
Maison >Périphériques technologiques >IA >Comment télécharger et installer Llama 2 localement
Comment télécharger et installer Llama 2 localement

- WBOYoriginal
- 2024-06-14 20:33:401015parcourir
Dans cet esprit, nous avons créé un guide étape par étape sur la façon d'utiliser Text-Generation-WebUI pour charger un Llama 2 LLM quantifié localement sur votre ordinateur.
Pourquoi installer Llama 2 localement
Il existe de nombreuses raisons pour lesquelles les gens choisissent d'exécuter Llama 2 directement. Certains le font pour des raisons de confidentialité, d’autres pour la personnalisation et d’autres pour des fonctionnalités hors ligne. Si vous recherchez, peaufinez ou intégrez Llama 2 pour vos projets, accéder à Llama 2 via l'API n'est peut-être pas pour vous. L’intérêt d’exécuter un LLM localement sur votre PC est de réduire le recours aux outils d’IA tiers et d’utiliser l’IA à tout moment et en tout lieu, sans vous soucier de la fuite de données potentiellement sensibles vers des entreprises et d’autres organisations.
Cela dit, commençons par le guide étape par étape pour installer Llama 2 localement.
Étape 1 : Installer Visual Studio 2019 Build Tool
Pour simplifier les choses, nous utiliserons un programme d'installation en un clic pour Text-Generation-WebUI (le programme utilisé pour charger Llama 2 avec l'interface graphique). Cependant, pour que ce programme d'installation fonctionne, vous devez télécharger l'outil de génération Visual Studio 2019 et installer les ressources nécessaires.
Télécharger : Visual Studio 2019 (Gratuit)
Allez-y et téléchargez l'édition communautaire du logiciel. Installez maintenant Visual Studio 2019, puis ouvrez le logiciel. Une fois ouvert, cochez la case Développement de bureau avec C++ et cliquez sur Installer.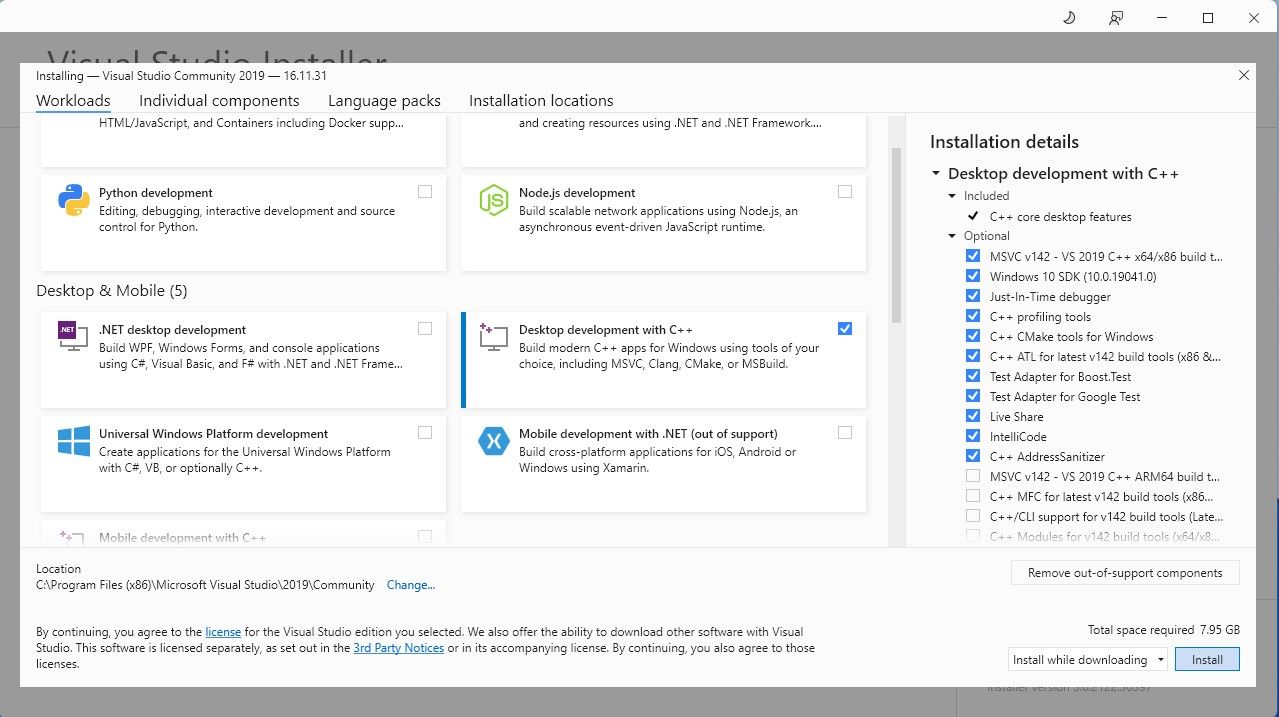
Maintenant que le développement de bureau avec C++ est installé, il est temps de télécharger le programme d'installation en un clic de Text-Generation-WebUI.
Étape 2 : Installer Text-Generation-WebUI
Le programme d'installation en un clic de Text-Generation-WebUI est un script qui crée automatiquement les dossiers requis et configure l'environnement Conda et toutes les exigences nécessaires pour exécuter un modèle d'IA.
Pour installer le script, téléchargez le programme d'installation en un clic en cliquant sur Code > Téléchargez le ZIP.
Télécharger : Text-Generation-WebUI Installer (gratuit)
Une fois téléchargé, extrayez le fichier ZIP à votre emplacement préféré, puis ouvrez le dossier extrait. Dans le dossier, faites défiler vers le bas et recherchez le programme de démarrage approprié pour votre système d'exploitation. Exécutez les programmes en double-cliquant sur le script approprié. Si vous êtes sous Windows, sélectionnez le fichier batch start_windows pour MacOS, sélectionnez le script shell start_macos pour Linux, le script shell start_linux.
Votre antivirus peut créer une alerte ; c'est bon. L'invite n'est qu'un faux positif antivirus pour l'exécution d'un fichier batch ou d'un script. Cliquez quand même sur Exécuter. Un terminal s'ouvrira et démarrera la configuration. Au début, l'installation s'arrêtera et vous demandera quel GPU vous utilisez. Sélectionnez le type approprié de GPU installé sur votre ordinateur et appuyez sur Entrée. Pour ceux qui n'ont pas de carte graphique dédiée, sélectionnez Aucune (je souhaite exécuter des modèles en mode CPU). Gardez à l'esprit que l'exécution en mode CPU est beaucoup plus lente que l'exécution du modèle avec un GPU dédié.
 Une fois la configuration terminée, vous pouvez maintenant lancer Text-Generation-WebUI localement. Vous pouvez le faire en ouvrant votre navigateur Web préféré et en saisissant l'adresse IP fournie sur l'URL.
Une fois la configuration terminée, vous pouvez maintenant lancer Text-Generation-WebUI localement. Vous pouvez le faire en ouvrant votre navigateur Web préféré et en saisissant l'adresse IP fournie sur l'URL. Le WebUI est maintenant prêt à être utilisé.
Le WebUI est maintenant prêt à être utilisé.
Cependant, le programme n'est qu'un chargeur de modèles. Téléchargeons Llama 2 pour que le chargeur de modèles puisse être lancé.
Étape 3 : Téléchargez le modèle Llama 2
Il y a de nombreux éléments à prendre en compte pour décider de quelle itération de Llama 2 vous avez besoin. Ceux-ci incluent les paramètres, la quantification, l’optimisation matérielle, la taille et l’utilisation. Toutes ces informations seront indiquées dans le nom du modèle.
Paramètres : nombre de paramètres utilisés pour entraîner le modèle. Des paramètres plus importants créent des modèles plus performants, mais au détriment des performances. Utilisation : Peut être standard ou chat. Un modèle de chat est optimisé pour être utilisé comme chatbot comme ChatGPT, tandis que le modèle standard est le modèle par défaut. Optimisation matérielle : fait référence au matériel qui exécute le mieux le modèle. GPTQ signifie que le modèle est optimisé pour fonctionner sur un GPU dédié, tandis que GGML est optimisé pour fonctionner sur un CPU. Quantification : désigne la précision des poids et des activations dans un modèle. Pour l'inférence, une précision de q4 est optimale. Taille : fait référence à la taille du modèle spécifique.Notez que certains modèles peuvent être disposés différemment et peuvent même ne pas afficher les mêmes types d'informations. Cependant, ce type de convention de dénomination est assez courant dans la bibliothèque de modèles HuggingFace, il vaut donc toujours la peine d'être compris.

Dans cet exemple, le modèle peut être identifié comme un modèle Llama 2 de taille moyenne entraîné sur 13 milliards de paramètres optimisés pour l'inférence de chat à l'aide d'un processeur dédié.
Pour ceux qui fonctionnent sur un GPU dédié, choisissez un modèle GPTQ, tandis que pour ceux qui utilisent un CPU, choisissez GGML. Si vous souhaitez discuter avec le modèle comme vous le feriez avec ChatGPT, choisissez le chat, mais si vous souhaitez expérimenter le modèle avec toutes ses capacités, utilisez le modèle standard. Quant aux paramètres, sachez que l’utilisation de modèles plus gros donnera de meilleurs résultats au détriment des performances. Je vous recommanderais personnellement de commencer avec un modèle 7B. Quant à la quantification, utilisez q4, car c'est uniquement à des fins d'inférence.
Télécharger : GGML (gratuit)
Télécharger : GPTQ (gratuit)
Maintenant que vous savez de quelle itération de Llama 2 vous avez besoin, allez-y et téléchargez le modèle que vous souhaitez.
Dans mon cas, puisque j'utilise cela sur un ultrabook, j'utiliserai un modèle GGML affiné pour le chat, lama-2-7b-chat-ggmlv3.q4_K_S.bin.
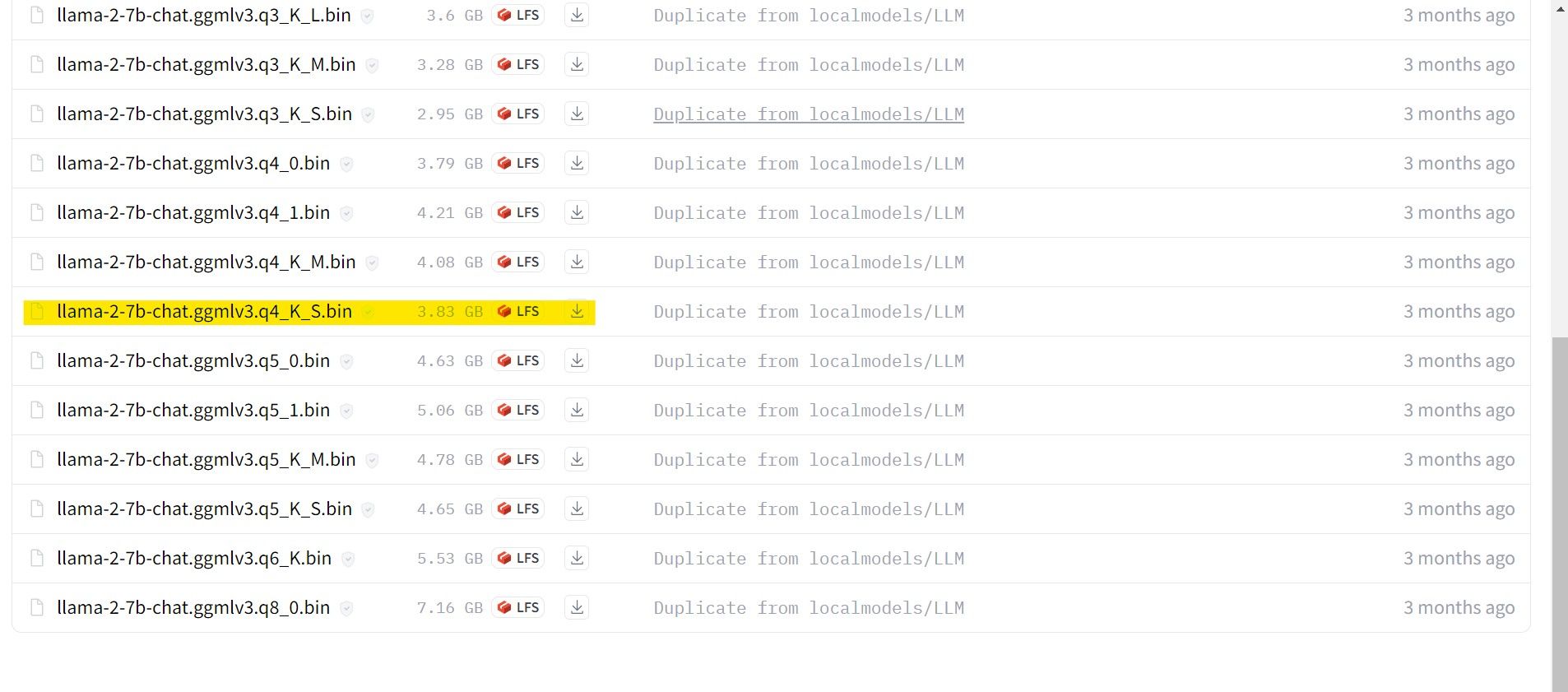
Une fois le téléchargement terminé, placez le modèle dans text-generation-webui-main > des modèles.

Maintenant que votre modèle est téléchargé et placé dans le dossier modèle, il est temps de configurer le chargeur de modèle.
Étape 4 : Configurer Text-Generation-WebUI
Maintenant, commençons la phase de configuration.
Encore une fois, ouvrez Text-Generation-WebUI en exécutant le fichier start_(votre système d'exploitation) (voir les étapes précédentes ci-dessus). Dans les onglets situés au-dessus de l'interface graphique, cliquez sur Modèle. Cliquez sur le bouton Actualiser dans le menu déroulant du modèle et sélectionnez votre modèle. Cliquez maintenant sur le menu déroulant du chargeur de modèle et sélectionnez AutoGPTQ pour ceux qui utilisent un modèle GTPQ et ctransformers pour ceux qui utilisent un modèle GGML. Enfin, cliquez sur Charger pour charger votre modèle. Pour utiliser le modèle, ouvrez l'onglet Chat et commencez à tester le modèle.
Pour utiliser le modèle, ouvrez l'onglet Chat et commencez à tester le modèle.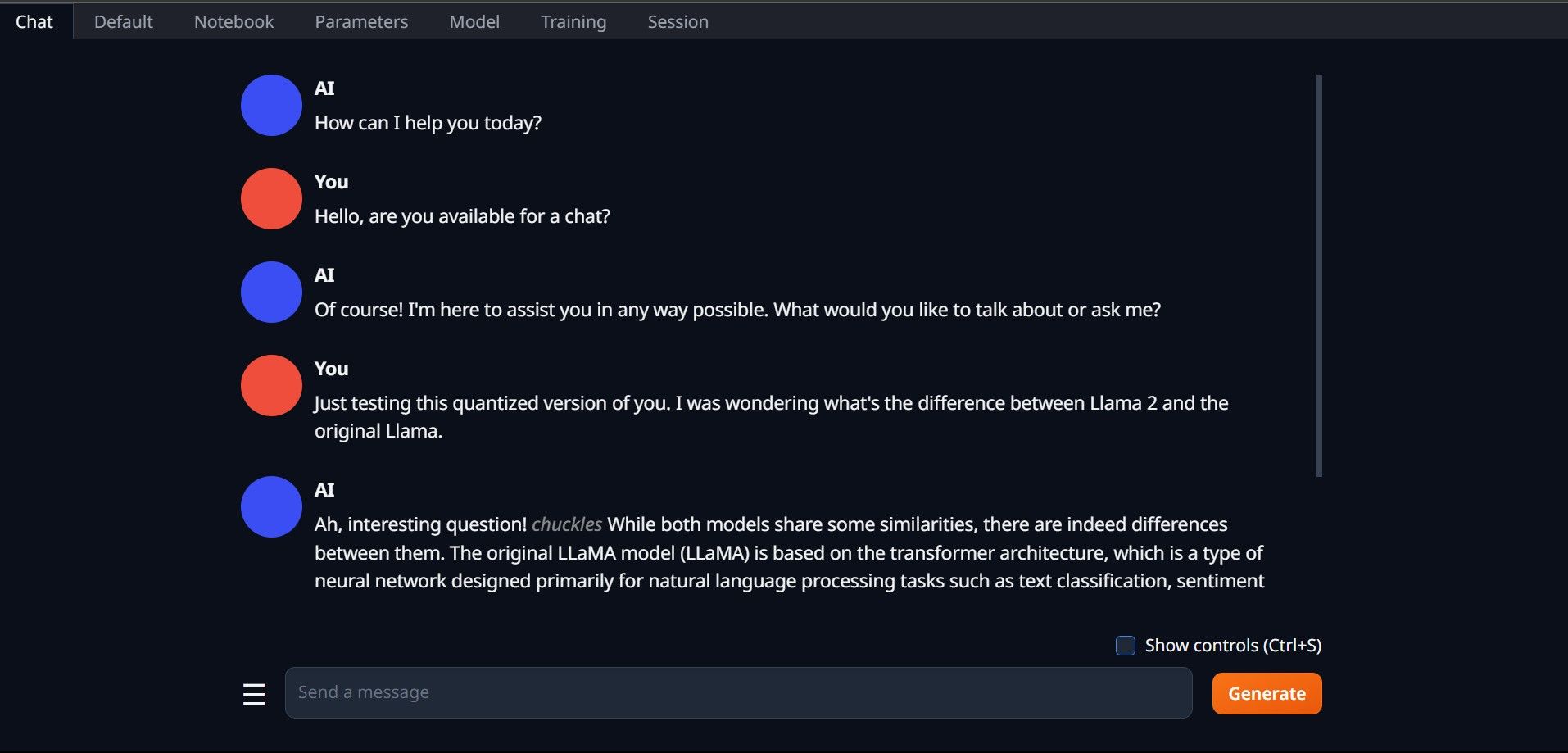
Félicitations, vous avez chargé avec succès Llama2 sur votre ordinateur local !
Essayez d'autres LLM
Maintenant que vous savez comment exécuter Llama 2 directement sur votre ordinateur à l'aide de Text-Generation-WebUI, vous devriez également pouvoir exécuter d'autres LLM en plus de Llama. N'oubliez pas les conventions de dénomination des modèles et que seules les versions quantifiées des modèles (généralement une précision q4) peuvent être chargées sur des PC classiques. De nombreux LLM quantifiés sont disponibles sur HuggingFace. Si vous souhaitez explorer d'autres modèles, recherchez TheBloke dans la bibliothèque de modèles de HuggingFace et vous devriez trouver de nombreux modèles disponibles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI