
Maison >Périphériques technologiques >IA >Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »

- 王林original
- 2024-06-24 15:04:43711parcourir

La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Dans le processus de développement du domaine de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant pour garantir que ces modèles servent la société humaine avec puissance et sécurité. Les premiers efforts se sont concentrés sur la gestion de ces modèles via des méthodes d’apprentissage par renforcement avec feedback humain (RLHF), avec des résultats impressionnants marquant une étape clé vers une IA plus humaine.
Malgré son grand succès, la RLHF est très gourmande en ressources lors des entraînements. Par conséquent, ces derniers temps, les chercheurs ont continué à explorer des voies d’optimisation des politiques plus simples et plus efficaces, basées sur les bases solides posées par le RLHF, donnant ainsi naissance à l’optimisation des préférences directes (DPO). DPO obtient une cartographie directe entre la fonction de récompense et la stratégie optimale grâce à un raisonnement mathématique, éliminant le processus de formation du modèle de récompense, optimisant le modèle de stratégie directement sur les données de préférence et réalisant un saut intuitif du « feedback à la stratégie ». Cela réduit non seulement la complexité, mais améliore également la robustesse de l'algorithme, devenant rapidement le nouveau favori du secteur.
Cependant, DPO se concentre principalement sur l'optimisation des politiques sous des contraintes de divergence KL inverse. DPO est excellent pour améliorer les performances d'alignement grâce à la propriété de recherche de mode de divergence KL inverse, mais cette propriété tend également à réduire la diversité pendant le processus de génération, limitant potentiellement les capacités du modèle. D'un autre côté, bien que DPO contrôle la divergence KL du point de vue de la phrase, le processus de génération de modèle est essentiellement jeton par jeton. Le contrôle de la divergence KL au niveau de la phrase montre intuitivement que le DPO a des limites en termes de contrôle fin et une faible capacité à ajuster la divergence KL, ce qui peut être l'un des facteurs clés du déclin rapide de la diversité générative du LLM au cours de la formation DPO.
À cette fin, l'équipe de Wang Jun et Zhang Haifeng de l'Académie chinoise des sciences et de l'University College de Londres a proposé un grand algorithme d'alignement de modèles modélisé du point de vue du jeton : TDPO.

Titre de l'article : Optimisation des préférences directes au niveau du jeton
Adresse de l'article : https://arxiv.org/abs/2404.11999
Adresse du code : https://github.com/Vance0124 /Token-level-Direct-Preference-Optimization
Afin de faire face à la diminution significative de la diversité de la génération de modèles, TDPO a redéfini la fonction objective de l'ensemble du processus d'alignement du point de vue du jeton et a transformé le Bradley -Modèle Terry en Le convertissant sous la forme d'une fonction d'avantage permet d'analyser et d'optimiser enfin l'ensemble du processus d'alignement à partir du niveau du jeton. Par rapport au DPO, les principales contributions de TDPO sont les suivantes :
Méthode de modélisation au niveau du jeton : TDPO modélise le problème d'un point de vue au niveau du jeton et effectue une analyse plus détaillée du RLHF
KL à grain fin ; Contraintes de divergence : les contraintes de divergence KL avant sont théoriquement introduites à chaque jeton, permettant à la méthode de mieux contraindre l'optimisation du modèle ;
Avantages évidents en termes de performances : par rapport au DPO, TDPO est capable d'obtenir de meilleures performances d'alignement et de générer divers fronts de Pareto.
La principale différence entre DPO et TDPO est illustrée dans la figure ci-dessous :
s L’alignement du TDPO doit être optimisé comme indiqué ci-dessous. DPO est modélisé du point de vue du niveau de la phrase

Figure 2 : Méthode d'optimisation de l'alignement de TDPO. TDPO modélise du point de vue du jeton et introduit des contraintes de divergence KL supplémentaires à chaque jeton, comme le montre la partie rouge de la figure, qui contrôle non seulement le degré de décalage du modèle, mais sert également de référence pour l'alignement du modèle .
Le processus de dérivation spécifique des deux méthodes est présenté ci-dessous.
Contexte : Optimisation directe des préférences (DPO)
DPO obtient une cartographie directe entre la fonction de récompense et la politique optimale par dérivation mathématique, éliminant ainsi l'étape de modélisation de la récompense dans le processus RLHF :
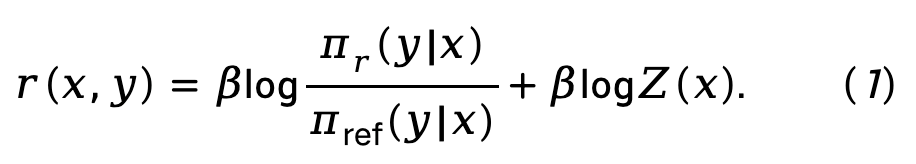
Formule (1) est remplacé dans le modèle de préférence de Bradley-Terry (BT) pour obtenir la fonction de perte d'optimisation de politique directe (DPO) :
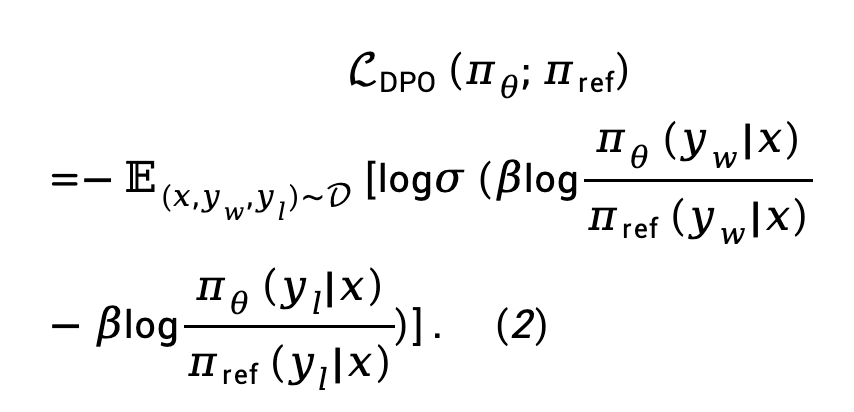
où 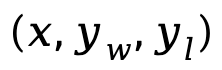 est la paire de préférences composée d'une réponse rapide et gagnante et d'une réponse perdante de l'ensemble de données de préférence D.
est la paire de préférences composée d'une réponse rapide et gagnante et d'une réponse perdante de l'ensemble de données de préférence D.
TDPO
Annotation de symboles
Afin de modéliser le processus de génération séquentielle et autorégressive du modèle de langage, TDPO exprime la réponse générée sous une forme composée de T tokens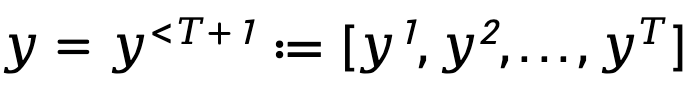 , où
, où 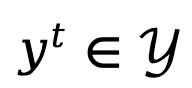 ,
, 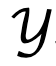 représentent le alphabet (Glossaire).
représentent le alphabet (Glossaire).
Lorsque la génération de texte est modélisée comme un processus de décision markovien, l'état est défini comme la combinaison de l'invite et du jeton qui a été généré jusqu'à l'étape en cours, représentée par 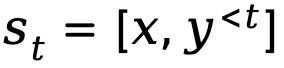 , tandis que l'action correspond au prochain jeton généré, représenté par est
, tandis que l'action correspond au prochain jeton généré, représenté par est 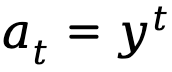 , la récompense au niveau du jeton est définie comme
, la récompense au niveau du jeton est définie comme 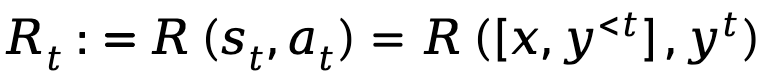 .
.
Sur la base des définitions fournies ci-dessus, TDPO établit une fonction état-action  , une fonction valeur d'état
, une fonction valeur d'état 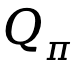 et une fonction avantage
et une fonction avantage  pour la politique
pour la politique 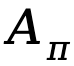 :
:
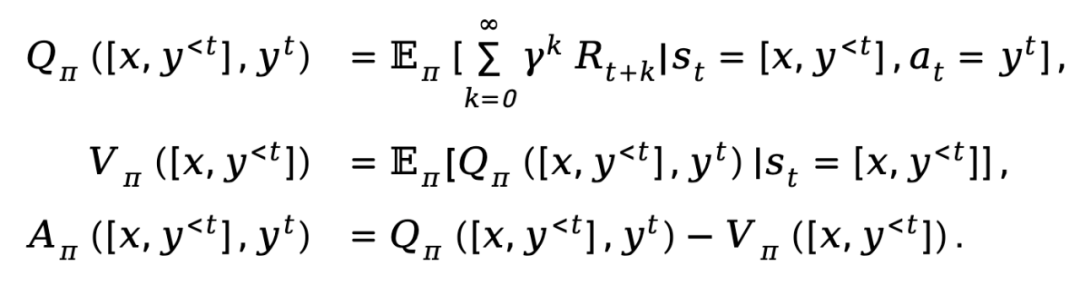
où 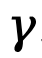 représente le facteur de remise.
représente le facteur de remise.
Apprentissage par renforcement du feedback humain d'un point de vue au niveau du jeton
TDPO modifie théoriquement la phase de modélisation des récompenses et la phase de réglage fin du RLHF, les étendant aux objectifs d'optimisation considérés du point de vue du jeton.
Pour l'étape de modélisation de la récompense, TDPO a établi la corrélation entre le modèle Bradley-Terry et la fonction avantage :
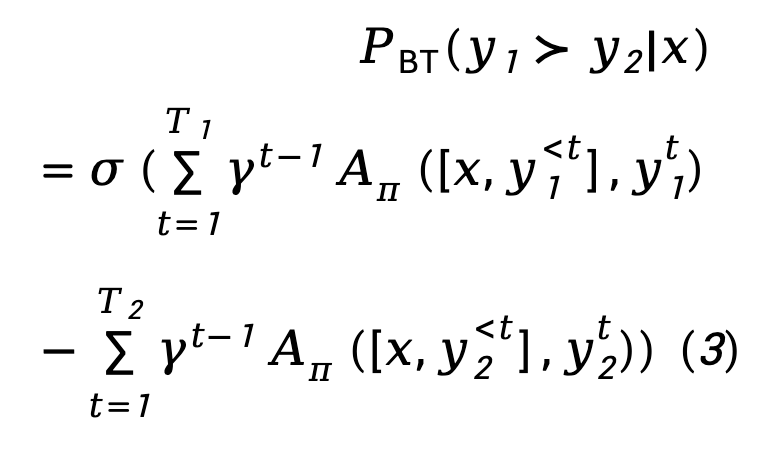
Pour l'étape de réglage fin du RL, TDPO a défini la fonction objectif suivante :
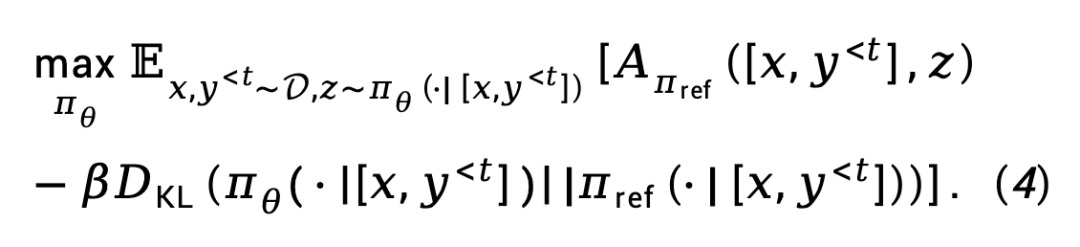
Dérivation
À partir de l'objectif (4), TDPO dérive la relation cartographique entre la stratégie optimale 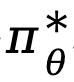 et la fonction état-action
et la fonction état-action  sur chaque jeton :
sur chaque jeton :
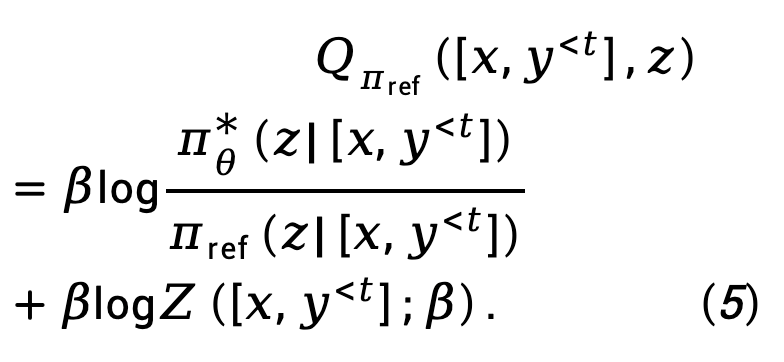
Où, 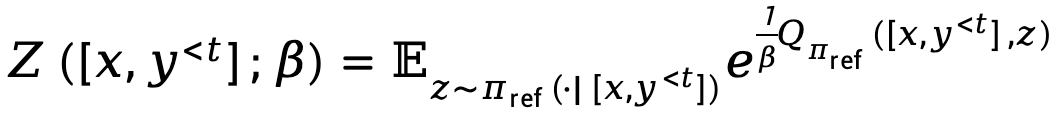 représente la fonction de partition.
représente la fonction de partition.
En remplaçant l'équation (5) par l'équation (3), nous obtenons :
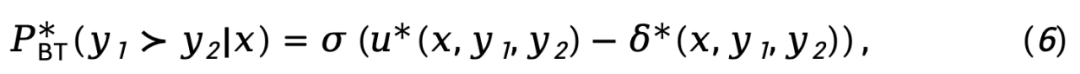
où, 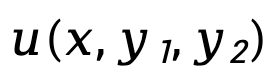 représente la différence dans la fonction de récompense implicite représentée par le modèle de politique
représente la différence dans la fonction de récompense implicite représentée par le modèle de politique 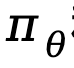 et le modèle de référence
et le modèle de référence 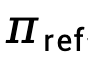 , exprimée par
, exprimée par
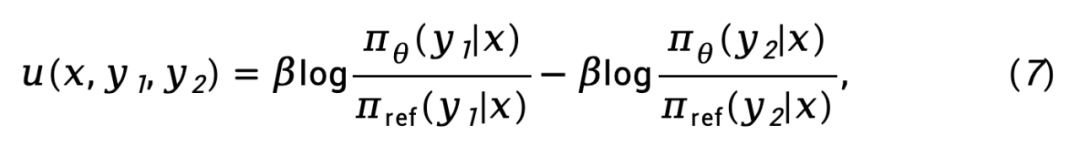
tandis que  est Désignant la différence de divergence KL avant au niveau de la séquence de
est Désignant la différence de divergence KL avant au niveau de la séquence de 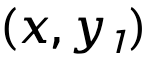 et
et 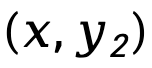 , pondérée par
, pondérée par 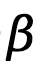 , est exprimée comme
, est exprimée comme
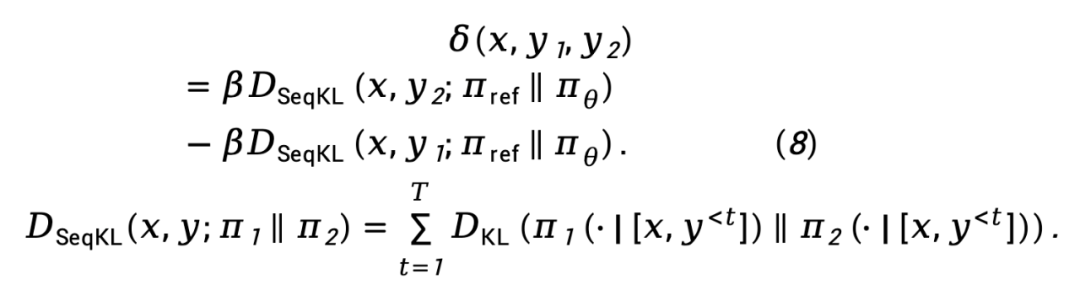
Sur la base de l'équation (8), la fonction de perte de vraisemblance maximale TDPO peut être modélisée comme :
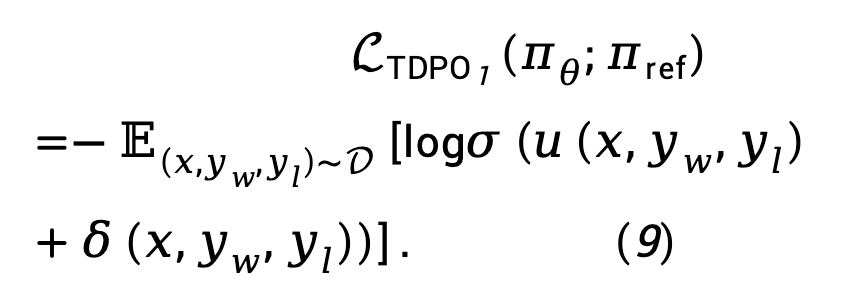
Considérant qu'en pratique, la perte  a tendance à augmenter
a tendance à augmenter 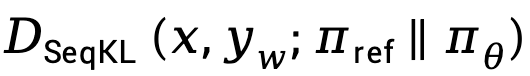 , amplifiant la différence entre
, amplifiant la différence entre  et
et  TDPO propose de modifier l'équation (9) comme :
TDPO propose de modifier l'équation (9) comme :

où 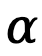 est un hyperparamètre, et
est un hyperparamètre, et
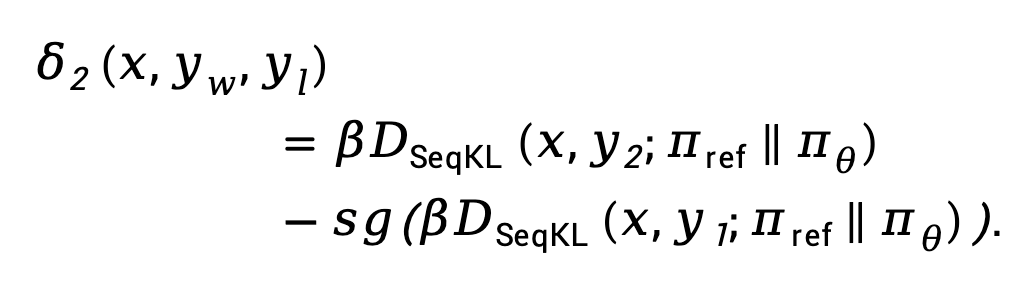
Ici, 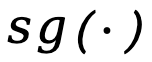 signifie Arrêter l'opérateur de propagation du gradient.
signifie Arrêter l'opérateur de propagation du gradient.
Nous résumons les fonctions de perte de TDPO et DPO comme suit :

On peut voir que TDPO introduit ce contrôle de divergence KL vers l'avant à chaque jeton, permettant un meilleur contrôle de KL lors des changements du processus d'optimisation sans affecter les performances d'alignement. , obtenant ainsi un meilleur front de Pareto.
Paramètres expérimentaux
TDPO a mené des expériences sur les ensembles de données IMDb, Anthropic/hh-rlhf, MT-Bench.
IMDb
Sur l'ensemble de données IMDb, l'équipe a utilisé GPT-2 comme modèle de base, puis siebert/sentiment-roberta-large-english comme modèle de récompense pour évaluer les résultats du modèle politique. Les résultats expérimentaux sont présentés dans la figure 3.
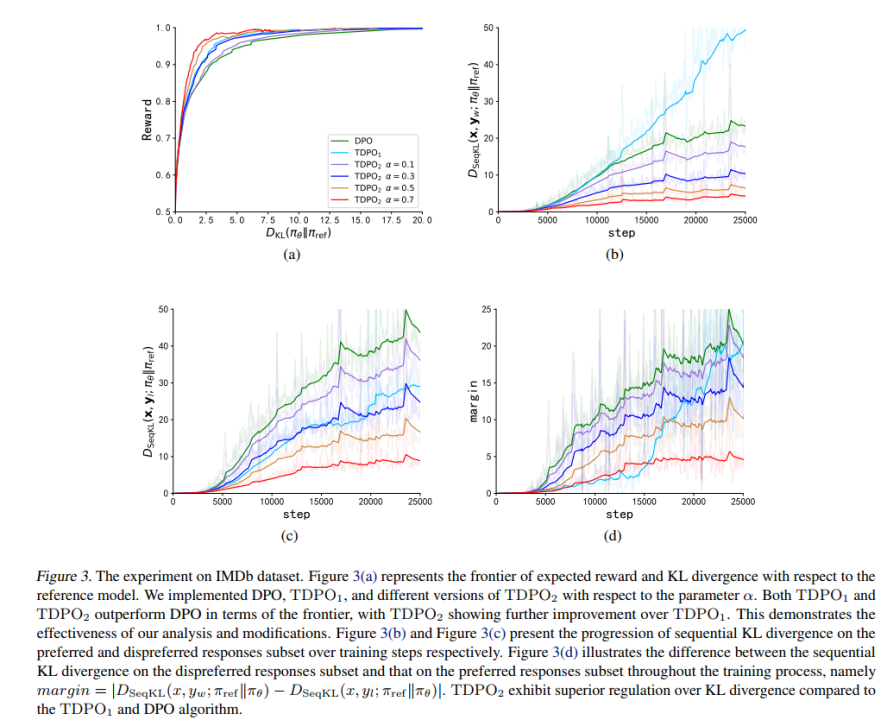
Comme le montre la figure 3 (a), TDPO (TDPO1, TDPO2) peut obtenir un meilleur front de récompense-KL Pareto que DPO, tandis que sur la figure 3 (b) - (d) on peut voir que TDPO fonctionne extrêmement bien dans le contrôle de divergence KL, ce qui est bien meilleur que la capacité de contrôle de divergence KL de l'algorithme DPO.
Anthropic HH
Sur l'ensemble de données Anthropic/hh-rlhf, l'équipe a utilisé Pythia 2.8B comme modèle de base et a utilisé deux méthodes pour évaluer la qualité de la génération du modèle : 1) en utilisant des indicateurs existants 2) évalués à l'aide ; GPT-4.
Pour la première méthode d'évaluation, l'équipe a évalué les compromis en termes de performances d'alignement (précision) et de diversité de génération (entropie) de modèles entraînés avec différents algorithmes, comme le montre le tableau 1.
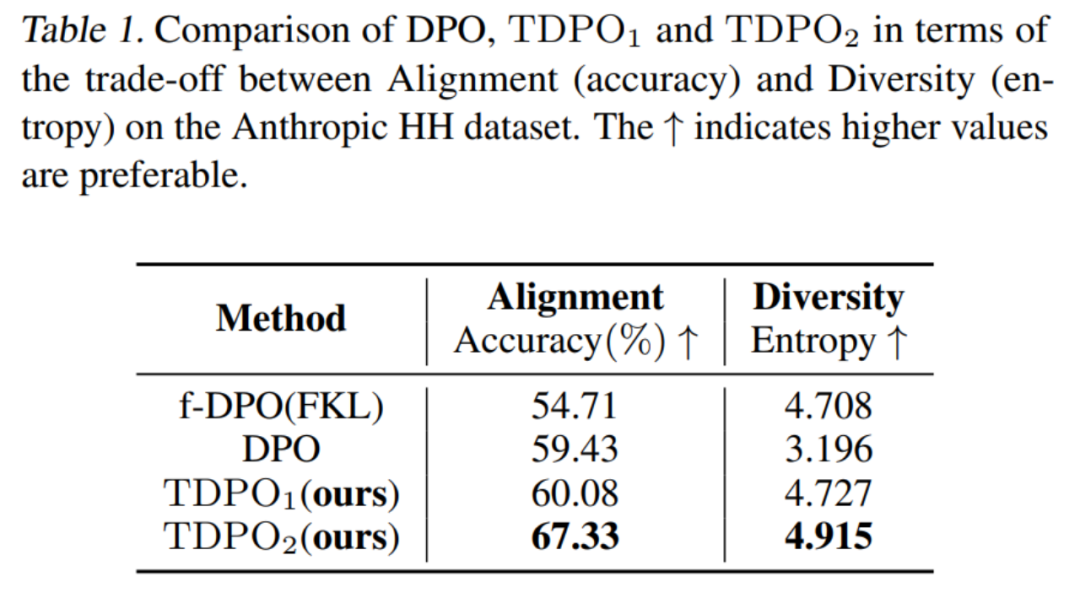
On peut voir que l'algorithme TDPO est non seulement meilleur que DPO et f-DPO en termes de performances d'alignement (précision), mais a également un avantage en termes de diversité de génération (entropie), qui est un indicateur clé de la réponse. générés par ces deux grands modèles. Un meilleur compromis est obtenu.
Pour la deuxième méthode d'évaluation, l'équipe a évalué la cohérence entre les modèles entraînés par différents algorithmes et préférences humaines, et les a comparés aux réponses gagnantes de l'ensemble de données, comme le montre la figure 4.
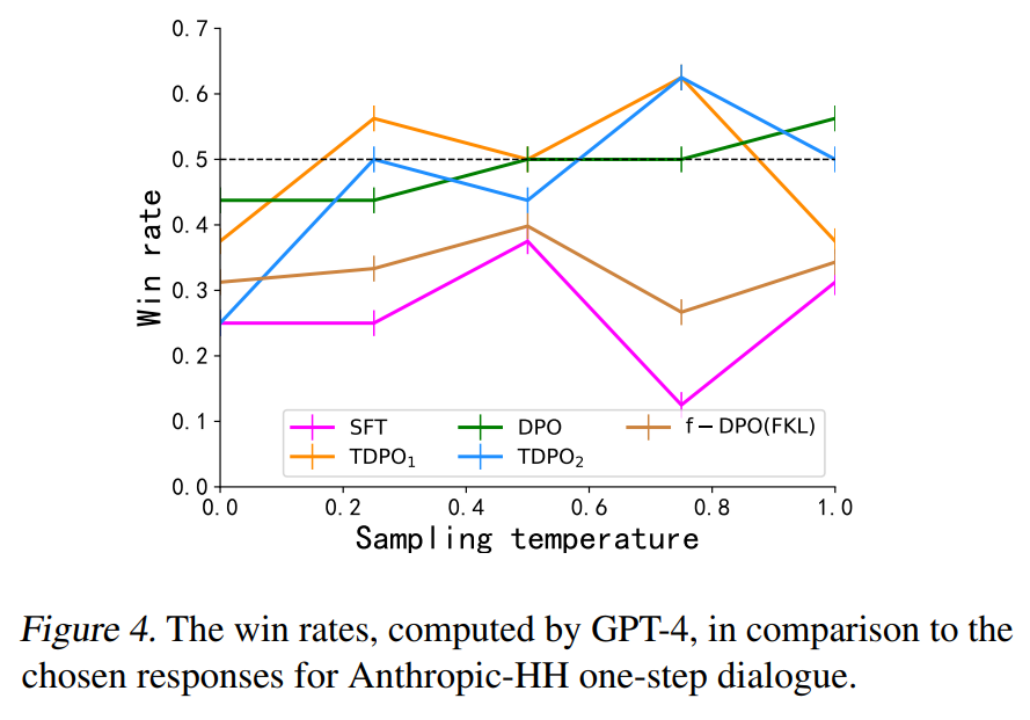
Les algorithmes DPO, TDPO1 et TDPO2 sont tous capables d'atteindre un taux de réussite supérieur à 50 % pour les réponses gagnantes à un coefficient de température de 0,75, ce qui est mieux conforme aux préférences humaines.
MT-Bench
Dans la dernière expérience de l'article, l'équipe a utilisé le modèle Pythia 2.8B formé sur l'ensemble de données Anthropic HH pour l'utiliser directement pour l'évaluation de l'ensemble de données MT-Bench. Les résultats sont présentés dans la figure. 5 Afficher.
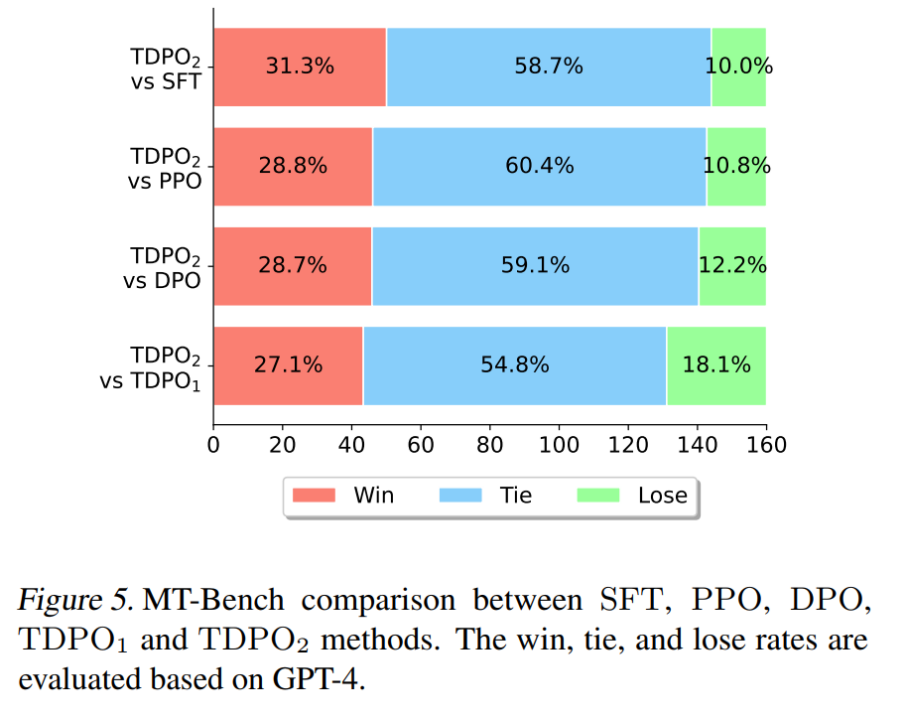
Sur MT-Bench, TDPO est capable d'atteindre une probabilité de gain plus élevée que les autres algorithmes, ce qui démontre pleinement la qualité supérieure des réponses générées par le modèle formé par l'algorithme TDPO.
De plus, il existe des études connexes comparant les algorithmes DPO, TDPO et SimPO. Veuillez vous référer au lien : https://www.zhihu.com/question/651021172/answer/3513696851
Basé sur le script d'évaluation fourni par. eurus, l'évaluation Les performances des modèles de base qwen-4b, mistral-0.1 et deepseek-math-base ont été obtenues par un entraînement de réglage fin basé sur différents algorithmes d'alignement DPO, TDPO et SimPO. Voici les résultats expérimentaux :
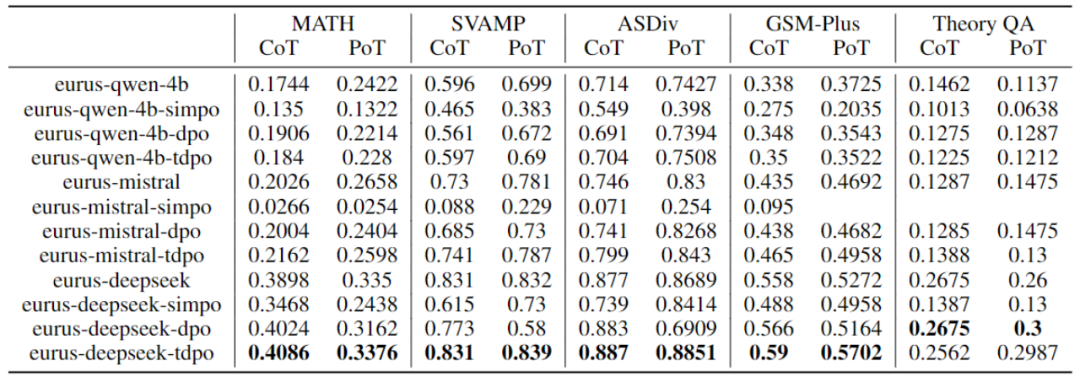
Tableau 2 : DPO, comparaison des performances des algorithmes TDPO et SimPO
Pour plus de résultats, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les dix meilleurs outils de développement que les ingénieurs de développement PHP apprécient le plus
- Les ingénieurs réseau peuvent-ils apprendre eux-mêmes ?
- Quelle est la différence entre un ingénieur logiciel et un programmeur ?
- Les ingénieurs logiciels sont-ils des programmeurs ?
- Que fait un ingénieur Big Data ?