
Maison >Périphériques technologiques >IA >Vers la « boucle fermée » | PlanAgent : nouveau SOTA pour la planification en boucle fermée de la conduite autonome basée sur MLLM !
Vers la « boucle fermée » | PlanAgent : nouveau SOTA pour la planification en boucle fermée de la conduite autonome basée sur MLLM !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-08 21:30:27610parcourir
L'équipe d'apprentissage par renforcement profond de l'Institut d'automatisation de l'Académie chinoise des sciences, en collaboration avec Li Auto et d'autres, a proposé un nouveau cadre de planification en boucle fermée pour la conduite autonome basé sur un modèle multimodal à grand langageMLLM - PlanAgent. Cette méthode prend une vue d'ensemble de la scène et des invites de texte basées sur des graphiques en entrée, et utilise la compréhension multimodale et les capacités de raisonnement de bon sens du grand modèle de langage multimodal pour effectuer un raisonnement hiérarchique depuis la compréhension de la scène jusqu'à la génération. d'instructions de mouvement horizontal et vertical, et générer en outre les instructions requises par le planificateur. La méthode est testée sur le benchmark nuPlan à grande échelle et exigeant, et les expériences montrent que PlanAgent atteint des performances de pointe (SOTA) dans les scénarios réguliers et à longue traîne. Par rapport aux méthodes LLM (Large Language Model) conventionnelles, la quantité de jetons de description de scène requise par PlanAgent n'est que d'environ 1/3.
Informations papier
- Titre de l'article : PlanAgent : A Multi-modal Large Language Agent for Closed loop Vehicle Motion Planning
- Unités de publication papier : Institute of Automation, Chinese Academy of Sciences, Li Auto, Tsinghua Université, Université aérospatiale de Pékin
- Adresse papier :https://arxiv.org/abs/2406.01587


1 Introduction
En tant que l'un des modules de base de la conduite autonome, l'objectif de la planification des mouvements consiste à générer une trajectoire optimale pour la sécurité et le confort. Les algorithmes basés sur des règles, tels que l'algorithme PDM [1], fonctionnent bien dans la gestion des scénarios courants, mais sont souvent difficiles à gérer avec les scénarios à longue traîne qui nécessitent des opérations de conduite plus complexes [2]. Les algorithmes basés sur l'apprentissage [2,3] sont souvent surajustés dans les situations à longue traîne, ce qui entraîne des performances dans nuPlan qui ne sont pas aussi bonnes que la méthode PDM basée sur des règles.
Récemment, le développement de grands modèles de langage a ouvert de nouvelles possibilités pour la planification de la conduite autonome. Certaines recherches récentes tentent d'utiliser les puissantes capacités de raisonnement des grands modèles de langage pour améliorer les capacités de planification et de contrôle des algorithmes de conduite autonome. Cependant, ils ont rencontré quelques problèmes : (1) L'environnement expérimental n'a pas été basé sur un scénario réel d'environnement fermé (2) Un certain nombre de numéros de coordonnées ont été utilisés pour représenter les détails de la carte ou l'état du mouvement, ce qui a considérablement augmenté le nombre de jetons requis ; (3) ) Il est difficile d'assurer la sécurité lorsque les points de trajectoire sont directement générés par un grand modèle de langage. Pour relever les défis ci-dessus, cet article propose la méthode PlanAgent.
2 Méthode
Le cadre PlanAgent d'un agent de planification en boucle fermée basé sur MLLM est présenté dans la figure 1. Cet article conçoit trois modules pour résoudre des problèmes complexes de conduite autonome :
- Module d'extraction d'informations de scène (Module de transformation de l'environnement) : Afin d'obtenir une représentation efficace des informations sur la scène, un module d'extraction des informations sur l'environnement est conçu pour extraire une entrée multimodale avec des informations sur les voies.
- Module de raisonnement : Afin de parvenir à une compréhension de la scène et à un raisonnement de bon sens, un module de raisonnement est conçu, qui utilise le grand modèle de langage multimodal MLLM pour générer un code de planificateur raisonnable et sûr.
- Module de réflexion : Afin de garantir une planification sûre, un mécanisme de réflexion est conçu, qui peut vérifier le planificateur par simulation et filtrer les propositions MLLM déraisonnables.
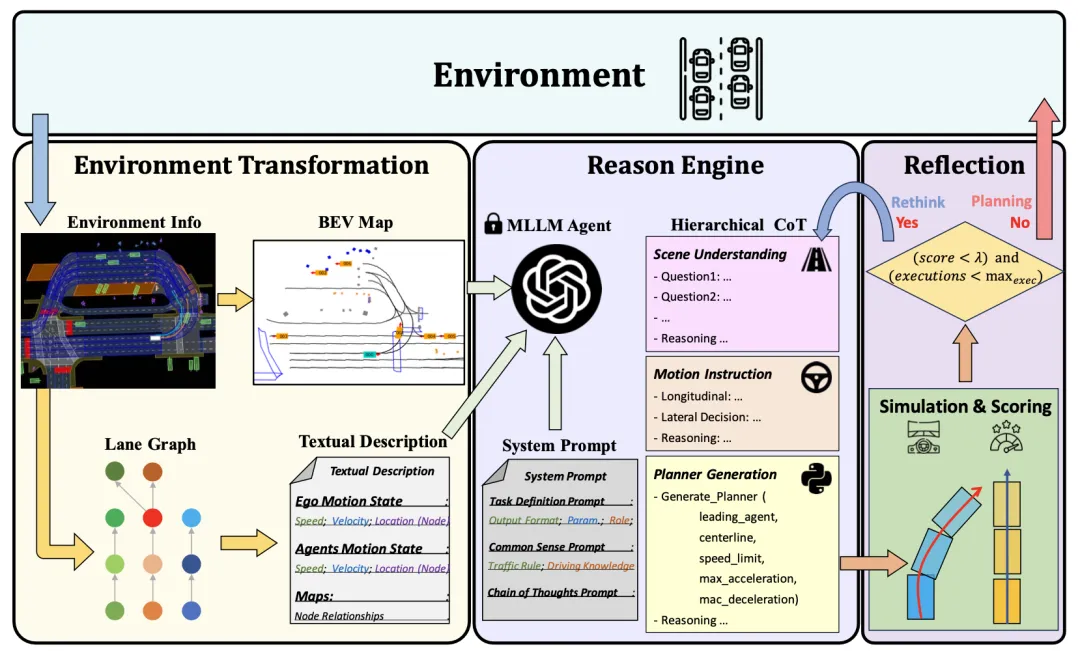
Figure 1 Le cadre global de PlanAgent, y compris le module d'extraction/raisonnement/réflexion des informations de scène
2.1 Module d'extraction des informations environnementales
Les mots d'invite (invite) dans le grand modèle de langage génèrent une sortie pour cela, la qualité a un impact important. Afin d'améliorer la qualité de génération de MLLM, le module d'extraction d'informations de scène est capable d'extraire des informations de contexte de scène et de les convertir en une image et une représentation textuelle de vue d'oiseau (BEV), les rendant cohérentes avec l'entrée de MLLM. Premièrement, cet article convertit les informations de la scène en images Bird Escape (BEV) pour améliorer la capacité de MLLM à comprendre la scène mondiale. Dans le même temps, les informations routières doivent être représentées graphiquement, comme le montre la figure 2. Sur cette base, les informations clés sur les mouvements du véhicule sont extraites, afin que MLLM puisse se concentrer sur la zone la plus pertinente pour sa propre position.
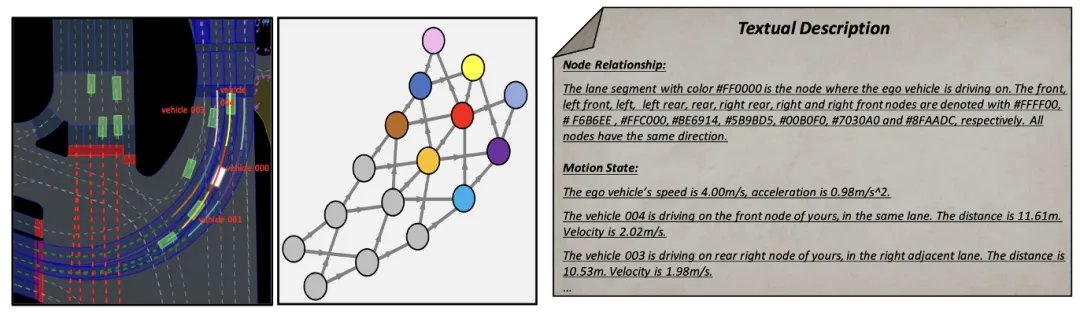
Figure 2 Description de l'invite textuelle basée sur la représentation graphique
2.2 Module de raisonnement
Comment introduire la capacité de raisonnement des grands modèles de langage dans le processus de planification de la conduite autonome et réaliser un système de planification doté de capacités de raisonnement de bon sens est une question clé. La méthode conçue dans cet article peut prendre en entrée les messages utilisateur et les messages système prédéfinis contenant des informations sur la scène actuelle, et générer le code de planification du modèle de pilote intelligent (IDM) à travers plusieurs cycles de raisonnement dans la chaîne de pensée hiérarchique. En conséquence, PlanAgent peut intégrer les puissantes capacités de raisonnement de MLLM dans les tâches de planification de conduite autonome grâce à l'apprentissage contextuel.
Parmi eux, le message utilisateur comprend le codage BEV et les informations sur les mouvements du véhicule environnant extraites sur la base d'une représentation graphique. Les messages du système incluent la définition des tâches, les connaissances de bon sens et les étapes de la chaîne de réflexion, comme le montre la figure 3.

Figure 3 Modèle d'invite du système
Après avoir obtenu les informations d'invite, MLLM raisonnera sur la scène actuelle à partir de trois niveaux : compréhension de la scène, instructions de mouvement et génération de code, et générera enfin le code du planificateur. . Dans PlanAgent, les codes de paramètres de suivi de voiture, de ligne médiane, de limite de vitesse, d'accélération maximale et de décélération maximale seront générés, puis l'accélération instantanée dans une certaine scène sera générée par IDM, et enfin une trajectoire sera générée.
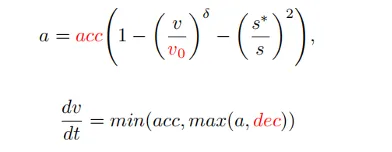
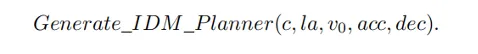
2.3 Module de réflexion
Grâce aux deux modules ci-dessus, les capacités de compréhension et de raisonnement de MLLM sur la scène sont renforcées. Cependant, l’illusion du MLLM constitue toujours un défi pour la sécurité de la conduite autonome. Inspiré par le processus décisionnel des êtres humains consistant à « réfléchir à deux fois avant de se lancer », cet article ajoute un mécanisme de réflexion à la conception de l’algorithme. Simulez le planificateur généré par MLLM et évaluez le score de conduite du planificateur grâce à des indicateurs tels que la probabilité de collision, la distance de conduite et le confort. Lorsque le score est inférieur à un certain seuil τ, cela indique que le planificateur généré par MLLM est inadéquat, et il sera demandé à MLLM de régénérer le planificateur.
3 Expériences et résultats
Cet article mène des expériences de planification en boucle fermée sur nuPlan [4], une plate-forme de planification en boucle fermée pour des scènes réelles à grande échelle, pour évaluer les performances de PlanAgent. comme suit. 3.1 Expérience principale trois catégories d'algorithmes de pointe et des tests sur les deux benchmarks de nuPlan, val14 et test-hard. PlanAgent affiche des résultats compétitifs et généralisables par rapport à d'autres méthodes.
Résultats compétitifs : sur le benchmark de scénario commun val14, PlanAgent surpasse les autres méthodes basées sur des règles, basées sur l'apprentissage et basées sur de grands modèles de langage, obtenant le meilleur score NR-CLS et R-CLS.
Résultats généralisables : ni les méthodes basées sur des règles représentées par PDM-Closed[1] ni les méthodes basées sur l'apprentissage représentées par planTF[2] ne peuvent fonctionner correctement sur val14 et tester dur en même temps. Par rapport à ces deux types de méthodes, PlanAgent peut surmonter les scénarios à longue traîne tout en garantissant les performances dans les scénarios courants.
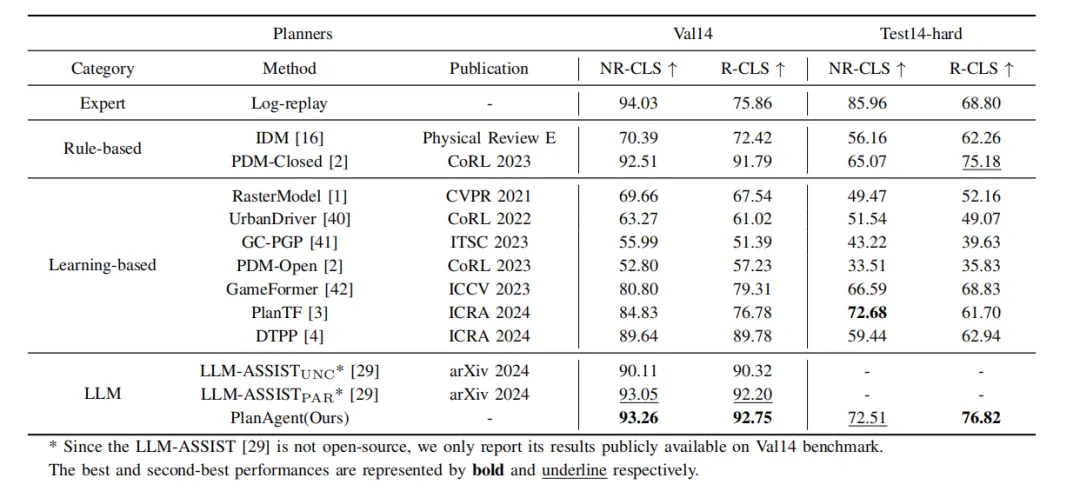 Tableau 2 Comparaison des jetons utilisés par différentes méthodes pour décrire des scénarios
Tableau 2 Comparaison des jetons utilisés par différentes méthodes pour décrire des scénarios
- Dans le même temps, PlanAgent utilise moins de jetons que les autres grandes méthodes basées sur un modèle, comme le montre le tableau 2, et ne nécessite probablement que GPT 1/3 de -Driver[5] ou LLM-ASSIST[6]. Cela montre que PlanAgent peut décrire la scène plus efficacement avec moins de jetons. Ceci est particulièrement important pour l’utilisation de grands modèles de langage fermés.
- 3.2 Expérience d'ablation
Tableau 3 Expérience d'ablation de différentes parties dans le module d'extraction de scène

Tableau 4 Expériences d'ablation de différentes parties de la chaîne de pensée hiérarchique
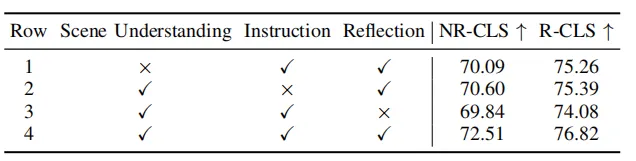
Comme le montrent les tableaux 3 et 4, cet article a mené des expériences d'ablation sur différentes parties du module d'extraction d'informations de scène et du module de raisonnement, et l'expérience a prouvé l'efficacité et la nécessité des modules individuels. La compréhension de la scène par MLLM peut être améliorée grâce à la représentation graphique et par image BEV, et la capacité de raisonnement de MLLM pour la scène peut être améliorée grâce à des chaînes de pensée hiérarchiques.
Tableau 5 Expériences de PlanAgent sur différents modèles de langage
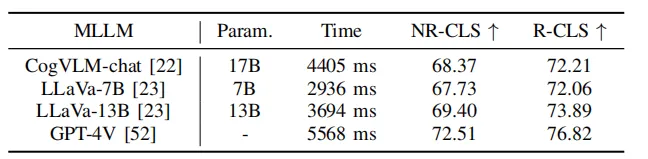
En même temps, comme le montre le tableau 5, cet article utilise certains grands modèles de langage open source pour les tests. Les résultats expérimentaux montrent que sur le benchmark Test-hard NR-CLS, PlanAgent utilisant différents grands modèles de langage peut atteindre des scores de conduite 4,1 %, 5,1 % et 6,7 % plus élevés que PDM-Closed respectivement. Cela démontre la compatibilité de PlanAgent avec divers grands modèles de langage multimodaux.
3.3 Analyse visuelle
scène de circulation au rond-point
PDM sélectionne la voie extérieure comme ligne médiane, et le véhicule roule sur la voie extérieure et reste bloqué lorsque le véhicule fusionne. PlanAgent détermine qu'un véhicule fusionne, émet une commande raisonnable de changement de voie à gauche et génère une action latérale pour sélectionner la voie intérieure du rond-point comme ligne médiane, et le véhicule roule sur la voie intérieure.

Scène de stationnement sur la ligne d'arrêt à l'intersection
PDM a sélectionné la catégorie des feux de circulation comme catégorie de suivi des voitures. PlanAgent génère des instructions raisonnables et sélectionne la ligne d'arrêt comme catégorie de suivi de voiture.
4 Conclusion
Cet article propose un nouveau cadre de planification en boucle fermée basé sur MLLM pour la conduite autonome, appelé PlanAgent. Cette méthode introduit un module d'extraction d'informations de scène pour extraire des images BEV et extraire les informations de mouvement des véhicules environnants sur la base de la représentation graphique de la route. Dans le même temps, un module de raisonnement avec une structure hiérarchique est proposé pour guider MLLM dans la compréhension des informations de scène, générer des instructions de mouvement et enfin générer du code de planificateur. De plus, PlanAgent imite également la prise de décision humaine à des fins de réflexion et replanifie lorsque le score de trajectoire est inférieur au seuil pour améliorer la sécurité de la prise de décision. L'agent de planification en boucle fermée de conduite autonome PlanAgent, basé sur le grand modèle multimodal, a atteint les performances SOTA en matière de planification en boucle fermée sur le benchmark nuPlan.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un système de contrôle en boucle fermée
- Tesla utilise l'intelligence artificielle pour améliorer la conduite autonome
- Un aperçu des trois architectures de puces traditionnelles pour la conduite autonome dans un seul article
- Comment développer la conduite autonome et l'Internet des véhicules en PHP ?
- Waymo et Uber remodèlent leur partenariat pour explorer conjointement l'application de la technologie de conduite autonome dans le domaine du covoiturage en ligne