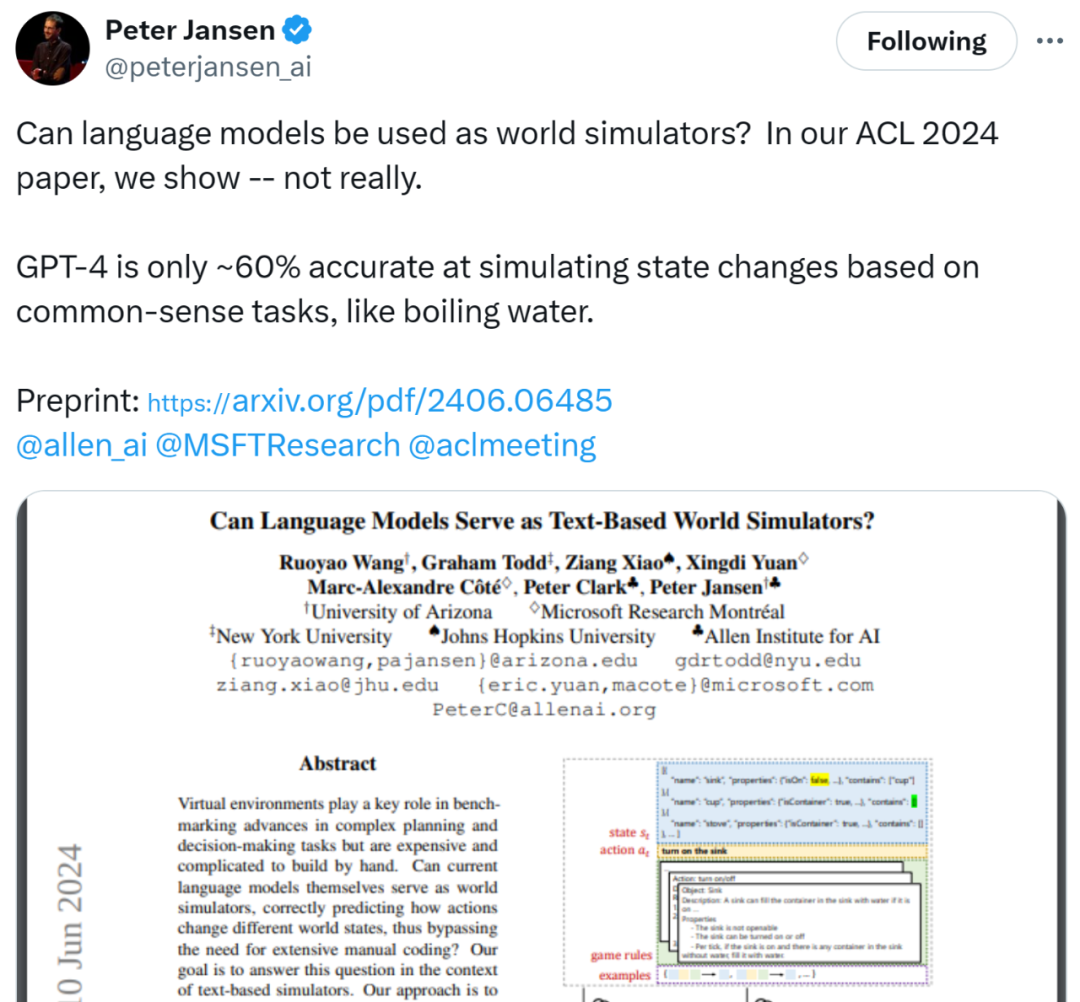
Si GPT-4 n'est précis qu'à environ 60 % lors de la simulation de changements d'état basés sur des tâches de bon sens, devrions-nous toujours envisager d'utiliser de grands modèles de langage comme simulateurs du monde ?
Au cours des deux derniers jours, un article sélectionné pour l'ACL 2024 "Les modèles linguistiques peuvent-ils servir de simulateurs mondiaux basés sur du texte ?" a suscité des discussions animées sur les réseaux sociaux X, et même Yann LeCun, lauréat du prix Turing, a également obtenu. impliqué. La question explorée dans cet article est la suivante : Les modèles de langage actuels peuvent-ils eux-mêmes agir comme des simulateurs du monde et prédire correctement comment les actions changent différents états du monde, évitant ainsi le besoin d'un codage manuel approfondi ? En réponse à ce problème, des chercheurs de l'Université de l'Arizona, de l'Université de New York, de l'Université Johns Hopkins, de Microsoft Research, de l'Allen Institute for Artificial Intelligence et d'autres institutions dans le contexte du « simulateur basé sur du texte ». Leurs réponses sont donné en . Ils croient : Les modèles linguistiques ne peuvent pas être utilisés comme simulateurs du monde. Par exemple, GPT-4 n’est précis qu’à environ 60 % lors de la simulation de changements d’état basés sur des tâches de bon sens telles que faire bouillir de l’eau.  Il a exprimé son accord et a estimé que "sans modèle mondial, il n'y a pas de plan
Il a exprimé son accord et a estimé que "sans modèle mondial, il n'y a pas de plan
". l'entraînement aux tâches) peut atteindre 60 %, cela ne signifie-t-il pas pour autant qu'ils sont au moins des « modèles mondiaux » dans une certaine mesure"? Et cela continuera à s'améliorer avec les itérations LLM. LeCun a également déclaré que le modèle mondial ne sera pas un LLM. De retour dans l'article, les chercheurs ont construit et utilisé un nouveau benchmark qu'ils ont appelé "ByteSized32-State-Prediction", qui contient un ensemble de données composé de transitions textuelles d'état de jeu et de tâches de jeu associées. Ils utilisent ce benchmark pour la première fois pour quantifier directement les performances des grands modèles de langage (LLM) en tant que simulateurs du monde basés sur du texte.
En testant GPT-4 sur cet ensemble de données, les chercheurs ont découvert que malgré ses performances impressionnantes, il reste un simulateur de monde peu fiable sans autre innovation.
Par conséquent, les chercheurs pensent que leurs travaux fournissent à la fois de nouvelles informations sur les capacités et les faiblesses des LLM actuels et une nouvelle référence pour suivre les progrès futurs à mesure que de nouveaux modèles émergent. Adresse papier : https://arxiv.org/pdf/2406.06485Les chercheurs ont exploré la capacité du LLM à agir comme un simulateur de monde dans un environnement virtuel basé sur du texte. Ici, dans cet environnement, un agent reçoit des observations et propose des actions en langage naturel pour atteindre un objectif. Chaque environnement textuel peut être formellement représenté comme un processus de décision de Markov partiellement observable (POMDP) conditionné par un objectif avec un 7-tuple (S,A,T,O,R,C,D), S représente Espace d'état, A représente l'espace d'action, T : S×A→S représente la fonction de transformation, O représente la fonction d'observation, R : S×A→R représente la fonction de récompense, C représente le "message contextuel" en langage naturel décrivant le sémantique de la cible et de l'action, D : S×A→{0,1} représente la fonction d'indicateur d'achèvement binaire. Tâche de simulation de grand modèle (LLM-Sim) pour servir de simulateurs fiables. La tâche LLM-Sim consiste à implémenter une fonction F : C×S×A→S×R×{0,1} en tant que simulateur de monde. En pratique, un simulateur complet de transition d'état F devrait considérer deux types de transitions d'état : les transitions pilotées par l'action et les transitions pilotées par l'environnement. La figure 1 est un exemple d'utilisation de LLM comme simulateur de jeu de texte : une fois l'évier ouvert, la tasse dans l'évier est remplie d'eau. La transition basée sur l'action est qu'après avoir effectué l'action pour ouvrir l'évier, l'évier est ouvert (isOn=true) tandis que la transition basée sur l'environnement est que lorsque l'évier est ouvert, l'eau remplit la tasse dans l'évier. Pour mieux comprendre la capacité du LLM à modéliser chaque transition, les chercheurs ont décomposé la fonction de simulation F en trois étapes : Simulateur de transition piloté par l'action : Étant donné c, s_t et a_t , F_act : C×S×A→S prédit s^act_t+1, où s^act_t+1 représente le changement d'état direct provoqué par l'action.
Simulateur de transition piloté par l'environnement : étant donné c et s^act_t+1, F_env : C×S→S prédit s_t+1, où s_t+1 est l'état résultant de toute transition pilotée par l'environnement.
- Game Progress Simulator : étant donné c, s_t+1 et a_t, F_R : C×S×A→R×{0,1} prédit la récompense r_t+1 et l'état d'achèvement du jeu d_t+1.
- De plus, les chercheurs ont envisagé deux variantes de la tâche LLM-Sim
Prédiction de l'état complet
: LLM génère l'état complet. Prédiction des différences d'état : LLM affiche uniquement la différence entre les états d'entrée et de sortie.
-
Données et évaluation
-
Pour accomplir cette tâche, les chercheurs ont introduit un nouvel ensemble de données de transition d'état de jeu de texte. L'ensemble de données est "BYTESIZED32-State-Prediction (BYTESIZED32-SP)", qui contient 76 369 transformations, exprimées sous la forme (c,s_t,rt,d_t,a_t,s^act_t+1,s_t+1,r_t+1 ,d_t +1) tuple
. Ces transitions ont été collectées à partir de 31 jeux de texte différents.
Le tableau 1 ci-dessous résume des statistiques supplémentaires sur le corpus. Les performances sur LLM-Sim sont déterminées par la précision de prédiction du modèle par rapport aux véritables étiquettes sur l'ensemble de données de l'échantillon de test. Selon les conditions expérimentales, LLM doit simuler les propriétés des objets (simulant F_act, F_env ou F) et/ou la progression du jeu (simulant F_R ou F), définies comme suit :
- Propriétés de l'objet : tous les objets dans le jeu, chacun Les propriétés d'un objet (telles que la température, la taille) et sa relation avec d'autres objets (telles que le fait d'être à l'intérieur ou sur un autre objet).
- Progression du jeu : Le statut de l'agent par rapport à l'objectif global, y compris les récompenses actuellement accumulées, si le jeu a été terminé et si l'objectif global a été atteint.
Les chercheurs ont remarqué que dans chaque cas, LLM fournissait la vérité terrain sur l'état précédent (lorsque la fonction est F_env, l'état précédent est s^act_t+1) ainsi que le contexte global de la tâche. Autrement dit, LLM effectue toujours une prédiction en une seule étape. La figure 1 ci-dessus démontre l'utilisation par le chercheur de l'apprentissage contextuel pour évaluer les performances du modèle dans la tâche LLM-Sim. Ils ont évalué l’exactitude de GPT-4 dans les mécanismes complets de prédiction de l’état et des différences d’état. Le modèle reçoit l'état précédent (codé sous forme d'objet JSON), les actions précédentes et les messages contextuels, et produit l'état suivant (sous forme d'objet JSON complet ou de différence). Le tableau 2 ci-dessous montre la précision de GPT-4 pour simuler des transitions d'état complètes, ainsi que pour simuler individuellement des transitions pilotées par l'action et des transitions pilotées par l'environnement.
Les chercheurs ont fait les découvertes importantes suivantes : Il est plus facile de prédire les conversions basées sur l'action que de prédire les conversions basées sur l'environnement. Dans le meilleur des cas, GPT-4 est capable de modéliser correctement 77,1 % des transitions dynamiques pilotées par des actions. En comparaison, GPT-4 simule correctement au plus 49,7 % des transformations dynamiques basées sur l'environnement. Il est plus facile de prédire les transitions statiques que les transitions dynamiques. Comme prévu, dans la plupart des cas, il est beaucoup plus facile de modéliser des transformations statiques que des transformations dynamiques. Pour les états dynamiques, il est plus facile de prédire l'état complet du jeu ; tandis que pour les états statiques, il est plus facile de prédire les différences d'état. La prévision des différences d'état dans les états dynamiques peut améliorer considérablement les performances (> 10 %) lors de la simulation de transitions statiques, tandis que les performances diminuent lors de la simulation de transitions dynamiques. Les règles du jeu sont très importantes, LLM peut générer des règles de jeu suffisamment bonnes. Lorsqu'aucune règle de jeu n'est fournie dans le message contextuel, les performances de GPT-4 sur les trois tâches de simulation se dégradent dans la plupart des cas. GPT-4 peut prédire la progression du jeu dans la plupart des cas. Le tableau 3 ci-dessous montre les résultats de GPT-4 prédisant la progression du jeu. Avec les informations sur les règles du jeu en contexte, GPT-4 peut prédire correctement la progression du jeu dans 92,1 % des cas de test. La présence de ces règles est cruciale dans le contexte : sans elles, la précision des prédictions de GPT-4 tombe à 61,5 %.
Les performances humaines sur les tâches LLM-Sim sont meilleures que celles de GPT-4. Les chercheurs ont mené des études préliminaires sur l’homme sur la tâche LLM-Sim. Les résultats sont présentés dans le tableau 4 ci-dessous. Il a été constaté que la précision globale des humains était de 80 %, tandis que la précision des LLM échantillonnés était de 50 %, avec peu de différence entre les différents annotateurs. Cela montre que même si la tâche est généralement intuitive et relativement facile pour les humains, il reste encore beaucoup à faire pour les LLM.
GPT-4 est plus sujet aux erreurs lorsque des connaissances arithmétiques, de bon sens ou scientifiques sont requises. La figure 2 ci-dessous montre la proportion de résultats prédits qui étaient corrects, la proportion qui a défini l'attribut sur une valeur incorrecte ou la proportion qui n'a pas réussi à modifier la valeur de l'attribut pour les transitions d'état globales, les transitions pilotées par l'action et les transitions pilotées par l'environnement. Nous pouvons observer que GPT-4 est capable de très bien gérer la plupart des attributs booléens simples. Les erreurs se regroupent autour de propriétés non triviales qui nécessitent des connaissances arithmétiques (par exemple, température, timeAboveMaxTemp), du bon sens (par exemple, current_aperture, current_focus) ou des connaissances scientifiques (par exemple, on).
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn


 Il a exprimé son accord et a estimé que "sans modèle mondial, il n'y a pas de plan
Il a exprimé son accord et a estimé que "sans modèle mondial, il n'y a pas de plan  De retour dans l'article, les chercheurs ont construit et utilisé un nouveau benchmark qu'ils ont appelé "ByteSized32-State-Prediction", qui contient un ensemble de données composé de transitions textuelles d'état de jeu et de tâches de jeu associées. Ils utilisent ce benchmark pour la première fois pour quantifier directement les performances des grands modèles de langage (LLM) en tant que simulateurs du monde basés sur du texte.
De retour dans l'article, les chercheurs ont construit et utilisé un nouveau benchmark qu'ils ont appelé "ByteSized32-State-Prediction", qui contient un ensemble de données composé de transitions textuelles d'état de jeu et de tâches de jeu associées. Ils utilisent ce benchmark pour la première fois pour quantifier directement les performances des grands modèles de langage (LLM) en tant que simulateurs du monde basés sur du texte.  En testant GPT-4 sur cet ensemble de données, les chercheurs ont découvert que malgré ses performances impressionnantes, il reste un simulateur de monde peu fiable sans autre innovation.
En testant GPT-4 sur cet ensemble de données, les chercheurs ont découvert que malgré ses performances impressionnantes, il reste un simulateur de monde peu fiable sans autre innovation. 




