
Maison >Périphériques technologiques >IA >Utilisez NVIDIA Riva pour déployer rapidement des services d'IA vocale chinoise au niveau de l'entreprise, puis les optimiser et les accélérer.
Utilisez NVIDIA Riva pour déployer rapidement des services d'IA vocale chinoise au niveau de l'entreprise, puis les optimiser et les accélérer.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-10 21:57:481230parcourir
1. Présentation de Riva
1. Présentation

Riva est un SDK lancé par NVIDIA pour les services d'IA vocale en temps réel. Il s'agit d'un outil hautement personnalisable qui utilise l'accélération GPU. De nombreux modèles pré-entraînés sont fournis sur NGC. Ces modèles sont prêts à l'emploi et peuvent être déployés directement à l'aide des solutions ASR et TTS fournies par Riva.
Afin de répondre aux besoins de domaines spécifiques ou de développer des fonctions personnalisées, les utilisateurs peuvent également utiliser NeMo pour recycler ou affiner ces modèles. Cela améliore encore les performances du modèle et le rend plus adaptable aux besoins des utilisateurs.
Riva+Skills est un outil hautement personnalisable qui exploite le GPU pour accélérer la reconnaissance vocale et la synthèse vocale en streaming en temps réel, et peut gérer simultanément des milliers de requêtes simultanées. Il prend en charge plusieurs plates-formes de déploiement, notamment locales, cloud et finales.
2. Riva ASR

En termes de reconnaissance vocale, Riva utilise des modèles SOTA très précis, tels que Citrinet, Conformer et FastConformer auto-développé par NeMo. Actuellement, Riva prend en charge plus de 10 modèles monolingues et prend également en charge la reconnaissance vocale multilingue, notamment la reconnaissance vocale anglais-espagnol, anglais-chinois et anglais-japonais.
Grâce à des fonctions personnalisées, la précision du modèle peut être encore améliorée. Par exemple, la prise en charge de terminologies, d'accents ou de dialectes spécifiques au secteur, ainsi que la personnalisation pour les environnements bruyants peuvent contribuer à améliorer les performances de reconnaissance vocale.
Le cadre global de Riva peut être appliqué à une variété de scénarios, tels que le service client et les systèmes de conférence. En plus des scénarios généraux, les services de Riva peuvent également être personnalisés en fonction des besoins de différents secteurs, tels que le CSP, l'éducation, la finance et d'autres secteurs.
3. Pipeline ASR et personnalisation
Dans l'ensemble du processus de Riva ASR, il existe des modules personnalisables, qui peuvent être divisés en trois catégories en fonction de la difficulté.

Tout d'abord, la case orange est la personnalisation qui peut être effectuée sur le client lors du processus d'inférence. Par exemple, il prend en charge la fonction de mots chauds En ajoutant des noms de produits ou des noms propres pendant le processus d'inférence, le modèle vocal peut identifier plus précisément ces mots spécifiques. Cette fonctionnalité est nativement prise en charge par Riva et peut être personnalisée sans recycler le modèle ni redémarrer le serveur Riva.
Dans la boîte violette se trouvent quelques personnalisations qui peuvent être effectuées lors du déploiement. Par exemple, la reconnaissance de streaming de Riva propose deux modes : optimisation de la latence ou optimisation du débit, qui peuvent être sélectionnés en fonction des besoins de l'entreprise pour obtenir de meilleures performances. De plus, lors du processus de déploiement, le dictionnaire de prononciation peut également être personnalisé. Avec un dictionnaire de prononciation personnalisé, vous pouvez garantir la prononciation correcte d’un terme, d’un nom ou d’un jargon industriel spécifique et améliorer la précision de la reconnaissance vocale.
La case verte est la personnalisation qui peut être effectuée pendant le processus de formation, c'est-à-dire la formation et les ajustements effectués côté serveur. Par exemple, dans la phase de régularisation du texte en début de formation, certains traitements de texte spécifiques peuvent être ajoutés. De plus, le modèle acoustique peut être affiné ou recyclé pour résoudre des problèmes tels que les accents et le bruit dans des scénarios commerciaux spécifiques afin de rendre le modèle plus robuste. Vous pouvez également recycler les modèles de langage, affiner les modèles de ponctuation, la régularisation inverse du texte, etc.
Ce qui précède sont les parties personnalisables de Riva.
4. Riva TTS

Le processus Riva TTS est illustré sur le côté droit de l'image ci-dessus. Il contient les modules suivants :
- La première étape est la régularisation du texte.
- La deuxième étape est G2P, qui convertit l'unité de base du texte en unité de base de prononciation ou de langue parlée. Par exemple, convertissez des mots en phonèmes.
- La troisième étape est la synthèse spectrale, convertissant le texte en spectre acoustique.
- La quatrième étape est la synthèse audio, également appelée vocodeur. Dans cette étape, le spectre obtenu à l'étape précédente est converti en audio.
Dans l'image ci-dessus, en prenant la phrase "Hello World" comme exemple, entrez d'abord dans le module de régularisation de texte pour normaliser le texte, comme la normalisation des majuscules et des minuscules. Entrez ensuite dans le module G2P pour convertir le texte en séquence phonétique. Entrez ensuite dans le module de synthèse de spectre et obtenez le spectre grâce à la formation sur les réseaux neuronaux. Entrez enfin dans le vocodeur pour convertir le spectre en son final.
Riva fournit une prise en charge du streaming TTS, en utilisant une combinaison des modèles FastPitch et HiFi-GAN actuellement populaires. Prend actuellement en charge plusieurs langues, dont l'anglais, le chinois mandarin, l'espagnol, l'italien et l'allemand.
5. Pipeline TTS et personnalisation
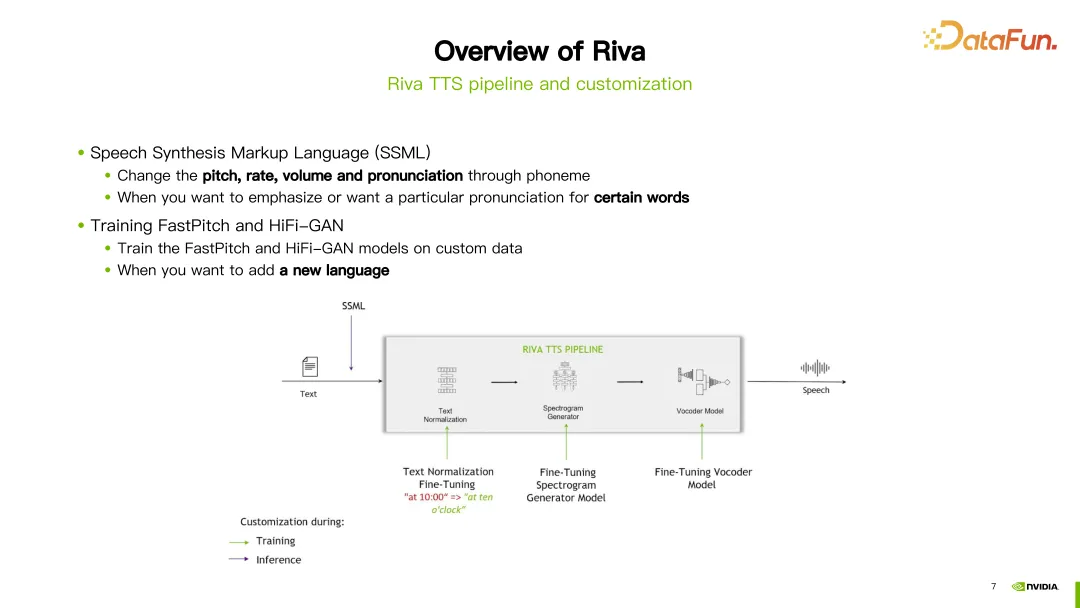
Dans le processus TTS de Riva, deux méthodes sont proposées pour la personnalisation. La première consiste à utiliser SSML (Speech Synthesis Markup Language), qui est un moyen plus simple à personnaliser. Grâce à certaines configurations, la hauteur, la vitesse de parole, le volume, etc. de la prononciation peuvent être ajustés. En règle générale, vous choisissez cette méthode si vous souhaitez modifier la prononciation d'un mot spécifique.
Une autre façon consiste à affiner ou à recycler le modèle FastPitch ou HiFi-GAN. Les deux modèles peuvent être affinés ou recyclés à l’aide de vos propres données spécifiques.
2. La dernière mise à jour du modèle de reconnaissance vocale chinois
1 Présentation

Au cours de la dernière année, Riva a apporté quelques mises à jour et améliorations au modèle chinois. Voici quelques-unes des mises à jour importantes.
Tout d'abord, continuez à optimiser le modèle de reconnaissance vocale chinoise (ASR). Les derniers modèles ASR peuvent être trouvés sur les liens correspondants.
Deuxièmement, la prise en charge du modèle unifié est introduite. Cela signifie que la prédiction des signes de ponctuation par reconnaissance vocale peut être effectuée simultanément en une seule inférence.
Troisièmement, ajout de la prise en charge des modèles mixtes chinois et anglais. Cela signifie que le modèle peut gérer la saisie vocale en chinois et en anglais.
De plus, de nouveaux modules et prises en charge de fonctionnalités ont été introduits. Comprend des modules de détection d'activité vocale (VAD) et de diarisation des haut-parleurs basés sur un réseau neuronal. La fonction de régularisation inverse du texte chinois est également introduite. Les détails de ces modèles peuvent être trouvés dans les liens correspondants.
2. Word Boosting
De plus, nous proposons également des tutoriels détaillés pour le chinois. La première partie est un tutoriel sur les mots chauds (Word Boosting).

Les mots chauds ajustent le poids d'un mot spécifique lors de la reconnaissance pour rendre la reconnaissance des mots plus précise. Dans le didacticiel, un exemple de modèle chinois utilisant des mots chauds tels que "Wangyue", qui est le nom d'un poème ancien, est présenté, et nous attribuons à ce mot un poids de 20. Ensuite, utilisez la méthode add_word_boosting_to_config fournie par Riva pour configurer les mots que nous souhaitons ajouter et leurs scores dans le client. Ensuite, envoyez la requête configurée au serveur ASR pour obtenir les résultats de reconnaissance après avoir ajouté des mots chauds.
Lors de la configuration des mots chauds, vous devez définir deux paramètres : boosted_lm_words et boosted_lm_score. boosted_lm_words est une liste de mots pour lesquels nous souhaitons améliorer la précision de la reconnaissance. Boosted_lm_score est le score attribué à ces mots, généralement compris entre 20 et 100.

En plus de la configuration de base précédente, la fonction Hot Word de Riva prend également en charge certaines utilisations avancées. Par exemple, le poids de plusieurs mots peut être augmenté en même temps. Par exemple, dans l'exemple, nous définissons respectivement des pondérations de 20 et 30 pour les mots « cinq G » et « quatre G ».
De plus, nous pouvons également utiliser le renforcement de mots pour réduire la précision de certains mots, c'est-à-dire leur attribuer des poids négatifs, réduisant ainsi leur probabilité d'apparition. Par exemple, dans l'exemple, on nous donne un caractère chinois « elle » et son score est fixé à -100. De cette façon, le modèle aura tendance à ne pas reconnaître le caractère chinois. Théoriquement, nous pouvons définir n'importe quel nombre de mots chauds sans affecter la latence. Il convient également de noter que le processus de boosting est implémenté côté client et n’a aucun impact côté serveur.
3. Finetuning Conformer AM
Le deuxième tutoriel explique comment affiner le modèle acoustique du Conformer.

Le réglage fin de l'ASR utilise les outils NeMo. Après avoir configuré le compte NGC, vous pouvez utiliser la commande « NGC download » pour télécharger directement le modèle chinois pré-entraîné fourni par Riva. Dans cet exemple, la cinquième version du modèle ASR chinois a été téléchargée. Une fois le téléchargement terminé, vous devez charger le modèle pré-entraîné.
Tout d'abord, vous devez importer certains packages. Le paramètre chemin du modèle est défini sur le chemin du modèle qui vient d'être téléchargé. Ensuite, utilisez la fonction ASRModel.restore_from fournie par NeMo pour obtenir le fichier de configuration du modèle et utilisez le paramètre target pour obtenir la catégorie du modèle ASR d'origine. Ensuite, utilisez la fonction import_class_by_path pour obtenir la classe de modèle réelle. Enfin, utilisez la méthode restaurer_from du modèle sous cette catégorie pour charger les paramètres du modèle ASR sous le chemin spécifié.

Après avoir chargé le modèle, vous pouvez utiliser le script de formation fourni par NeMo pour affiner le réglage. Dans cet exemple, nous prenons comme exemple la formation du modèle CTC et le script utilisé est Speech_to_text_ctc.py. Certains paramètres qui doivent être configurés incluent train_ds.manifest_filepath, qui est le chemin du fichier JSON des données d'entraînement, ainsi que l'utilisation ou non du GPU, de l'optimiseur et du nombre maximum de tours d'itération.
Après avoir entraîné le modèle, il peut être évalué. Lors de l'évaluation, vous devez faire attention à définir le paramètre use_cer sur true, car pour le chinois, nous utilisons le taux d'erreur de caractère (Character Error Rate) comme indicateur. Après avoir terminé la formation et évalué le modèle, vous pouvez utiliser la commande nemo2riva pour convertir le modèle NeMo en modèle Riva. Utilisez ensuite l'outil Quickstart de Riva pour déployer le modèle.
3. Service Riva TTS (Text-to-Speech)
Ensuite, nous présenterons le service Riva TTS.
1. Démo
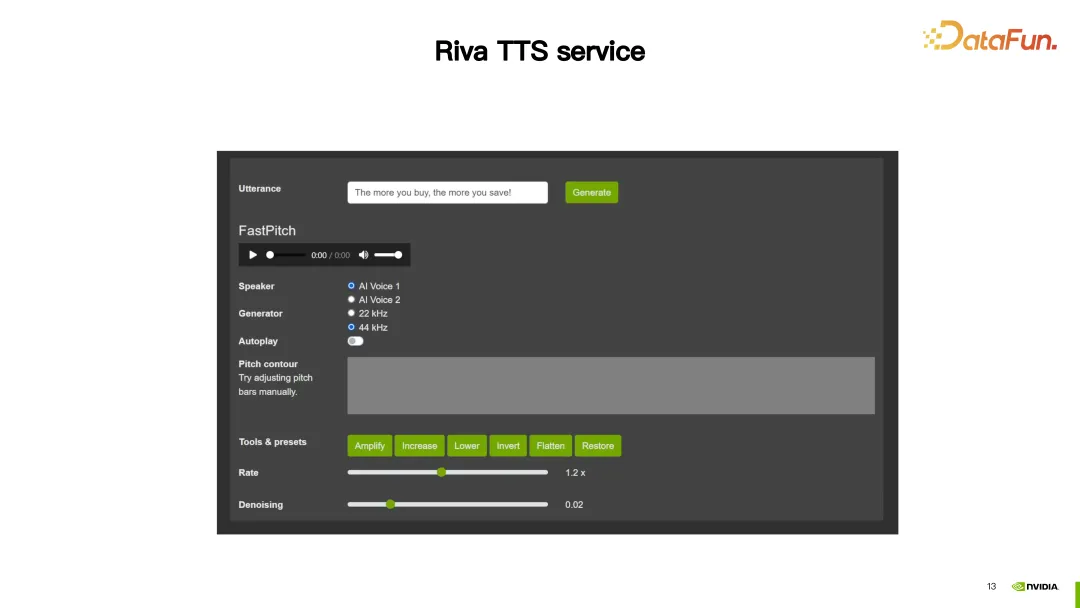
Dans cette démo, Riva TTS propose des fonctions de personnalisation pour rendre la parole synthétisée plus naturelle.
Ensuite, nous présenterons les deux méthodes de personnalisation proposées par Riva TTS.
2. SSML

Le premier est le SSML (Speech Synthesis Markup Language) susmentionné, qui est configuré via un script. Grâce à SSML, le rythme dans TTS peut être ajusté, y compris la hauteur et la fréquence, et le volume peut également être ajusté.
Comme le montre l'image ci-dessus, pour la première phrase "Aujourd'hui est une journée ensoleillée", changez la hauteur de la rime à 2,5. Pour la deuxième phrase, deux configurations ont été faites : l'une consistait à régler son débit à un niveau élevé et l'autre à augmenter le volume de 1 DB. De cette façon, vous pouvez obtenir un résultat personnalisé.
3. Réglage fin du TTS à l'aide de NeMo
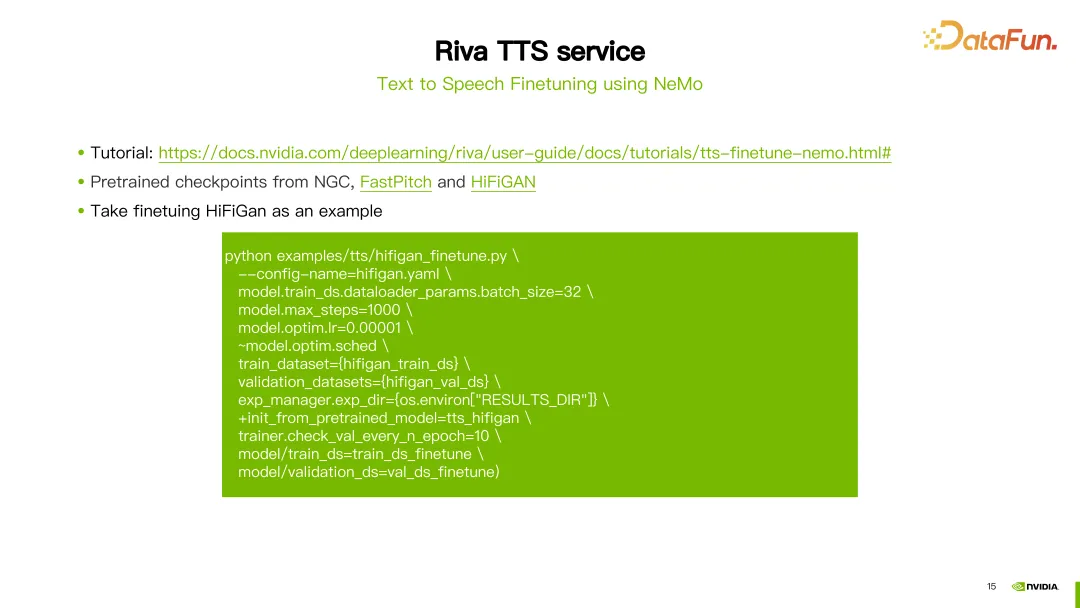
En plus de SSML, vous pouvez également utiliser les outils NeMo pour affiner ou recycler les modèles FastPitch ou HiFi-GAN de Riva TTS.
Riva propose des tutoriels et quelques modèles pré-entraînés sur NGC (voir lien dans l'image ci-dessus).
L'image montre un exemple de réglage fin du modèle HiFi-GAN. Utilisez la commande hifigan_finetune.py et configurez des paramètres tels que le nom de la configuration du modèle, la taille du lot, le nombre maximum d'étapes d'itération et le taux d'apprentissage. Définissez le chemin de l'ensemble de données requis pour affiner HiFi-GAN en définissant le paramètre train_dataset. Si vous avez téléchargé un modèle pré-entraîné depuis NGC, vous pouvez également utiliser le paramètre init_from_pretrained_model pour charger le modèle pré-entraîné. De cette façon, le modèle HiFi-GAN peut être recyclé.
4. Outil Riva Quickstart
Le modèle personnalisé peut être déployé à l'aide de l'outil Quickstart.
1. Préparation

Avant de commencer, vous devez enregistrer un compte NGC, vous assurer que le GPU prend en charge Riva et que l'environnement Docker a été installé.
Une fois les préparatifs terminés, téléchargez Riva Quickstart via le lien fourni. Si la CLI NGC a été configurée, vous pouvez également utiliser la CLI NGC pour télécharger directement Riva Quickstart.
2. Démarrage et arrêt du serveur
Après avoir téléchargé Riva Quick Start, vous pouvez utiliser les scripts fournis pour initialiser, démarrer et arrêter le serveur.

En prenant la dernière version de Riva (2.13.1) comme exemple, une fois le téléchargement terminé, il vous suffit d'exécuter riva_init.sh, riva_start.sh ou riva_stop.sh pour terminer l'initialisation, le démarrage et arrêt du serveur.
Si vous souhaitez utiliser un modèle chinois, définissez simplement le code de langue sur zh-CN et l'outil téléchargera automatiquement le modèle pré-entraîné correspondant. Vous pouvez démarrer le service pour utiliser les fonctions chinoises ASR (reconnaissance automatique de la parole) et TTS (texte en parole).
3. Riva Client

Une fois le serveur démarré avec succès, vous pouvez utiliser le script riva_start_client.sh fourni par Riva pour appeler le service. Si vous souhaitez une reconnaissance vocale hors ligne, exécutez simplement la commande riva_asr_client et spécifiez le chemin d'accès au fichier audio que vous souhaitez reconnaître. Si vous souhaitez effectuer une reconnaissance vocale en streaming, vous pouvez utiliser la commande riva_streaming_asr_client. Si vous souhaitez effectuer une synthèse vocale, vous pouvez utiliser la commande riva_tts_client pour envoyer l'audio à traiter ou synthétiser au serveur que vous venez de démarrer.
5. Ressources de référence
Voici quelques ressources de documentation liées à Riva :

Documentation officielle de Riva : Ce document fournit des informations détaillées sur Riva, y compris des guides d'installation, de configuration et d'utilisation. Vous pouvez trouver la documentation officielle de Riva ici pour en savoir plus et découvrir tous les aspects de Riva.
Guide de l'utilisateur Riva Quick Start : ce guide fournit aux utilisateurs des instructions détaillées pour Riva Quick Start, y compris les étapes d'installation et de configuration, ainsi que des réponses aux questions fréquemment posées. Si vous rencontrez des problèmes lors de l'utilisation de Riva Quick Start, vous pouvez trouver les réponses dans ce guide de l'utilisateur.
Notes de version Riva : ce document fournit des informations mises à jour sur les derniers modèles de Riva. Vous pouvez découvrir les nouveautés et les améliorations de chaque version ici.
Les ressources ci-dessus aideront les utilisateurs à mieux comprendre et utiliser Riva.
Ce qui précède est le contenu partagé cette fois, merci à tous.
6. Séance de questions et réponses
Q1 : Quelle est la relation entre Riva et Triton ? Y a-t-il des chevauchements fonctionnels ?
A1 : Oui, Riva utilise le cadre d'inférence de Nvidia Triton, qui est basé sur certains développements de Nvidia Triton.
Q2 : Riva a-t-il réellement été implémenté dans le domaine RAG ? Ou un projet open source ?
A2 : Riva devrait actuellement se concentrer principalement sur le domaine de l'IA vocale.
Q3 : Y a-t-il une relation entre Riva et Nemo ?
A3 : Riva se concentre davantage sur les solutions de déploiement. Les modèles formés avec Nemo peuvent être déployés avec Riva. Nous pouvons également utiliser Nemo pour effectuer des travaux de réglage et de formation, puis affiner un bon modèle. à Riva.
Q4 : Les modèles formés par d'autres frameworks peuvent-ils être appliqués ?
A4 : La formation avec d'autres frameworks n'est temporairement pas prise en charge, ou nécessite un travail de développement supplémentaire.
Q5 : Riva peut-il déployer des modèles à partir du framework de formation PyTorch ou TensorFlow ?
A5 : Riva prend désormais principalement en charge les modèles entraînés par Nemo. Nemo est en fait développé sur la base de PyTorch.
Q6 : Si je personnalise un nouveau modèle dans Nemo, dois-je écrire du code de déploiement dans Riva ?
A6 : Pour les modèles auto-développés, si vous souhaitez les prendre en charge dans Riva, vous devez faire quelques développements supplémentaires.
Q7 : Riva peut-il être utilisé avec un GPU à petite mémoire ?
A7 : Vous pouvez vous référer aux documents liés à la plateforme d'adaptation fournis par Riva, qui incluent l'adaptation de différents types de GPU.
Q8 : Comment tester rapidement Riva ?
A8 : Vous pouvez essayer Riva en téléchargeant la boîte à outils Riva Quickstart directement sur NGC.
Q9 : Si Riva souhaite prendre en charge les dialectes chinois, Riva aura-t-elle besoin d'une formation personnalisée ?
A9 : C'est vrai. Vous pouvez utiliser des données dans certains de vos propres dialectes. Affinez-le simplement en fonction du modèle pré-entraîné fourni par Riva, puis déployez-le dans Riva.
Q10 : Y a-t-il des chevauchements ou des différences dans le positionnement de Riva et Tensor LM ?
A10 : L'accélération de Riva utilise en fait Tensor RT Riva est un produit basé sur Tensor RT et Triton.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Utilisation de mots-clés publics, privés, protégés, abstraits et autres en PHP
- Comparaison simple des différences et introduction de l'utilisation entre Public&Private&Protect en php
- Comment résoudre le problème selon lequel le pilote Nvidia est installé avec succès mais le pilote d'affichage n'est pas installé
- Différence entre const, statique, public, privé et protégé en PHP
- Que diriez-vous de la carte graphique nvidia geforce 940mx