La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
La génération de vidéos de danse humaine est une tâche de synthèse vidéo contrôlable convaincante et stimulante, visant à générer une vidéo basée sur des images de référence d'entrée et des séquences de poses cibles générées. vidéos continues réalistes de haute qualité. Avec le développement rapide de la technologie de génération vidéo, en particulier l'évolution itérative des modèles génératifs, la tâche de génération de vidéo de danse a réalisé des progrès sans précédent et a démontré un large éventail de potentiels d'application. Les méthodes existantes peuvent être grossièrement divisées en deux groupes. Le premier groupe est généralement basé sur les Generative Adversarial Networks (GAN), qui exploitent une représentation intermédiaire guidée par la pose pour déformer les apparences de référence et générer des images vidéo plausibles à partir de cibles précédemment déformées. Cependant, les méthodes basées sur des réseaux antagonistes génératifs souffrent souvent d’un entraînement instable et de faibles capacités de généralisation, ce qui entraîne des artefacts évidents et une gigue inter-trame. Le deuxième groupe utilise le modèle de diffusion pour synthétiser des vidéos réalistes. Ces méthodes présentent les avantages d'une formation stable et de fortes capacités de transfert, et fonctionnent mieux que les méthodes basées sur le GAN, notamment Disco, MagicAnimate, Animate Anybody, Champ, etc. Bien que les méthodes basées sur les modèles de diffusion aient fait des progrès significatifs, les méthodes existantes présentent encore deux limites : Premièrement, un réseau de référence supplémentaire (ReferenceNet) est nécessaire pour encoder les caractéristiques de l'image de référence et les combiner avec 3D-UNet. L'alignement apparent des branches de base augmente la difficulté de formation et les paramètres de modélisation ; deuxièmement, ils utilisent généralement un transformateur temporel pour modéliser la dépendance temporelle entre les images vidéo, mais la complexité du transformateur devient quadratique avec la durée du temps généré. durée de synchronisation de la vidéo générée. Les méthodes typiques ne peuvent générer que 24 images vidéo, ce qui limite les possibilités pratiques de déploiement. Bien que la stratégie de fenêtre glissante de chevauchement temporel puisse générer des vidéos plus longues, les auteurs de l’équipe ont constaté que cette méthode conduit facilement à des problèmes de transitions irrégulières et d’incohérence d’apparence aux jonctions des segments superposés. Pour résoudre ces problèmes, une équipe de recherche de l'Université des sciences et technologies de Huazhong, d'Alibaba et de l'Université des sciences et technologies de Chine a proposé le UniAnimate framework pour réaliser une génération de vidéo humaine efficace et à long terme. 
- Adresse papier : https://arxiv.org/abs/2406.01188
- Page d'accueil du projet : https://unianimate.github.io/
Introduction à la méthode Le framework UniAnimate mappe d'abord l'image de référence, le guidage de pose et la vidéo de bruit dans l'espace des fonctionnalités, puis utilise le Modèle de diffusion vidéo unifié (Modèle de diffusion vidéo unifié) pour traiter simultanément l'alignement apparent de l'image de référence et de la branche principale de la vidéo et des tâches de débruitage vidéo pour un alignement efficace des fonctionnalités et une génération vidéo cohérente. Deuxièmement, l'équipe de recherche a également proposé une entrée de bruit unifiée qui prend en charge l'entrée de bruit aléatoire et l'entrée de bruit conditionnelle basée sur la première image. L'entrée de bruit aléatoire peut générer une vidéo avec l'image de référence et la séquence de poses, et en fonction de celle-ci. L'entrée de bruit conditionnelle de la première image (First Frame Conditioning) utilise la première image de la vidéo comme entrée conditionnelle pour continuer à générer les vidéos suivantes. De cette manière, une inférence peut être générée en traitant la dernière image du segment vidéo précédent comme la première image du segment suivant, et ainsi de suite pour obtenir une génération vidéo longue dans un cadre. Enfin, afin de traiter plus efficacement de longues séquences, l'équipe de recherche a exploré une architecture de modélisation temporelle basée sur le modèle d'espace d'états (Mamba) comme alternative au transformateur original de séries temporelles à forte intensité de calcul. Des expériences ont montré que l'architecture basée sur Mamba séquentiel peut produire des effets similaires à ceux du Transformer séquentiel, mais nécessite moins de surcharge de mémoire graphique.
Avec le framework UniAnimate, les utilisateurs peuvent générer des vidéos de danse humaine en séries chronologiques de haute qualité. Il convient de mentionner qu'en utilisant plusieurs fois la stratégie de conditionnement de la première image, une vidéo haute définition d'une minute peut être générée. Par rapport aux méthodes traditionnelles, UniAnimate présente les avantages suivants :
- Pas besoin de réseaux de référence supplémentaires : Le cadre UniAnimate élimine la dépendance à l'égard de réseaux de référence supplémentaires grâce à un modèle de diffusion vidéo unifié, réduisant ainsi la difficulté de formation et le nombre de modèles. de paramètres.
- Introduit la carte de pose de l'image de référence comme condition de référence supplémentaire, qui favorise l'apprentissage du réseau par la correspondance entre la pose de référence et la pose cible et permet d'obtenir un bon alignement apparent.
- Générer des vidéos à longue séquence dans un cadre unifié : En ajoutant une entrée de bruit unifiée, UniAnimate est capable de générer des vidéos à long terme dans une image, n'étant plus soumises aux contraintes de temps des méthodes traditionnelles.
- Haute cohérence : Le framework UniAnimate assure un effet de transition fluide de la vidéo générée en utilisant de manière itérative la première image comme condition pour générer les images suivantes, rendant la vidéo plus cohérente et plus cohérente en apparence. Cette stratégie permet également aux utilisateurs de générer plusieurs clips vidéo et de sélectionner la dernière image du clip avec de bons résultats comme première image du prochain clip généré, ce qui permet aux utilisateurs d'interagir plus facilement avec le modèle et d'ajuster les résultats de génération selon leurs besoins. Cependant, lors de la génération de longues vidéos à l'aide de la stratégie de fenêtre glissante du chevauchement des séries temporelles précédentes, la sélection de segments ne peut pas être effectuée car chaque vidéo est couplée les unes aux autres à chaque étape du processus de diffusion.
Les fonctionnalités ci-dessus rendent le framework UniAnimate excellent pour synthétiser des vidéos de danse humaine de haute qualité et à long terme, offrant de nouvelles possibilités pour un plus large éventail d'applications. Exemple de résultats générés
2. Générez des vidéos de danse basées sur de vraies images.
3. Génération de vidéos de danse basée sur des images de style argile.
4. Le musc danse.
5. Yann LeCun danse.
6. Générez des vidéos de danse basées sur d'autres images inter-domaines.
7. Génération de vidéo de danse d'une minute. Pour des vidéos MP4 originales et d'autres exemples de vidéos HD, veuillez vous référer à la page d'accueil du projet du journal https://unianimate.github.io/. Analyse comparative expérimentale1. Expériences comparatives quantitatives avec les méthodes existantes sur l'ensemble de données TikTok.
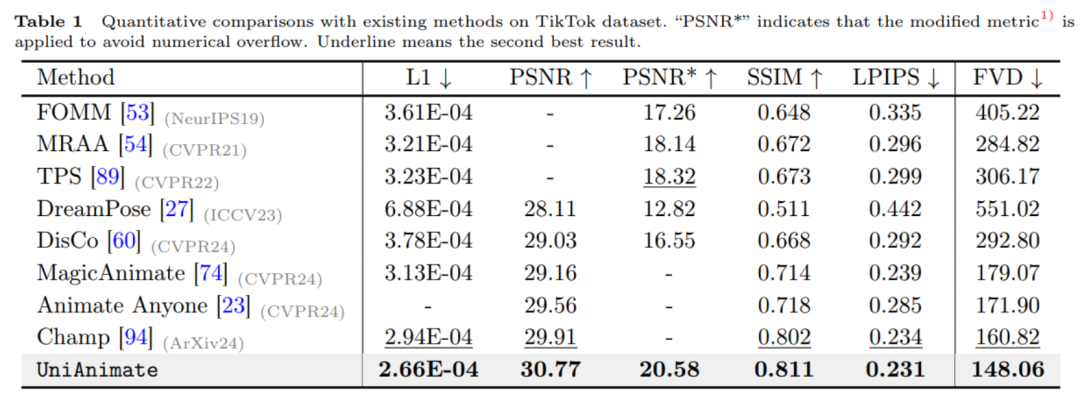
Comme le montre le tableau ci-dessus, la méthode UniAnimate obtient les meilleurs résultats sur les indicateurs d'image tels que L1, PSNR, SSIM, LPIPS et les indicateurs vidéo FVD, indiquant qu'UniAnimate peut générer des résultats haute fidélité. 2. Expériences comparatives qualitatives avec les méthodes existantes.
Il ressort également des expériences comparatives qualitatives ci-dessus que, par rapport à MagicAnimate et Animate Any, la méthode UniAnimate peut générer de meilleurs résultats continus sans artefacts évidents, indiquant l'efficacité d'UniAnimate.
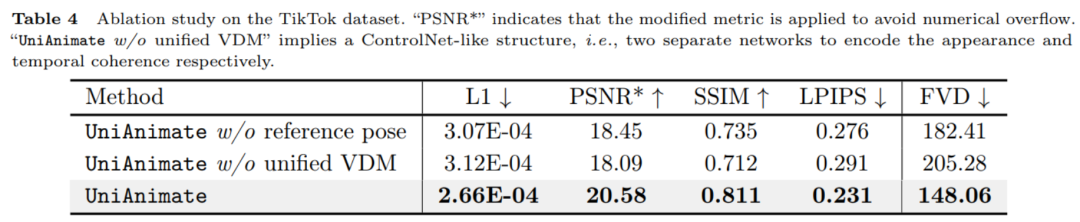
Comme le montrent les résultats numériques du tableau ci-dessus, la pose de référence et le modèle de diffusion vidéo unifié utilisés dans UniAnimate jouent un rôle clé dans l'amélioration des performances. 4. Comparaison des stratégies de génération de vidéos longues.
Comme le montre la figure ci-dessus, la stratégie de fenêtre coulissante à chevauchement temporel couramment utilisée pour générer de longues vidéos peut facilement conduire à des transitions discontinues. L'équipe de recherche estime que cela est dû au fait que différentes fenêtres ont des difficultés de débruitage incohérentes. la partie de chevauchement de synchronisation, rendant les résultats de génération différents, une moyenne directe entraînera une déformation ou une distorsion évidente, et cette incohérence provoquera une propagation d'erreur. La méthode de génération de continuation vidéo de première image utilisée dans cet article peut générer des transitions fluides. Pour plus de résultats de comparaison expérimentale et d'analyse, veuillez vous référer à l'article original. Dans l'ensemble, les exemples de résultats d'UniAnimate et les résultats de comparaison quantitative sont très bons. Nous attendons avec impatience l'application d'UniAnimate dans divers domaines, tels que la production cinématographique et télévisuelle, la réalité virtuelle et les industries du jeu, etc., pour apporter davantage aux utilisateurs. images humaines réalistes et passionnantes. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn






 2. Générez des vidéos de danse basées sur de vraies images.
2. Générez des vidéos de danse basées sur de vraies images. 
 3. Génération de vidéos de danse basée sur des images de style argile.
3. Génération de vidéos de danse basée sur des images de style argile. 
 4. Le musc danse.
4. Le musc danse.  5. Yann LeCun danse.
5. Yann LeCun danse.  6. Générez des vidéos de danse basées sur d'autres images inter-domaines.
6. Générez des vidéos de danse basées sur d'autres images inter-domaines.