La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les auteurs de cet article viennent de l'Université Jiao Tong de Shanghai, de l'Université Tsinghua, de l'Université de Cambridge et du Laboratoire d'intelligence artificielle de Shanghai. Le premier auteur, Chen Zhe, est doctorant à l’Université Jiao Tong de Shanghai et étudie sous la direction du professeur Wang Yu de l’École d’intelligence artificielle de l’Université Jiao Tong de Shanghai. Les auteurs correspondants sont le professeur Wang Yu (page d'accueil : https://yuwangsjtu.github.io/) et le professeur Zhang Chao du Département de génie électronique de l'Université Tsinghua (page d'accueil : https://mi.eng.cam.ac.uk /~cz277). 
- Lien papier : https://arxiv.org/abs/2403.14168
- Page d'accueil du projet : https://jack-zc8.github.io/M3AV-dataset-page/
- Titre de l'article : M3AV : Un ensemble de données de conférences académiques audiovisuelles multimodales, multigenres et polyvalentes
L'enregistrement de conférences académiques open source est un moyen couramment populaire de partager des connaissances académiques Méthodes en ligne. Ces vidéos contiennent de riches informations multimodales, notamment la voix, les expressions faciales et les mouvements corporels de l'orateur, le texte et les images des diapositives, ainsi que les informations textuelles correspondantes sur papier. Il existe actuellement très peu d'ensembles de données capables de prendre en charge simultanément des tâches de reconnaissance et de compréhension de contenu multimodales, en partie à cause du manque d'annotations humaines de haute qualité.
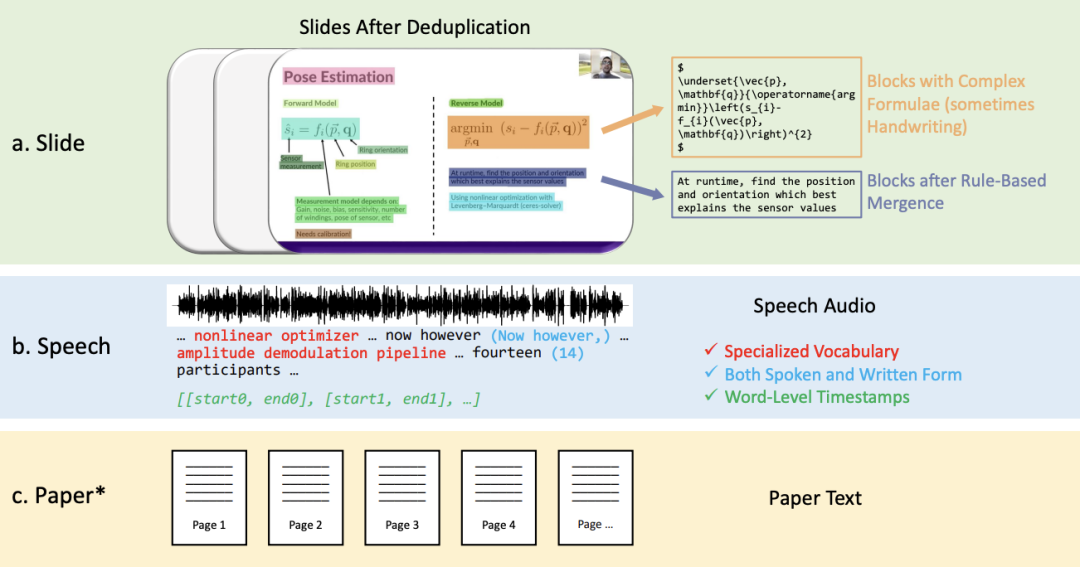
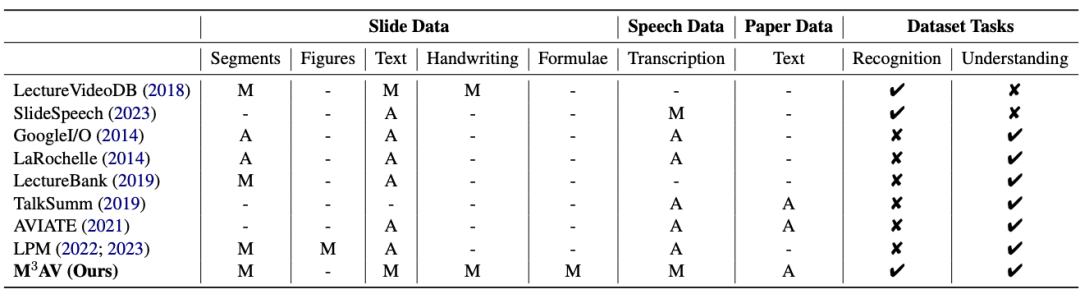
Cet ouvrage propose un nouvel ensemble de données de parole académique audiovisuelle multimodale, multitype et polyvalent (M3AV), qui contient près de 367 heures de vidéos provenant de cinq sources, couvrant l'informatique, les mathématiques, la médecine et Sujets biologiques. Grâce à des annotations humaines de haute qualité, en particulier des entités nommées de grande valeur, l'ensemble de données peut être utilisé pour diverses tâches de reconnaissance et de compréhension audiovisuelles. Les évaluations sur les tâches de reconnaissance vocale contextuelle, de synthèse vocale et de génération de diapositives et de scripts montrent que la diversité de M3AV en fait un ensemble de données difficile. Ce travail a été accepté par la conférence principale de l’ACL 2024. Informations sur l'ensemble de donnéesL'ensemble de données M3AV se compose principalement des parties suivantes : 2. Texte transcrit vocalement sous forme orale et écrite, y compris un vocabulaire spécial et des horodatages au niveau des mots. 3. Le texte papier correspondant à la vidéo. Comme le montre le tableau ci-dessous, l'ensemble de données M3AV contient les ressources de diapositives, de discours et de papier les plus annotées par l'homme. Par conséquent, il prend non seulement en charge les tâches de reconnaissance de contenu multimodales, mais prend également en charge. connaissances académiques avancées. Comprendre la tâche .
En même temps, l'ensemble de données M3AV est plus riche en contenu que les autres ensembles de données académiques dans tous les aspects, et c'est également une ressource accessible.
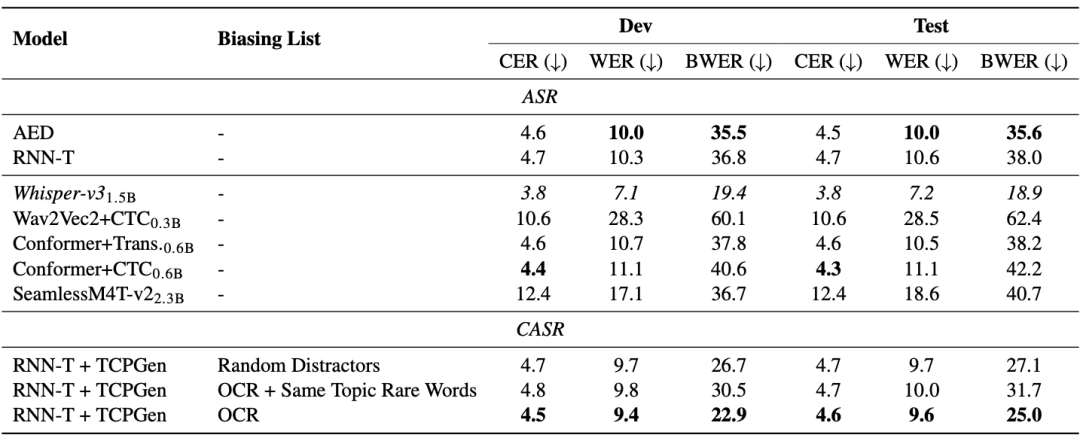
L'ensemble de données M3AV est conçu avec trois tâches de perception et de compréhension multimodales, à savoir la reconnaissance vocale basée sur le contexte, la synthèse vocale de style spontané et la génération de diapositives et de scripts. Tâche 1 : Reconnaissance vocale basée sur le contexte Les modèles généraux de bout en bout ont des problèmes de reconnaissance de mots rares. Comme le montrent les modèles AED et RNN-T du tableau ci-dessous, le taux d'erreur sur les mots rares (BWER) a augmenté de plus de deux fois par rapport au taux d'erreur sur les mots total (WER). En exploitant les informations OCR pour la reconnaissance vocale basée sur le contexte à l'aide de TCPGen, le modèle RNN-T a obtenu une réduction relative de 37,8 % et 34,2 % du BWER sur les ensembles de développement et de test, respectivement.
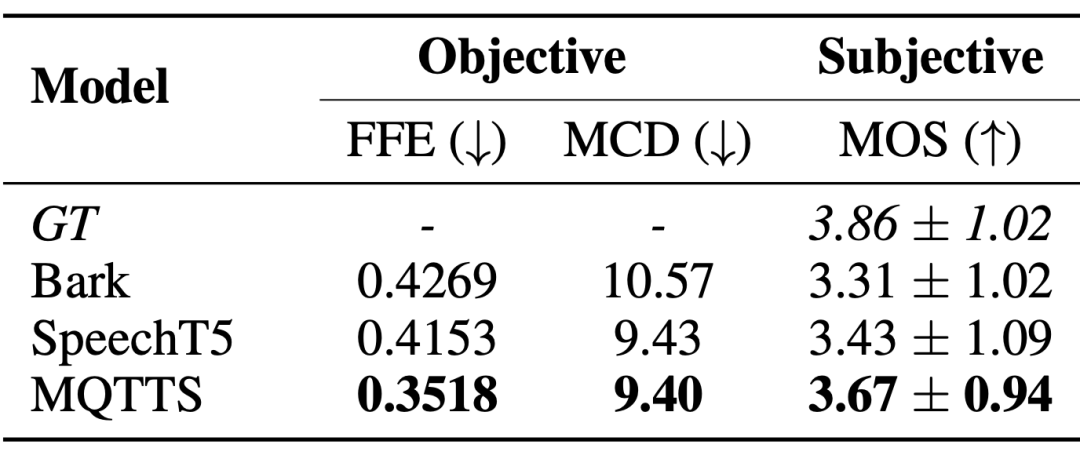
Tâche 2 : Synthèse vocale de style spontané Les systèmes de synthèse vocale de style spontané ont un besoin urgent de données vocales dans des scénarios réels pour produire une parole plus proche des modèles de conversation naturels. L'auteur de l'article a présenté MQTTS comme modèle expérimental et a constaté que par rapport à divers modèles pré-entraînés, MQTTS possède les meilleurs indicateurs d'évaluation. Cela montre que la parole réelle dans l’ensemble de données M3AV peut amener les systèmes d’IA à simuler une parole plus naturelle.
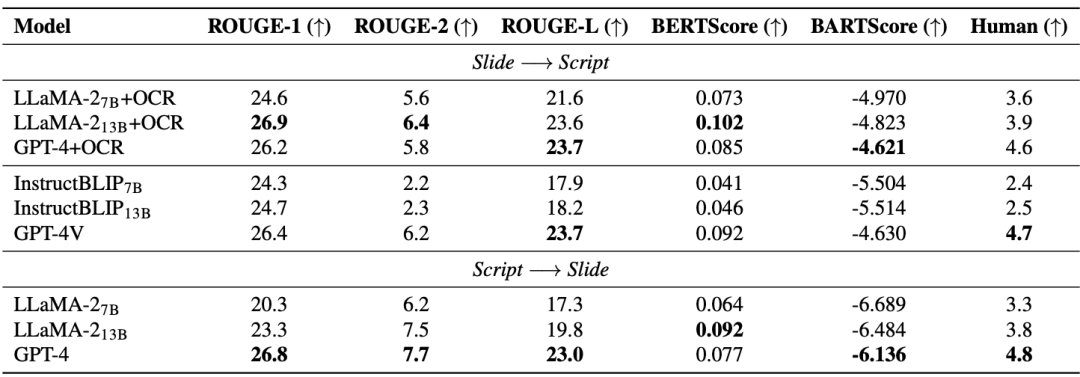
Tâche 3 : Génération de diapositives et de scripts La tâche de génération de diapositives et de scripts (SSG) est conçue pour promouvoir la compréhension du modèle d'IA et reconstruire les connaissances académiques avancées, aidant ainsi les chercheurs à traiter rapidement la mise à jour et itérer du matériel académique pour mener efficacement des recherches universitaires. Comme le montre le tableau ci-dessous, l'amélioration des performances des modèles open source (LLaMA-2, InstructBLIP) est limitée lorsqu'on passe de 7B à 13B, en retard par rapport aux modèles fermés (GPT-4 et GPT-4V ). Par conséquent, en plus d’augmenter la taille du modèle, l’auteur de l’article estime que des données de pré-formation multimodales de haute qualité sont également nécessaires. Notamment, le grand modèle multimodal avancé (GPT-4V) a surpassé les modèles en cascade composés de plusieurs modèles monomodaux.
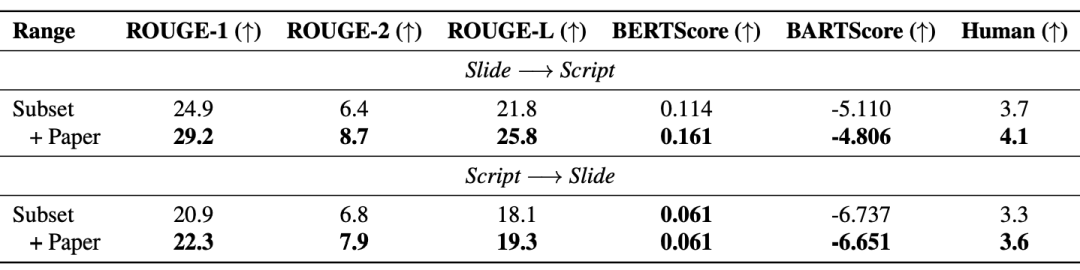
De plus, la génération améliorée de récupération (RAG) améliore efficacement les performances du modèle : le tableau ci-dessous montre que le texte papier introduit améliore également la qualité des diapositives et des scripts générés.
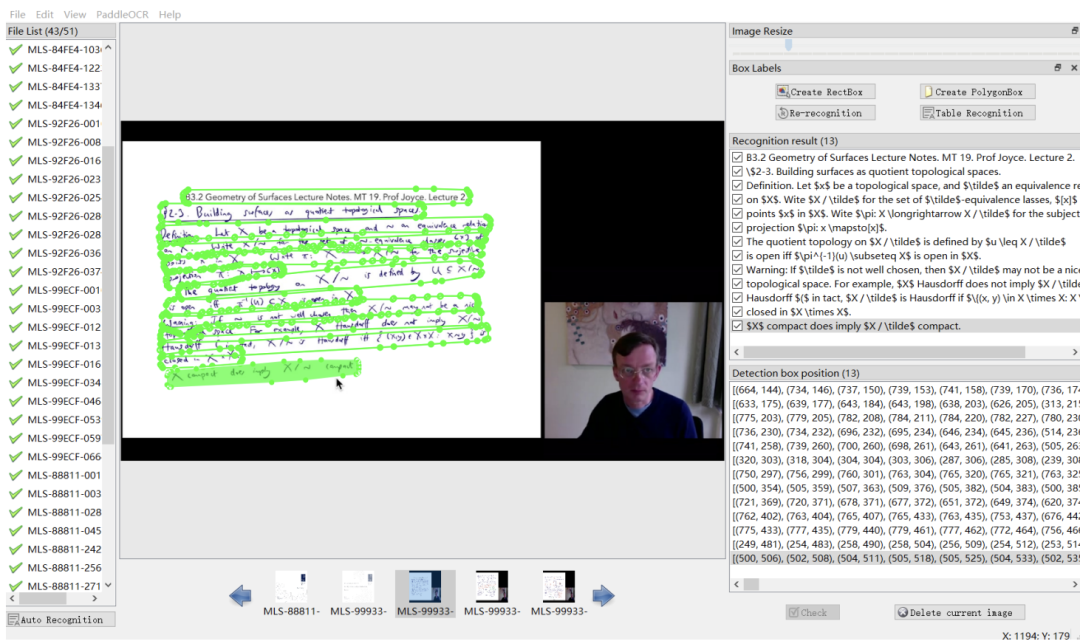
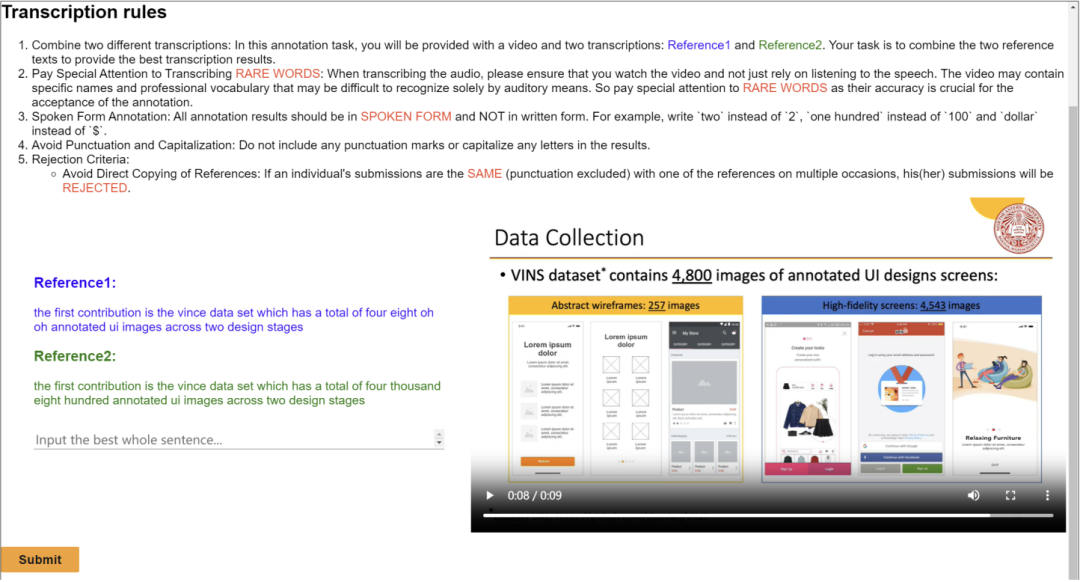
Cet ouvrage publie un ensemble de données audiovisuelles multimodales, multi-types et polyvalentes (M3AV) couvrant plusieurs domaines académiques. L'ensemble de données contient des transcriptions vocales annotées par des humains, des diapositives et des textes d'essais extraits supplémentaires, fournissant une base pour évaluer la capacité des modèles d'IA à reconnaître le contenu multimodal et à comprendre les connaissances académiques. Les auteurs de l'article décrivent le processus de création en détail et effectuent diverses analyses sur l'ensemble de données. De plus, ils ont construit des références et mené plusieurs expériences autour de l’ensemble de données. En fin de compte, les auteurs de l’article ont constaté que les modèles existants pouvaient encore être améliorés dans la perception et la compréhension des vidéos de cours universitaires. Interface d'annotation partielle
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn