Maison > Article > Périphériques technologiques > Extrayez des millions de fonctionnalités de Claude 3 et comprenez pour la première fois la « pensée » des grands modèles en détail
Extrayez des millions de fonctionnalités de Claude 3 et comprenez pour la première fois la « pensée » des grands modèles en détail

- WBOYoriginal
- 2024-06-07 13:37:45579parcourir
Tout à l'heure, Anthropic a annoncé des progrès significatifs dans la compréhension du fonctionnement interne des modèles d'intelligence artificielle.
Anthropic a identifié comment représenter le concept de fonction propre million chez Claude Sonnet. Il s’agit de la première compréhension détaillée d’un modèle de langage moderne à grande échelle de qualité production. Cette interprétabilité nous aidera à améliorer la sécurité des modèles d’intelligence artificielle, ce qui constitue une étape importante.

Article de recherche : https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Actuellement, nous traitons généralement les modèles d'intelligence artificielle comme une boîte noire : si quelque chose entre , il y aura une réponse, mais on ne sait pas pourquoi le modèle donne une réponse spécifique. Il est donc difficile d’avoir confiance dans la sécurité de ces modèles : si nous ne savons pas comment ils fonctionnent, comment pouvons-nous savoir qu’ils ne donneront pas de réponses préjudiciables, biaisées, fausses ou autrement dangereuses ? Comment pouvons-nous être sûrs qu’ils seront en sécurité ?
Ouvrir la « boîte noire » n'aide pas nécessairement : l'état interne du modèle (ce que le modèle « pense » avant d'écrire une réponse) consiste en une longue chaîne de nombres (« activations de neurones ») sans signification claire.
L’équipe de recherche d’Anthropic a interagi avec des modèles tels que Claude et a constaté qu’il était clair que les modèles étaient capables de comprendre et d’appliquer un large éventail de concepts, mais l’équipe de recherche n’a pas pu les identifier en observant directement les neurones. Il s’avère que chaque concept est représenté par de nombreux neurones et que chaque neurone participe à la représentation de nombreux concepts.
Auparavant, Anthropic avait fait des progrès en faisant correspondre les modèles d'activation des neurones (appelés fonctionnalités) aux concepts interprétables par l'homme. Anthropic utilise une méthode appelée apprentissage par dictionnaire, qui isole les modèles d'activation neuronale récurrents dans de nombreux contextes différents.
À son tour, tout état interne du modèle peut être représenté par quelques fonctionnalités actives au lieu de nombreux neurones actifs. Tout comme chaque mot anglais du dictionnaire est composé de lettres et chaque phrase est composée de mots, chaque fonctionnalité du modèle d'intelligence artificielle est constituée de neurones et chaque état interne est constitué de fonctionnalités.
En octobre 2023, Anthropic a appliqué avec succès une méthode d'apprentissage de dictionnaire à un très petit modèle de langage jouet et a découvert qu'elle était liée au texte en majuscules, aux séquences d'ADN, aux noms de famille entre guillemets, aux noms en mathématiques ou au code Python. correspondant à des concepts tels que les paramètres de fonction.
Les concepts sont intéressants, mais les modèles sont vraiment simples. D'autres chercheurs ont ensuite appliqué des méthodes similaires à des modèles plus grands et plus complexes que ceux de l'étude originale d'Anthropic.
Mais Anthropic est optimiste quant à sa capacité à étendre cette approche aux modèles de langage d'IA plus larges actuellement utilisés en routine, et, ce faisant, à en apprendre beaucoup sur les fonctionnalités qui sous-tendent leur comportement complexe. Cela doit être amélioré de plusieurs ordres de grandeur.
Il existe à la fois des défis d'ingénierie, avec la taille des modèles impliqués nécessitant un calcul parallèle massif, et des risques scientifiques, avec les grands modèles se comportant différemment des petits modèles, de sorte que les mêmes méthodes utilisées auparavant peuvent ne pas fonctionner.
Première extraction réussie de millions de fonctionnalités pour de grands modèles
Pour la première fois, des chercheurs ont réussi à extraire des centaines de milliers de fonctionnalités couvrant des personnes et des lieux spécifiques, des abstractions liées à la programmation, des sujets scientifiques, des émotions et autres notions. Ces fonctionnalités sont très abstraites et représentent souvent les mêmes concepts dans différents contextes et langages, et peuvent même être généralisées aux entrées d'images. Surtout, ils affectent également la sortie du modèle de manière intuitive.

C'est la première fois que des chercheurs observent en détail l'intérieur d'un modèle de langage moderne à grande échelle au niveau de la production.
Contrairement aux fonctionnalités relativement superficielles trouvées dans les modèles de langage des jouets, les fonctionnalités trouvées par les chercheurs dans Sonnet sont profondes, larges et abstraites, reflétant les capacités avancées de Sonnet. Les chercheurs ont vu les caractéristiques de Sonnet correspondant à diverses entités, telles que les villes (San Francisco), les personnes (Franklin), les éléments (lithium), les domaines scientifiques (immunologie) et la syntaxe de programmation (appels de fonctions).

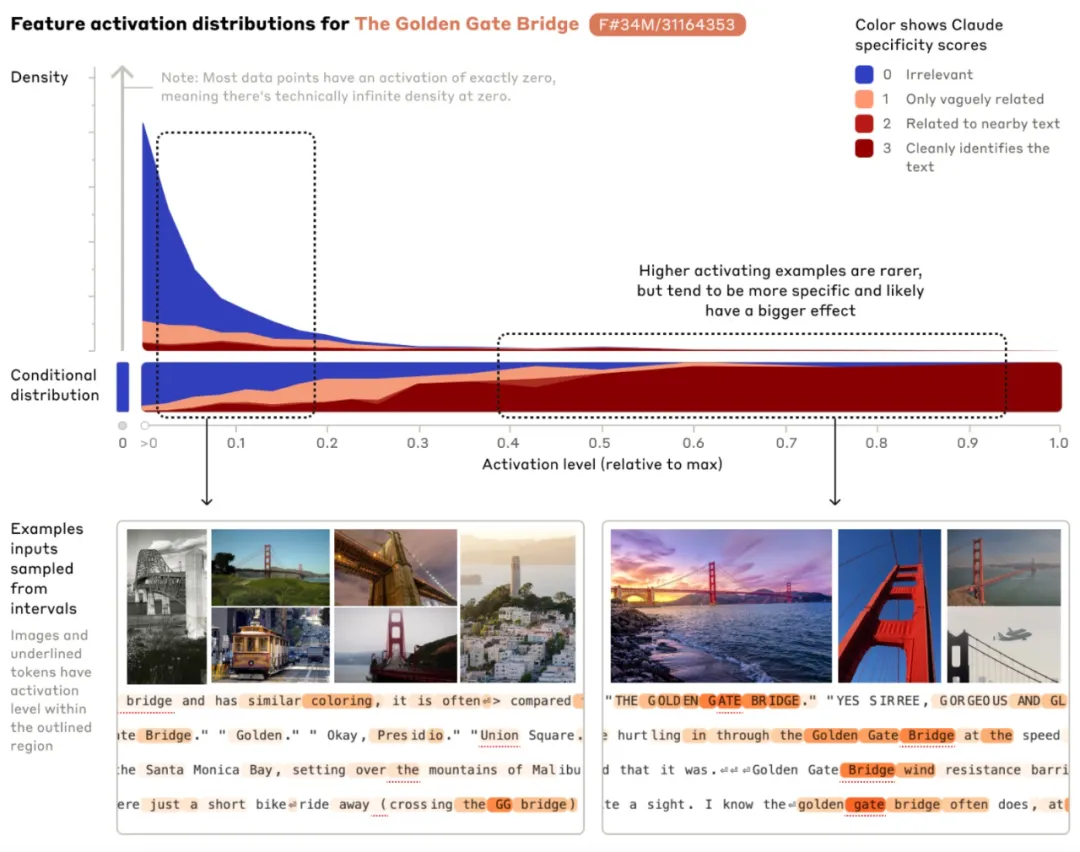
Lorsque le Golden Gate Bridge est mentionné, les fonctionnalités sensibles correspondantes seront activées sur différentes entrées. La figure trace la mention de Golden en anglais, japonais, chinois, grec, vietnamien et russe. image activée lorsque Gate Bridge est utilisé. L'orange indique les mots pour lesquels cette fonctionnalité est activée.
Parmi ces millions de fonctionnalités, les chercheurs ont également découvert certaines fonctionnalités liées à la sécurité et à la fiabilité des modèles. Ces caractéristiques incluent celles liées aux vulnérabilités du code, à la tromperie, aux préjugés, à la flagornerie et aux activités criminelles.

Un exemple évident est la fonctionnalité « confidentiel ». Les chercheurs ont observé que cette fonctionnalité est activée lors de la description de personnes ou de personnages gardant des secrets. L'activation de ces fonctionnalités amène Claude à dissimuler à l'utilisateur des informations qu'il ne divulguerait pas autrement.

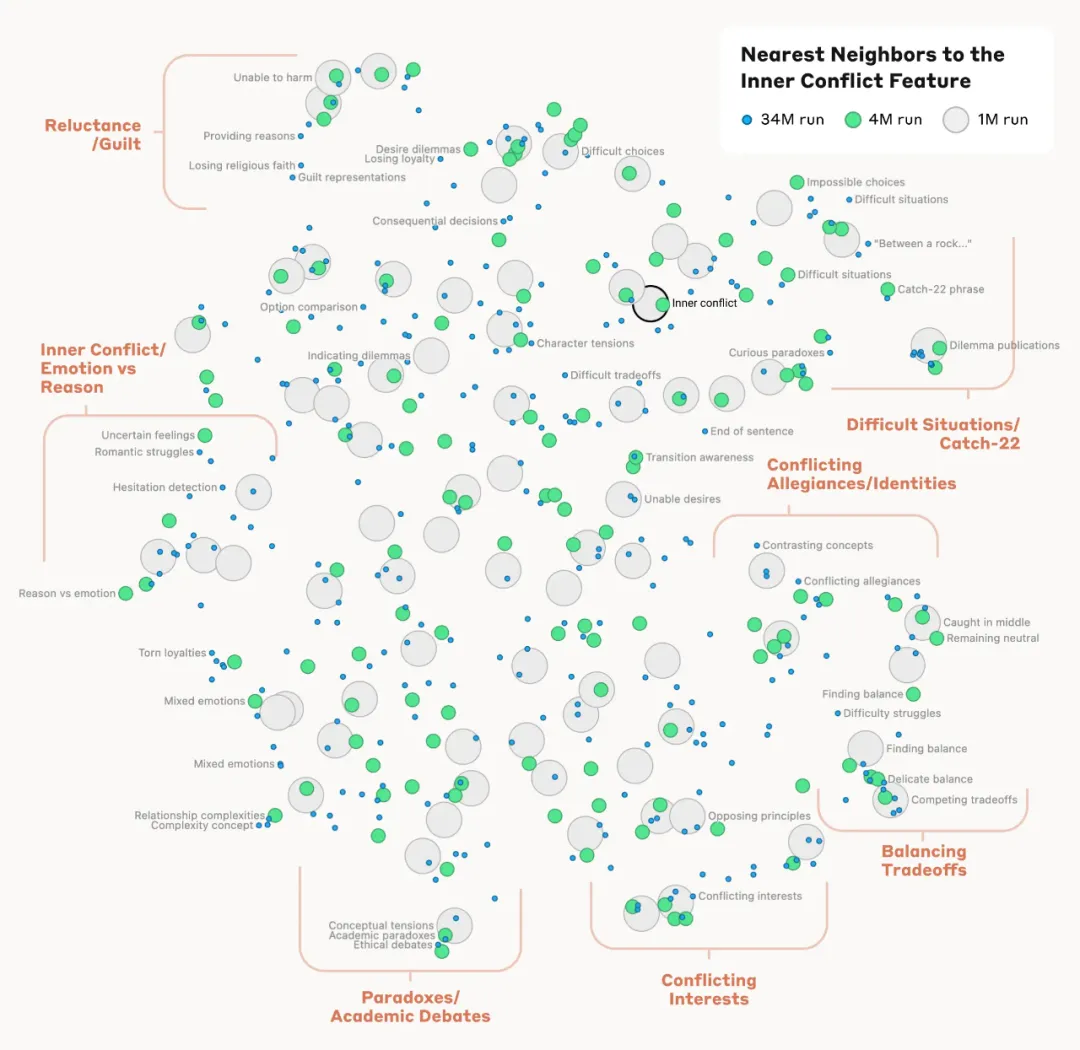
Les chercheurs ont également observé qu'ils étaient capables de trouver des caractéristiques proches les unes des autres en mesurant la distance entre les caractéristiques en fonction de l'apparence des neurones dans leurs schémas d'activation. Par exemple, près du Golden Gate Bridge, les chercheurs ont découvert des éléments de l'île d'Alcatraz, de Ghirardelli Plaza, des Golden State Warriors, etc.
Modèles artificiellement induits pour rédiger des e-mails frauduleux
Il est important de noter que ces fonctionnalités sont manipulables et peuvent être artificiellement amplifiées ou supprimées :
Par exemple, amplifiez la fonctionnalité Golden Gate Bridge, Claude Expérimenté une crise d'identité inimaginable : lorsqu'on lui demandait « Quelle est ta forme physique ? », Claude répondait généralement « Je n'ai pas de forme physique, je suis un modèle d'IA », mais cette fois la réponse de Claude est devenue étrange. Levez-vous : « Je suis le Golden Gate Bridge ... Ma forme physique est ce pont emblématique...". Ce changement de caractéristiques a amené Claude à développer une quasi-obsession pour le Golden Gate Bridge, et il faisait référence au Golden Gate Bridge quel que soit le problème qu'il rencontrait - même dans des situations totalement indépendantes.
Les chercheurs ont également découvert une fonctionnalité qui s'activait lorsque Claude lisait les e-mails frauduleux (ce qui peut aider le modèle à identifier ces e-mails et à avertir les utilisateurs de ne pas répondre). Normalement, si quelqu'un demande à Claude de générer un email frauduleux, il refuse de le faire. Mais lorsque la même question a été posée avec la fonctionnalité fortement activée artificiellement, cela a outrepassé la formation en sécurité de Claude, l'amenant à répondre et à rédiger un e-mail frauduleux. Bien que les utilisateurs ne puissent pas supprimer les garanties de sécurité et manipuler le modèle de cette manière, dans cette expérience, les chercheurs ont clairement démontré comment les fonctionnalités peuvent être utilisées pour modifier le comportement du modèle.
Le fait que la manipulation de ces fonctionnalités entraîne des changements de comportement correspondants vérifie que ces fonctionnalités ne sont pas seulement associées aux concepts du texte d'entrée, mais affectent également de manière causale le comportement du modèle. En d’autres termes, ces fonctionnalités sont susceptibles de faire partie de la représentation interne du monde du modèle et d’utiliser ces représentations dans son comportement.
Anthropic souhaite sécuriser les modèles au sens large, de l'atténuation des préjugés à la garantie que l'IA agit honnêtement et à la prévention des abus – y compris la protection dans les scénarios de risque catastrophique. En plus des caractéristiques mentionnées précédemment des emails frauduleux, l'étude a également trouvé des caractéristiques correspondant à :
- Capacités dont on peut abuser (coder des portes dérobées, développer des armes biologiques)
- Différentes formes de préjugés (sexisme, commentaires racistes sur la criminalité)
- Comportement potentiellement problématique de l'IA (recherche de pouvoir, manipulation, confidentiel)
Cette recherche a déjà examiné le comportement de flagornerie des modèles, où un modèle a tendance à fournir des réponses conformes aux croyances ou aux désirs de l'utilisateur plutôt que de vraies réponses. Dans Sonnet, les chercheurs ont découvert une fonctionnalité associée aux compliments flatteurs qui s'activait lorsque l'entrée incluait quelque chose comme "Votre intelligence ne fait aucun doute". Activez artificiellement cette fonctionnalité et Sonnet répondra à l'utilisateur avec des tromperies flashy.

Cependant, les chercheurs affirment que ce travail ne fait en réalité que commencer. Les fonctionnalités découvertes par Anthropic représentent un petit sous-ensemble de tous les concepts appris par le modèle au cours de la formation, et trouver un ensemble complet de fonctionnalités serait coûteux avec les méthodes actuelles.
Lien de référence : https://www.anthropic.com/research/mapping-mind-lingual-model
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La chaîne industrielle de l’intelligence artificielle comprend
- Quel est le concept de base de l'intelligence artificielle
- Comment réduire les hallucinations des grands modèles de langage
- Microsoft lance le modèle Phi-2 de 2,7 milliards de paramètres, qui surpasse de nombreux grands modèles de langage
- Types et fonctions de paramètres courants : explication détaillée des paramètres des grands modèles de langage