
Maison >Périphériques technologiques >IA >Le « travail sincère » de Google, versions open source 9B et 27B de Gemma2, axées sur l'efficacité et l'économie !
Le « travail sincère » de Google, versions open source 9B et 27B de Gemma2, axées sur l'efficacité et l'économie !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-29 00:59:211129parcourir
Gemma 2 avec deux fois plus de performances, comment jouer à Llama 3 avec le même niveau ?


Excellentes performances : Le modèle Gemma 2 27B offre les meilleures performances dans sa catégorie de volume, rivalisant même avec des modèles plus de deux fois plus grands que ses concurrents. Le modèle 9B Gemma 2 a également obtenu de bons résultats dans sa catégorie de taille et a surpassé le Llama 3 8B et d'autres modèles ouverts comparables. Haute efficacité, faible coût : le modèle 27B Gemma 2 est conçu pour exécuter efficacement des inférences avec une précision maximale sur un seul hôte Google Cloud TPU, un GPU NVIDIA A100 Tensor Core de 80 Go ou un GPU NVIDIA H100 Tensor Core, tout en conservant des performances élevées. Réduisez considérablement les coûts. Cela rend le déploiement de l’IA plus pratique et plus abordable. Inférence ultra-rapide : Gemma 2 est optimisé pour fonctionner à des vitesses fulgurantes sur une variété de matériels, qu'il s'agisse d'un ordinateur portable de jeu puissant, d'un ordinateur de bureau haut de gamme ou d'une configuration basée sur le cloud. Les utilisateurs peuvent essayer d'exécuter Gemma 2 avec une précision totale sur Google AI Studio, ou utiliser une version quantifiée de Gemma.cpp sur le processeur pour débloquer les performances locales, ou l'essayer sur un ordinateur personnel en utilisant NVIDIA RTX ou GeForce RTX via Hugging Face Transformers.

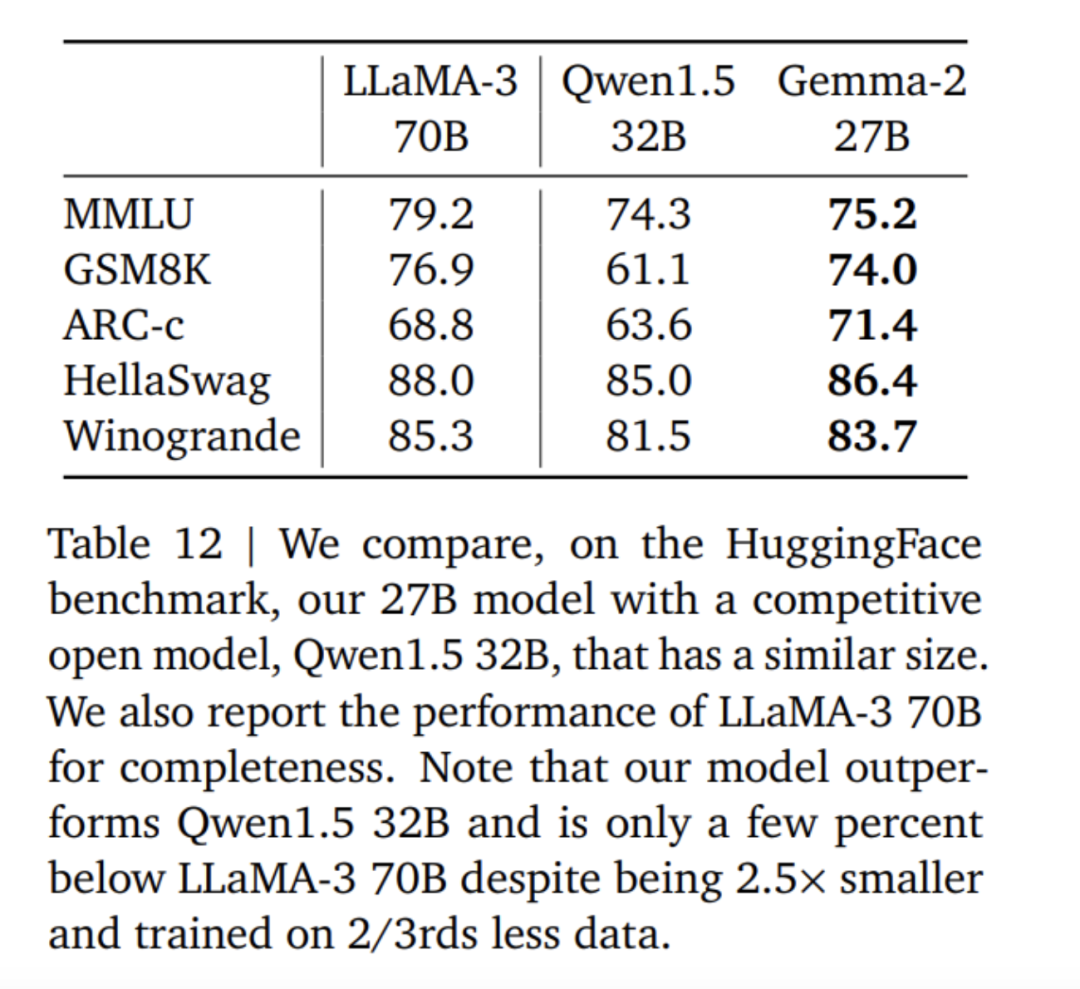
Ce qui précède est la comparaison des données de score entre Gemma2, Llama3 et Grok-1.
En fait, à en juger par diverses données de score, les avantages du grand modèle open source 9B ne sont pas particulièrement évidents. Le grand modèle domestique GLM-4-9B, qui a été open source par Zhipu AI il y a près d'un mois, présente encore plus d'avantages.

Ouvert et accessible : comme le modèle Gemma original, Gemma 2 permet aux développeurs et aux chercheurs de partager et de commercialiser des innovations. Compatibilité étendue du framework : Gemma 2 est compatible avec les principaux frameworks d'IA tels que Hugging Face Transformers, ainsi que JAX, PyTorch et TensorFlow pris en charge nativement via Keras 3.0, vLLM, Gemma.cpp, Llama.cpp et Ollama, ce qui en fait Intégrez facilement les outils et flux de travail préférés des utilisateurs. De plus, Gemma a été optimisé avec NVIDIA TensorRT-LLM et peut fonctionner sur l'infrastructure accélérée NVIDIA ou en tant que microservice d'inférence NVIDIA NIM. Il sera également optimisé pour NeMo de NVIDIA à l'avenir et pourra être affiné à l'aide de Keras et Hugging Face. De plus, Google améliore activement ses capacités de réglage. Déploiement facile : à partir du mois prochain, les clients Google Cloud pourront facilement déployer et gérer Gemma 2 sur Vertex AI.
Dans le dernier blog, Google a annoncé avoir ouvert l'accès à la fenêtre contextuelle de 2 millions de jetons de Gemini 1.5 Pro à tous les développeurs. Cependant, à mesure que la fenêtre contextuelle augmente, le coût des intrants peut également augmenter. Afin d'aider les développeurs à réduire le coût de plusieurs tâches d'invite utilisant le même jeton, Google a judicieusement lancé la fonction de mise en cache contextuelle dans l'API Gemini pour Gemini 1.5 Pro et 1.5 Flash. Pour résoudre le problème selon lequel les grands modèles de langage doivent générer et exécuter du code pour améliorer la précision lors du traitement des mathématiques ou du raisonnement des données, Google a activé l'exécution de code dans Gemini 1.5 Pro et 1.5 Flash. Lorsqu'il est activé, le modèle peut générer et exécuter dynamiquement du code Python et apprendre de manière itérative des résultats jusqu'à ce que le résultat final souhaité soit obtenu. Le sandbox d'exécution ne se connecte pas à Internet et est fourni en standard avec certaines bibliothèques numériques. Les développeurs doivent uniquement être facturés en fonction du jeton de sortie du modèle. C'est la première fois que Google introduit l'exécution de code comme étape de la fonctionnalité du modèle, disponible aujourd'hui via l'API Gemini et les paramètres avancés de Google AI Studio. Google souhaite rendre l'IA accessible à tous les développeurs, qu'il s'agisse d'intégrer des modèles Gemini via des clés API ou d'utiliser le modèle ouvert Gemma 2. Pour aider les développeurs à mettre la main sur le modèle Gemma 2, l'équipe Google le rendra disponible pour expérimentation dans Google AI Studio.

Adresse papier : https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf Adresse du blog : https://blog.google/ technology/developers/google-gemma-2/

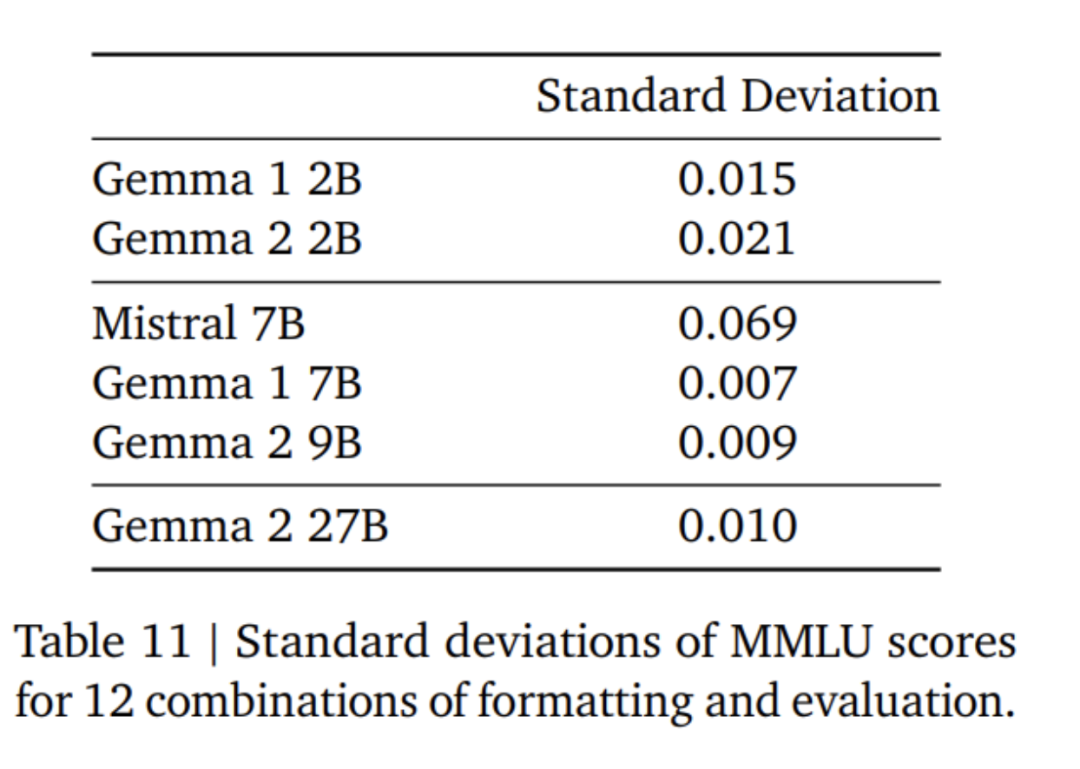
Fenêtre coulissante locale et attention globale. L’équipe de recherche a utilisé en alternance l’attention locale par fenêtre glissante et l’attention globale dans toutes les autres couches. La taille de la fenêtre mobile de la couche d'attention locale est définie sur 4 096 jetons, tandis que la durée de la couche d'attention globale est définie sur 8 192 jetons. Casquette souple Logit. Selon la méthode de Gemini 1.5, l'équipe de recherche limite le logit à chaque couche d'attention et à la couche finale afin que la valeur du logit reste entre −soft_cap et +soft_cap. Pour les modèles 9B et 27B, l'équipe de recherche a fixé le plafond logarithmique d'attention à 50,0 et le plafond logarithmique final à 30,0. Au moment de la publication, le plafonnement logiciel de l'attention logit est incompatible avec les implémentations courantes de FlashAttention, ils ont donc supprimé cette fonctionnalité des bibliothèques qui utilisent FlashAttention. L'équipe de recherche a mené des expériences d'ablation sur la génération de modèles avec et sans capping doux du logit d'attention, et a constaté que la qualité de la génération n'était presque pas affectée dans la plupart des pré-formations et des post-évaluations. Toutes les évaluations présentées dans cet article utilisent l'architecture complète du modèle, y compris le plafonnement logiciel Attention Logit. Toutefois, certaines performances en aval peuvent encore être légèrement affectées par cette suppression. Utilisez RMSNorm pour la post-norme et la pré-norme. Afin de stabiliser la formation, l’équipe de recherche a utilisé RMSNorm pour normaliser les entrées et sorties de chaque sous-couche de transformation, couche d’attention et couche de rétroaction. Requérez l'attention en groupe. Les modèles 27B et 9B utilisent GQA, num_groups = 2, et les expériences basées sur l'ablation montrent une vitesse d'inférence améliorée tout en maintenant les performances en aval.

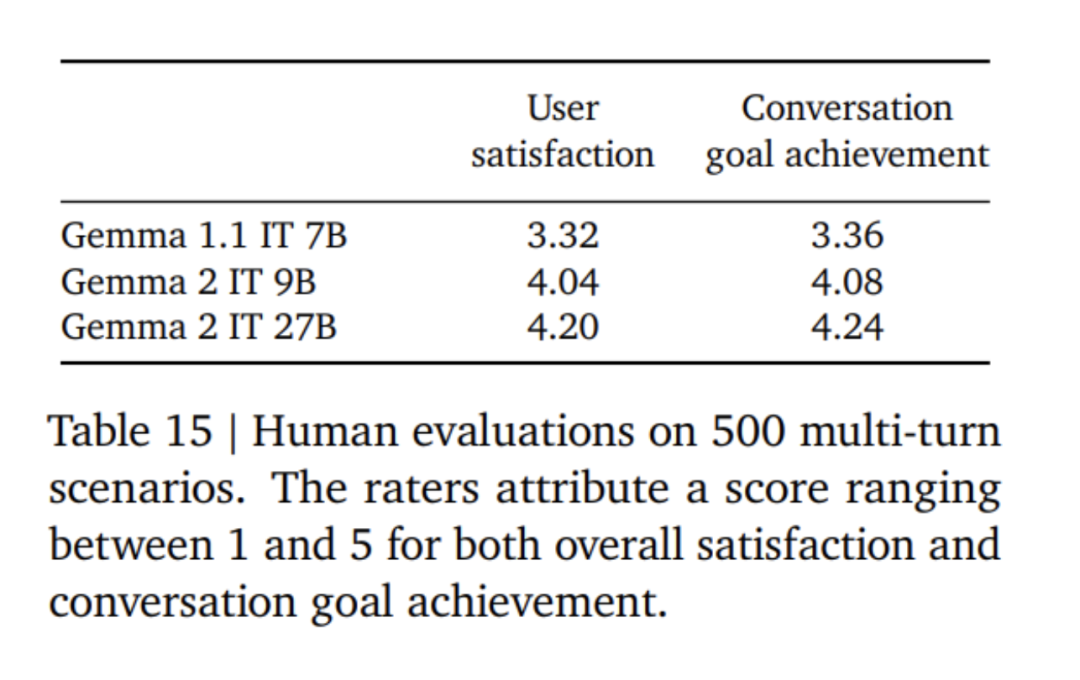
Tout d'abord, appliquez un réglage fin supervisé (SFT) sur un mélange de texte brut, de synthèse anglaise pure et de paires invite-réponse générées artificiellement. Ensuite, un apprentissage par renforcement basé sur le modèle de récompense (RLHF) est appliqué sur ces modèles. Le modèle de récompense est formé sur des données de préférence en anglais pur basées sur des jetons, et la stratégie utilise la même invite que l'étape SFT. Enfin, améliorez les performances globales en faisant la moyenne des modèles obtenus à chaque étape. Les méthodes finales de mélange de données et de post-formation, y compris les hyperparamètres réglés, sont choisies en fonction de la minimisation des dangers du modèle liés à la sécurité et aux hallucinations tout en augmentant l'utilité du modèle.





Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:ICML 2024 | Révéler le mécanisme de l'apprentissage non linéaire des transformateurs et de la généralisation dans l'apprentissage contextuelArticle suivant:ICML 2024 | Révéler le mécanisme de l'apprentissage non linéaire des transformateurs et de la généralisation dans l'apprentissage contextuel
Articles Liés
Voir plus- L'innovation technologique accélère la mise en œuvre de l'industrie chinoise des interfaces cerveau-ordinateur
- La Corée du Sud a annoncé qu'elle investirait 500 milliards de wons au cours des cinq prochaines années pour soutenir l'industrie clé de la technologie de l'IA.
- Lightning News | JD.com lance le grand modèle Yanxi AI pour les scénarios de vente au détail, médicaux, logistiques et autres
- Ministère de l'Industrie et des Technologies de l'information : l'industrie de base de l'IA en Chine atteint 500 milliards de yuans, et plus de 2 500 ateliers numériques et usines intelligentes ont été construits
- Robot ETF (159770) : Attirant des entrées nettes de capitaux pendant 4 jours consécutifs, les « Avis directeurs sur l'innovation et le développement des robots humanoïdes » peuvent promouvoir le processus de développement industriel