autoregressiven Kopf, um Merkmale des ursprünglichen LLM vorherzusagen. Um die Konsistenz der generierten Textverteilung sicherzustellen, validiert EAGLE anschließend die vorhergesagte Baumstruktur. Dieser Verifizierungsprozess kann mit einem Vorwärtsdurchgang abgeschlossen werden. Durch diesen Zyklus aus Vorhersage und Überprüfung ist EAGLE in der Lage, schnell Textwörter zu generieren. Die Kosten für das Training eines autoregressiven Kopfes sind sehr gering. EAGLE wird mithilfe des ShareGPT-Datensatzes trainiert, der knapp 70.000 Dialogrunden enthält. Auch die Anzahl der trainierbaren Parameter des autoregressiven Kopfes ist sehr gering. Wie im Bild oben blau dargestellt, sind die meisten Komponenten eingefroren. Das einzige zusätzliche Training, das erforderlich ist, ist der autoregressive Kopf, bei dem es sich um eine einschichtige Transformer-Struktur mit Parametern von 0,24 B bis 0,99 B handelt. Autoregressive Köpfe können auch bei unzureichenden GPU-Ressourcen trainiert werden. Beispielsweise kann die autoregressive Regression von Vicuna 33B in 24 Stunden auf einem RTX 3090-Server mit 8 Karten trainiert werden. Warum Worteinbettungen verwenden, um Funktionen vorherzusagen? Medusa verwendet nur die Funktionen der zweitobersten Ebene, um das nächste Wort vorherzusagen, das nächste Wort ... Im Gegensatz zu Medusa verwendet EAGLE auch dynamisch die aktuell abgetastete Worteinbettung als autoregressiven Kopfeingabeteil, um Vorhersagen zu treffen. Diese zusätzlichen Informationen helfen EAGLE, mit der unvermeidlichen Zufälligkeit im Stichprobenprozess umzugehen. Betrachten Sie das Beispiel im Bild unten, wobei davon ausgegangen wird, dass das Aufforderungswort „I“ ist. LLM gibt die Wahrscheinlichkeit an, dass auf „ich“ ein „bin“ oder „immer“ folgt. Medusa berücksichtigt nicht, ob „am“ oder „immer“ abgetastet wird, und sagt direkt die Wahrscheinlichkeit des nächsten Wortes unter „I“ voraus. Daher besteht Medusas Ziel darin, das nächste Wort für „Ich bin“ oder „Ich immer“ vorherzusagen, wenn nur „Ich“ gegeben wird. Aufgrund der zufälligen Natur des Sampling-Prozesses kann die gleiche Eingabe „I“ für Medusa ein unterschiedliches nächstes Wort als Ausgabe „ready“ oder „begin“ haben, was zu einem Mangel an konsistenter Zuordnung zwischen Eingaben und Ausgaben führt. Im Gegensatz dazu umfasst die Eingabe in EAGLE die Worteinbettungen der Stichprobenergebnisse, wodurch eine konsistente Zuordnung zwischen Eingabe und Ausgabe gewährleistet wird. Diese Unterscheidung ermöglicht es EAGLE, nachfolgende Wörter genauer vorherzusagen, indem der durch den Sampling-Prozess festgelegte Kontext berücksichtigt wird. 
Baumartige GenerationsstrukturAnders als andere Rate-Verifizierungs-Frameworks wie Speculative Sampling, Lookahead und Medusa übernimmt EAGLE dabei in der Phase des „Rateworts“ eine baumartige Generationsstruktur Erzielung einer höheren Dekodierungseffizienz. Wie in der Abbildung gezeigt, ist der Generierungsprozess der standardmäßigen spekulativen Stichprobenziehung und Lookahead linear oder verkettet. Da der Kontext während der Ratephase nicht konstruiert werden kann, generiert die Medusa-Methode Bäume durch das kartesische Produkt, was zu einem vollständig verbundenen Diagramm zwischen benachbarten Schichten führt. Dieser Ansatz führt oft zu bedeutungslosen Kombinationen, wie zum Beispiel „Ich fange an“. Im Gegensatz dazu erstellt EAGLE eine spärlichere Baumstruktur. Diese spärliche Baumstruktur verhindert die Bildung bedeutungsloser Sequenzen und konzentriert die Rechenressourcen auf sinnvollere Wortkombinationen. 
Mehrere Runden der spekulativen StichprobeDie standardmäßige spekulative Stichprobenmethode behält die Konsistenz der Verteilung während des Prozesses des „Erratens von Wörtern“ bei. Um sich an baumartige Wortratenszenarien anzupassen, erweitert EAGLE diese Methode in eine mehrrundenrekursive Form. Im Folgenden wird der Pseudocode für mehrere Runden spekulativer Stichprobenentnahme dargestellt. Während des Baumgenerierungsprozesses zeichnet EAGLE die Wahrscheinlichkeit auf, die jedem abgetasteten Wort entspricht. Durch mehrere Runden spekulativer Stichproben stellt EAGLE sicher, dass die endgültig generierte Verteilung jedes Wortes mit der Verteilung des ursprünglichen LLM übereinstimmt. 
Weitere experimentelle ErgebnisseDie folgende Abbildung zeigt den Beschleunigungseffekt von EAGLE auf Vicuna 33B bei verschiedenen Aufgaben. „Codierungs“-Aufgaben mit einer großen Anzahl fester Vorlagen zeigen die beste Beschleunigungsleistung. 
Begrüßen Sie alle, EAGLE zu erleben und Feedback und Vorschläge über die GitHub-Ausgabe zu geben: https://github.com/SafeAILab/EAGLE/issuesCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn


 Dans l'échantillonnage spéculatif, la tâche du projet de modèle est de prédire le mot suivant en fonction de la séquence de mots actuelle. Accomplir cette tâche à l’aide d’un modèle avec un nombre de paramètres nettement inférieur est extrêmement difficile et donne souvent des résultats sous-optimaux. De plus, le projet de modèle de l'approche d'échantillonnage spéculatif standard prédit indépendamment le mot suivant sans exploiter les riches informations sémantiques extraites par le LLM d'origine, ce qui entraîne des inefficacités potentielles.
Dans l'échantillonnage spéculatif, la tâche du projet de modèle est de prédire le mot suivant en fonction de la séquence de mots actuelle. Accomplir cette tâche à l’aide d’un modèle avec un nombre de paramètres nettement inférieur est extrêmement difficile et donne souvent des résultats sous-optimaux. De plus, le projet de modèle de l'approche d'échantillonnage spéculatif standard prédit indépendamment le mot suivant sans exploiter les riches informations sémantiques extraites par le LLM d'origine, ce qui entraîne des inefficacités potentielles.