
Maison >Périphériques technologiques >IA >Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-11 17:29:581156parcourir
Écrit ci-dessus et compréhension personnelle de l'auteur
Récemment, avec le développement et les percées de la technologie d'apprentissage en profondeur, les modèles de base à grande échelle ont obtenu des résultats significatifs dans les domaines du traitement du langage naturel et de la vision par ordinateur. L’application de modèles de base à la conduite autonome présente également de grandes perspectives de développement, susceptibles d’améliorer la compréhension et le raisonnement des scénarios.
- Grâce à une pré-formation sur un langage riche et des données visuelles, le modèle de base peut comprendre et interpréter divers éléments des scénarios de conduite autonome et effectuer un raisonnement, fournissant un langage et des commandes d'action pour piloter la prise de décision et la planification.
- Le modèle de base peut améliorer les données sur la base de la compréhension des scénarios de conduite et est utilisé pour fournir les rares scénarios réalisables dans des distributions à longue traîne qui sont peu susceptibles d'être rencontrés lors d'une conduite régulière et de la collecte de données afin d'améliorer la précision du système de conduite autonome. et à des fins de fiabilité.
- Un autre scénario pour appliquer les modèles de base est le modèle mondial, qui démontre la capacité à comprendre les lois physiques et les choses dynamiques. En utilisant un paradigme d'apprentissage auto-supervisé pour apprendre à partir de données massives, le modèle mondial peut générer des scènes de conduite invisibles mais crédibles, promouvoir l'amélioration de la prédiction dynamique du comportement des objets et le processus de formation hors ligne des stratégies de conduite.
Cet article décrit principalement l'application du modèle de base dans le domaine de la conduite autonome, et sur la base de l'application du modèle de base dans le modèle de conduite autonome, l'application du modèle de base dans l'amélioration des données et l'application du modèle mondial dans le modèle de base en conduite autonome. Développer en termes d'aspects. En termes de modèles de conduite autonome, les modèles de base peuvent être utilisés pour mettre en œuvre diverses fonctions de conduite autonome, telles que la perception, la prise de décision et le contrôle du véhicule. Grâce au modèle de base, le véhicule peut obtenir des informations sur l'environnement et prendre les décisions et actions de contrôle correspondantes. En termes d'amélioration des données, le modèle de base peut être utilisé pour améliorer les données
Lien vers cet article : https://arxiv.org/pdf/2405.02288
Modèle de conduite autonome
Conduite de type humain basée sur le langage et modèles de base visuels
Dans la conduite autonome, les modèles de base du langage et de la vision ont montré un grand potentiel d'application en améliorant la compréhension et le raisonnement des modèles de conduite autonome dans des scénarios de conduite, il est possible d'obtenir une conduite autonome de type humain. La figure ci-dessous montre la compréhension de la scène de conduite par le modèle de base basé sur le langage et la vision et le raisonnement consistant à donner des instructions et un comportement de conduite guidés par le langage.
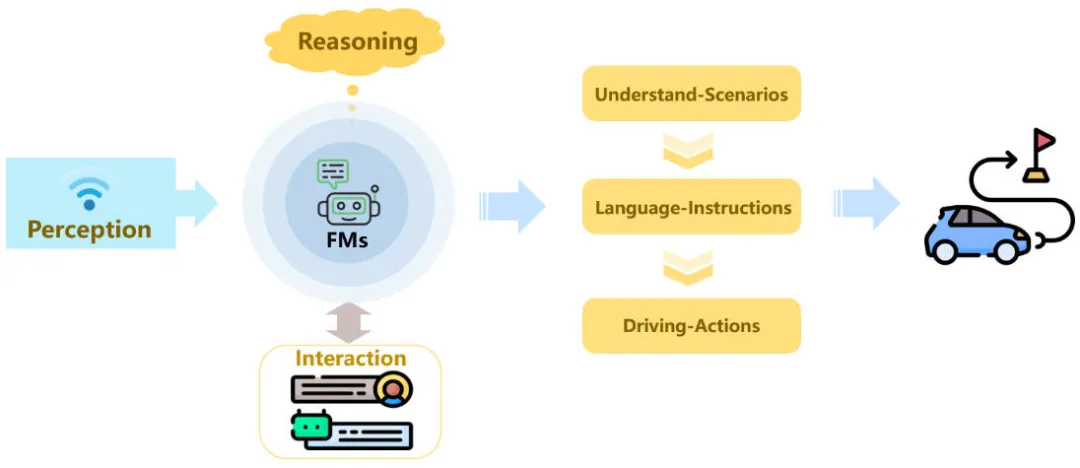
Le modèle de base améliore le paradigme des modèles de conduite autonomes
De nombreux travaux ont prouvé que le langage et les caractéristiques visuelles peuvent améliorer efficacement la compréhension du modèle de la scène de conduite. Après avoir obtenu la compréhension perceptuelle globale de l'environnement actuel, le modèle de base. donnera une série de commandes linguistiques, telles que : "Il y a un feu rouge devant, ralentissez et conduisez lentement", "Il y a un carrefour devant, faites attention aux piétons" et d'autres commandes linguistiques associées, afin que la conduite autonome la voiture peut effectuer le comportement de conduite final selon les commandes linguistiques pertinentes.
Ces dernières années, le monde universitaire et l’industrie ont intégré les connaissances linguistiques de GPT dans le processus décisionnel en matière de conduite autonome. Améliorer les performances de la conduite autonome sous forme de commandes linguistiques pour promouvoir les applications dans la conduite autonome de grands modèles. Étant donné que le grand modèle devrait être véritablement déployé côté véhicule, il doit en fin de compte dépendre d'instructions de planification ou de contrôle, et le modèle de base devrait en fin de compte autoriser la conduite autonome à partir du niveau de l'état d'action. Certains chercheurs ont procédé à des explorations préliminaires, mais il reste encore beaucoup à faire. Plus important encore, certains chercheurs ont exploré la construction de modèles de conduite autonome grâce à une méthode similaire à GPT, qui génère directement des trajectoires basées sur des modèles de langage à grande échelle, puis les implémente via des commandes de contrôle. Les travaux connexes ont été résumés dans le tableau suivant.
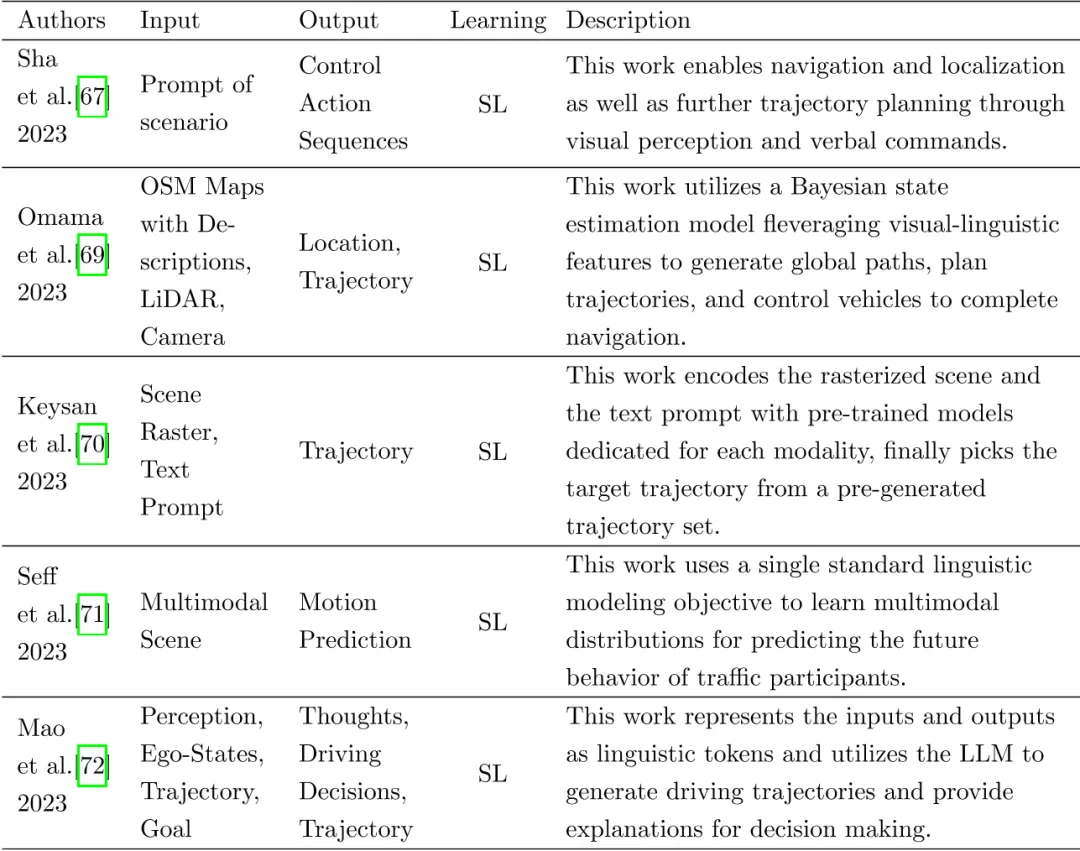
Utilisez un réseau fédérateur pré-entraîné pour la conduite autonome de bout en bout
L'idée principale du contenu connexe ci-dessus est d'améliorer l'interprétabilité des décisions de conduite autonome, d'améliorer la compréhension et l'analyse des scènes, et guider la planification ou le contrôle du système de conduite autonome. Au cours de la dernière période, de nombreux travaux ont été réalisés pour optimiser le réseau fédérateur du modèle pré-entraîné de diverses manières et ont obtenu de très bons résultats. Par conséquent, afin de résumer de manière plus complète l'application des modèles de base à la conduite autonome, nous résumons et examinons le réseau fédérateur pré-entraîné et les recherches qui ont obtenu de très bons résultats. La figure ci-dessous montre le processus global de conduite autonome de bout en bout.

Organigramme d'un système de conduite autonome de bout en bout basé sur un réseau fédérateur pré-entraîné
Dans le processus global de conduite autonome de bout en bout, l'extraction d'informations de bas niveau à partir de données brutes détermine dans une certaine mesure le potentiel des performances ultérieures du modèle. Une excellente base de pré-entraînement peut donner au modèle des capacités d'apprentissage de fonctionnalités plus fortes. Les réseaux convolutifs pré-entraînés tels que ResNet et VGG sont les réseaux fédérateurs les plus largement utilisés pour l'extraction de caractéristiques visuelles de modèles de bout en bout. Ces réseaux pré-entraînés sont généralement formés en utilisant la détection ou la segmentation d'objets comme tâche d'extraction de caractéristiques généralisées, et les performances qu'ils atteignent ont été vérifiées dans de nombreux travaux.
De plus, les premiers modèles de conduite autonome de bout en bout étaient principalement basés sur divers types de réseaux neuronaux convolutifs et étaient complétés par un apprentissage par imitation ou un apprentissage par renforcement. Certains travaux récents ont tenté de construire un système de conduite autonome de bout en bout avec une structure de réseau Transformer et ont également obtenu des résultats relativement bons, comme Transfuser, FusionAD, UniAD et d'autres travaux.
Amélioration des données
Avec le développement ultérieur de la technologie d'apprentissage en profondeur et la poursuite de l'amélioration et de la mise à niveau de l'architecture réseau sous-jacente, le modèle de base avec pré-formation et réglage fin a montré des performances de plus en plus puissantes. Le modèle de base représenté par GPT a permis la transformation de grands modèles des règles du paradigme d'apprentissage vers une approche basée sur les données. L’importance des données en tant que maillon clé de l’apprentissage des modèles est irremplaçable. Lors de la formation et des tests des modèles de conduite autonome, une grande quantité de données de scène est utilisée pour permettre au modèle d'avoir de bonnes capacités de compréhension et de prise de décision pour divers scénarios de route et de trafic. Le problème à longue traîne auquel est confrontée la conduite autonome réside également dans le fait qu'il existe une infinité de scénarios de bord inconnus, ce qui donne l'impression que la capacité de généralisation du modèle n'est jamais suffisante, ce qui entraîne de mauvaises performances.
L'augmentation des données est cruciale pour améliorer la capacité de généralisation des modèles de conduite autonome. La mise en œuvre de l'augmentation des données doit considérer deux aspects
- D'une part : comment obtenir des données à grande échelle afin que les données fournies au modèle de conduite autonome soient suffisamment diverses et étendues
- D'autre part : comment obtenir autant de données que possible Les données de haute qualité, utilisées pour la formation et les tests de modèles de conduite autonome, sont précises et fiables
Par conséquent, les travaux de recherche connexes effectuent principalement des recherches techniques liées aux deux aspects ci-dessus. L'un consiste à enrichir le contenu des données. dans l'ensemble de données existant et améliore les caractéristiques des données dans les scénarios de conduite. La seconde consiste à générer des scénarios de conduite à plusieurs niveaux grâce à la simulation.
Extension des ensembles de données de conduite autonome
Les ensembles de données de conduite autonome existants sont principalement obtenus en enregistrant les données des capteurs, puis en étiquetant les données. Les caractéristiques des données obtenues de cette manière sont généralement de très bas niveau et l'ampleur de l'ensemble de données est également relativement faible, ce qui est totalement insuffisant pour l'espace des caractéristiques visuelles des scénarios de conduite autonome. Les capacités avancées de compréhension sémantique, de raisonnement et d'interprétation du modèle de base représenté par le modèle de langage fournissent de nouvelles idées et approches techniques pour l'enrichissement et l'expansion des ensembles de données de conduite autonome. L'élargissement de l'ensemble de données en tirant parti des capacités avancées de compréhension, de raisonnement et d'interprétation du modèle sous-jacent peut aider à mieux évaluer l'explicabilité et le contrôle des systèmes de conduite autonome, améliorant ainsi la sécurité et la fiabilité des systèmes de conduite autonome.
Générer des scènes de conduite
Les scènes de conduite sont d'une grande importance pour la conduite autonome. Afin d'obtenir différentes données de scène de conduite, s'appuyer uniquement sur les capteurs du véhicule pour la collecte en temps réel nécessite des coûts énormes, et il est difficile d'obtenir suffisamment de données de scène pour certaines scènes périphériques. La génération de scènes de conduite réalistes grâce à la simulation a attiré l'attention de nombreux chercheurs. La recherche sur la simulation du trafic est principalement divisée en deux catégories : basée sur des règles et basée sur des données.
- Approche basée sur des règles : utilisez des règles prédéfinies, qui sont souvent insuffisantes pour décrire des scénarios de conduite complexes, et les scénarios de conduite simulés sont plus simples et plus généraux
- Approche basée sur les données : utilisez les données de conduite pour entraîner le modèle, le modèle peut apprendre et s’adapter continuellement. Cependant, les méthodes basées sur les données nécessitent généralement une grande quantité de données étiquetées pour la formation, ce qui entrave le développement ultérieur de la simulation du trafic. Avec le développement de la technologie, la méthode actuelle de génération de données est progressivement passée d'une méthode basée sur des règles à une méthode basée sur les données. méthode pilotée. En simulant efficacement et précisément des scénarios de conduite, y compris diverses situations complexes et dangereuses, une grande quantité de données de formation est fournie pour l'apprentissage de modèles, ce qui peut améliorer efficacement la capacité de généralisation du système de conduite autonome. Dans le même temps, les scénarios de conduite générés peuvent également être utilisés pour évaluer différents systèmes et algorithmes de conduite autonome afin de tester et de vérifier les performances du système. Le tableau ci-dessous est un résumé des différentes stratégies d’augmentation des données.
Résumé des différentes stratégies d'augmentation des données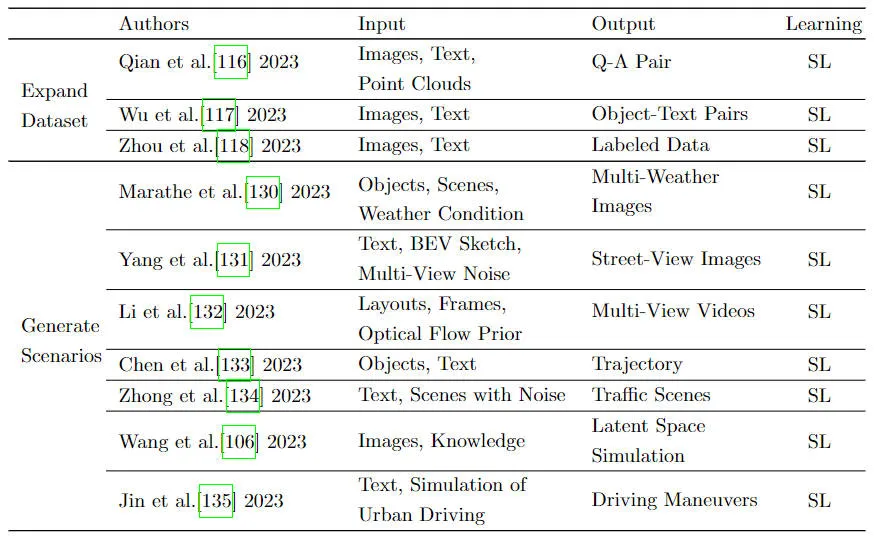
Modèle mondial
Un modèle mondial est considéré comme un modèle d'intelligence artificielle qui contient une compréhension ou une représentation globale de l'environnement dans lequel il opère. Le modèle est capable de simuler l’environnement pour faire des prédictions ou des décisions. Dans la littérature récente, le terme « modèle mondial » est évoqué dans le contexte de l’apprentissage par renforcement. Ce concept gagne également du terrain dans les applications de conduite autonome en raison de sa capacité à comprendre et à élucider la dynamique de l’environnement de conduite. Les modèles mondiaux sont étroitement liés à l’apprentissage par renforcement, à l’apprentissage par imitation et aux modèles génératifs profonds. Cependant, l'utilisation de modèles mondiaux dans l'apprentissage par renforcement et l'apprentissage par imitation nécessite généralement des données bien étiquetées, et des méthodes telles que SEM2 et MILE sont appliquées dans le paradigme supervisé. Dans le même temps, il existe également des tentatives pour combiner l’apprentissage par renforcement et l’apprentissage non supervisé en s’appuyant sur les limites des données étiquetées. En raison de leur association étroite avec l’apprentissage auto-supervisé, les modèles génératifs profonds sont devenus de plus en plus populaires et de nombreux travaux ont été proposés. La figure ci-dessous montre l'organigramme global de l'utilisation du modèle mondial pour améliorer le modèle de conduite autonome.
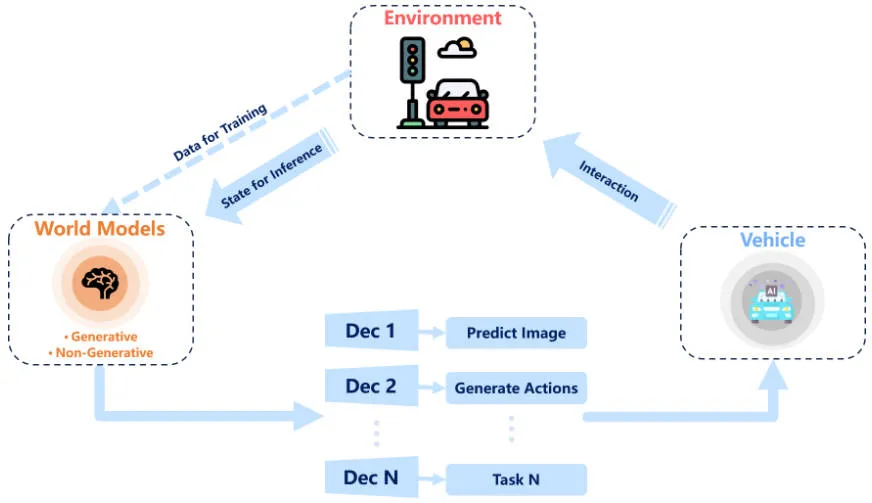
Organigramme global pour l'amélioration du modèle de conduite autonome du modèle mondial
Modèle génératif profond
Les modèles génératifs profonds incluent généralement des auto-encodeurs variationnels, des réseaux antagonistes génératifs, des modèles de flux et des modèles autorégressifs.
- Les auto-encodeurs variationnels combinent les idées des auto-encodeurs et des modèles graphiques probabilistes pour apprendre la structure sous-jacente des données et générer de nouveaux échantillons
- Les réseaux contradictoires génératifs se composent de deux réseaux neuronaux, un générateur et un discriminateur, qui utilisent l'adversité. Les formations rivalisent et améliorent
- Le modèle de flux convertit une distribution a priori simple en une distribution postérieure complexe grâce à une série de transformations réversibles pour générer des échantillons de données similaires
- Un modèle autorégressif est un type de séquence L'analyse La méthode, basée sur l'autocorrélation entre les données de séquence, décrit la relation entre les observations actuelles et les observations passées. L'estimation des paramètres du modèle est généralement effectuée à l'aide de la méthode des moindres carrés et de l'estimation du maximum de vraisemblance. Le modèle de diffusion est un modèle autorégressif typique qui apprend un processus de débruitage par étapes à partir de données de bruit pur. En raison de ses puissantes performances génératives, le modèle de diffusion est un nouveau modèle SOTA parmi les modèles génératifs profonds actuels
Méthodes génératives
Basés sur la puissante capacité des modèles génératifs profonds, les modèles génératifs profonds sont utilisés comme modèles mondiaux pour apprendre à conduire des scénarios pour améliorer la conduite automatique sont progressivement devenus un point chaud de la recherche. Nous examinons ensuite l'utilisation de modèles génératifs profonds comme modèles mondiaux dans la conduite autonome. La vision est l’un des moyens les plus directs et les plus efficaces permettant aux humains d’obtenir des informations sur le monde, car les données d’image contiennent des informations extrêmement riches sur les caractéristiques. De nombreux travaux antérieurs ont complété la tâche de génération d'images à travers des modèles mondiaux, montrant que les modèles mondiaux ont de bonnes capacités de compréhension et de raisonnement pour les données d'image. Dans l’ensemble, les chercheurs espèrent apprendre les lois évolutives inhérentes au monde à partir de données d’images, puis prédire les états futurs. Combiné à l'apprentissage auto-supervisé, le modèle mondial est utilisé pour apprendre à partir des données d'image, libérant ainsi pleinement les capacités de raisonnement du modèle et fournissant une direction réalisable pour construire un modèle de base généralisé dans le domaine visuel. La figure ci-dessous montre un résumé de certains travaux connexes utilisant des modèles mondiaux.
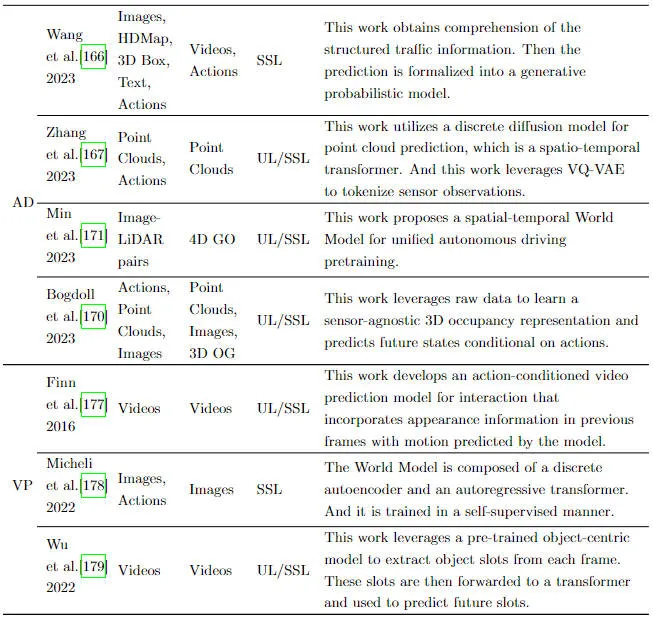
Un résumé des travaux utilisant des modèles mondiaux pour la prédiction
Méthodes non génératives
Par rapport aux modèles mondiaux génératifs, LeCun a développé ses différences dans les modèles mondiaux en proposant le concept Joint Extraction and Prediction Architecture (JEPA) . Il s'agit d'une architecture non générative et auto-supervisée car elle ne prédit pas la sortie directement sur la base des données d'entrée, mais code les données d'entrée dans un espace abstrait pour compléter la prédiction finale. L’avantage de cette méthode de prédiction est qu’elle ne nécessite pas de prédire toutes les informations sur le résultat et peut éliminer les détails non pertinents.
JEPA est une architecture d'apprentissage auto-supervisée basée sur des modèles énergétiques, qui observe et apprend le fonctionnement du monde et des lois hautement généralisées. JEPA présente également un grand potentiel en matière de conduite autonome et devrait générer des scénarios de conduite et des stratégies de conduite de haute qualité en apprenant comment fonctionne la conduite.
Conclusion
Cet article donne un aperçu complet du rôle important des modèles de base dans les applications de conduite autonome. À en juger par le résumé et les résultats des travaux de recherche pertinents examinés dans cet article, une autre direction méritant d'être explorée plus avant est la manière de concevoir une architecture de réseau efficace pour l'apprentissage auto-supervisé. L'apprentissage auto-supervisé peut efficacement dépasser les limites de l'annotation des données, permettant au modèle d'apprendre des données à grande échelle et de libérer pleinement les capacités de raisonnement du modèle. Si le modèle de base de la conduite autonome peut être formé à l’aide de différentes échelles de données de scènes de conduite dans le cadre d’un paradigme d’apprentissage auto-supervisé, sa capacité de généralisation devrait être considérablement améliorée. De telles avancées pourraient permettre un modèle de base plus général.
En bref, bien que l'application du modèle de base à la conduite autonome présente de nombreux défis, son espace d'application et ses perspectives de développement sont très larges. Dans le futur, nous continuerons d’observer les progrès des modèles de base appliqués à la conduite autonome.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que l'architecture BS
- L'infrastructure Big Data est construite sous la forme d'une architecture technologique de pile, comprenant ce qui
- Exemples pour expliquer le sens et la répartition des responsabilités de l'architecture MVC
- Que comprend l'architecture Golang ?
- Un aperçu des trois architectures de puces traditionnelles pour la conduite autonome dans un seul article