
Maison >Périphériques technologiques >IA >Yann LeCun : ViT est lent et inefficace. Le traitement des images en temps réel repose encore sur la convolution.
Yann LeCun : ViT est lent et inefficace. Le traitement des images en temps réel repose encore sur la convolution.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-06 13:25:021151parcourir
À l'ère de l'unification de Transformer, est-il encore nécessaire d'étudier l'orientation CNN de la vision par ordinateur ?
Au début de cette année, le grand modèle vidéo d'OpenAI, Sora, a rendu populaire l'architecture Vision Transformer (ViT). Depuis lors, un débat est en cours pour savoir qui est le plus puissant, ViT ou les réseaux de neurones convolutifs (CNN) traditionnels.
Récemment, Yann LeCun, lauréat du prix Turing, scientifique en chef de Meta et actif sur les réseaux sociaux, a également rejoint la discussion sur le différend entre ViT et CNN.

La cause de cet incident était que Harald Schäfer, CTO de Comma.ai, montrait ses dernières recherches. Il (comme de nombreux chercheurs récents en IA) reprend l'expression de Yann LeCun selon laquelle bien que le magnat du prix Turing estime que le ViT pur n'est pas pratique, nous avons récemment changé notre compresseur en ViT pur. Il n'y a pas de gain rapide et cela prendra plus de temps, mais. l'effet est très bon.
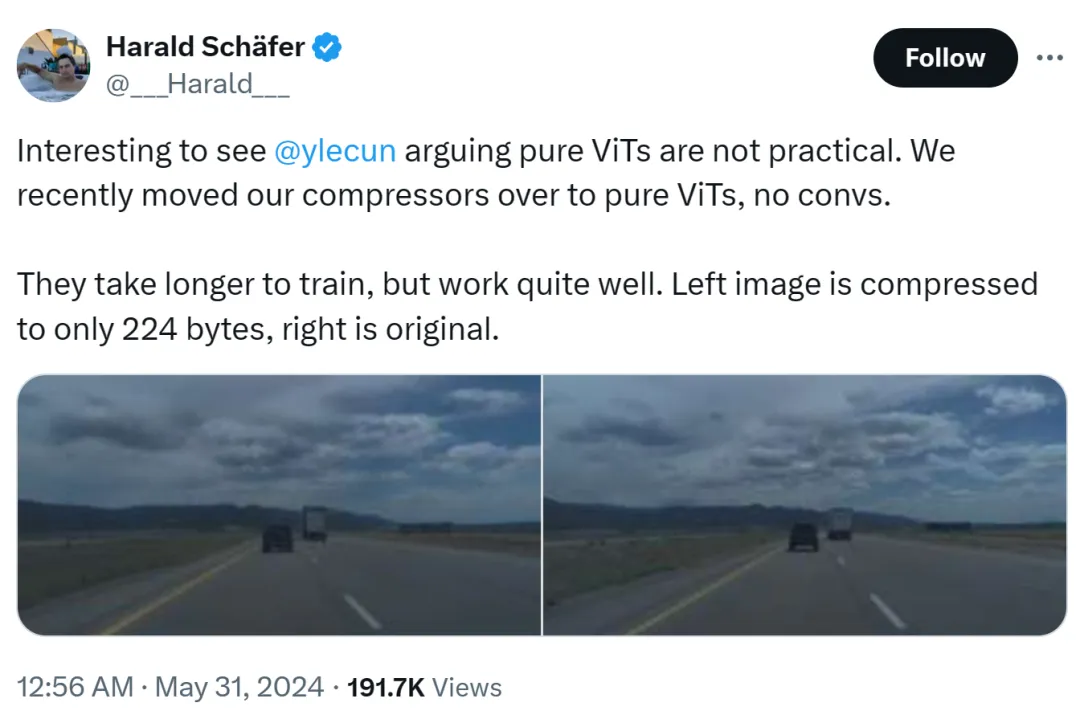
Par exemple, l'image de gauche est compressée à seulement 224 octets et celle de droite est l'image originale.
ne fait que 14×128, ce qui est très grand pour un modèle mondial de conduite autonome, ce qui signifie qu'une grande quantité de données peut être saisie pour l'entraînement. La formation dans un environnement virtuel est moins coûteuse que dans un environnement réel, où les agents doivent être formés conformément aux politiques pour fonctionner correctement. Des résolutions plus élevées pour l’entraînement virtuel fonctionneront mieux, mais le simulateur deviendra très lent, une compression est donc actuellement nécessaire.
Sa démonstration a suscité des discussions dans le cercle de l'IA, et Eric Jang, vice-président de l'intelligence artificielle chez 1X, a répondu que les résultats étaient étonnants.
Harald a continué à faire l'éloge de ViT : C'est une très belle architecture.
Quelqu'un a commencé à s'offusquer ici : des maîtres comme LeCun ne parviennent parfois pas à suivre le rythme de l'innovation.
Cependant, Yann LeCun a rapidement répondu et fait valoir qu'il ne disait pas que le ViT n'est pas pratique, et que tout le monde l'utilise maintenant. Ce qu'il veut exprimer, c'est que ViT est trop lent et inefficace, ce qui le rend inadapté au traitement en temps réel de tâches d'images et de vidéos haute résolution.
Yann LeCun a également Cue Xie Saining, professeur adjoint à l'Université de New York, dont les travaux ConvNext ont prouvé que CNN peut être aussi bon que ViT si la méthode est bonne.
Il poursuit en disant que vous avez besoin d'au moins quelques couches convolutives avec mise en commun et foulées avant de vous en tenir à une boucle d'auto-attention.
Si l'attention personnelle équivaut à une permutation, cela n'a aucun sens pour le traitement d'images ou de vidéos de bas niveau, pas plus que la patchification en utilisant une seule foulée sur le front-end. De plus, étant donné que la corrélation dans les images ou les vidéos est fortement concentrée au niveau local, l’attention globale n’a aucun sens et n’est pas évolutive.
À un niveau supérieur, une fois que les caractéristiques représentent des objets, il est logique d'utiliser une boucle d'auto-attention : ce sont les relations et les interactions entre les objets qui comptent, pas leur emplacement. Cette architecture hybride a été lancée par le système DETR complété par Nicolas Carion, chercheur en Meta, et ses co-auteurs.
Depuis l'émergence des travaux DETR, Yann LeCun a déclaré que son architecture préférée est la convolution/foulée/pooling de bas niveau et la boucle d'auto-attention de haut niveau.
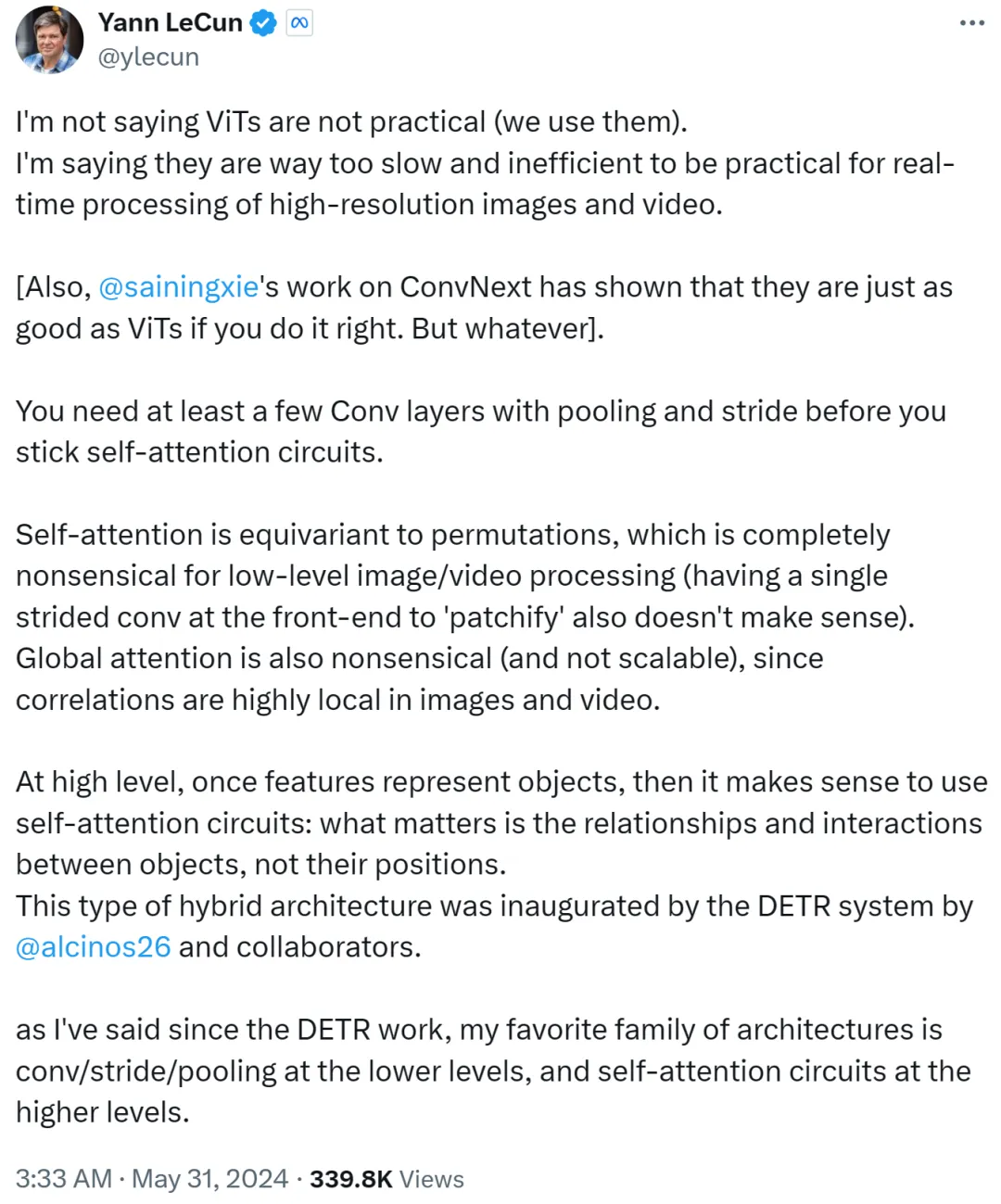
Yann LeCun l'a résumé dans le deuxième post : utilisez la convolution avec la foulée ou le pooling à bas niveau, utilisez la boucle d'auto-attention à haut niveau et utilisez des vecteurs de caractéristiques pour représenter des objets.
Il parie également que Tesla Fully Self-Driving (FSD) utilise des convolutions (ou des opérateurs locaux plus complexes) à bas niveaux, combinées à des boucles plus globales à des niveaux plus élevés (utilisant éventuellement l'auto-attention). Par conséquent, utiliser Transformers sur des intégrations de correctifs de bas niveau est un gaspillage total.
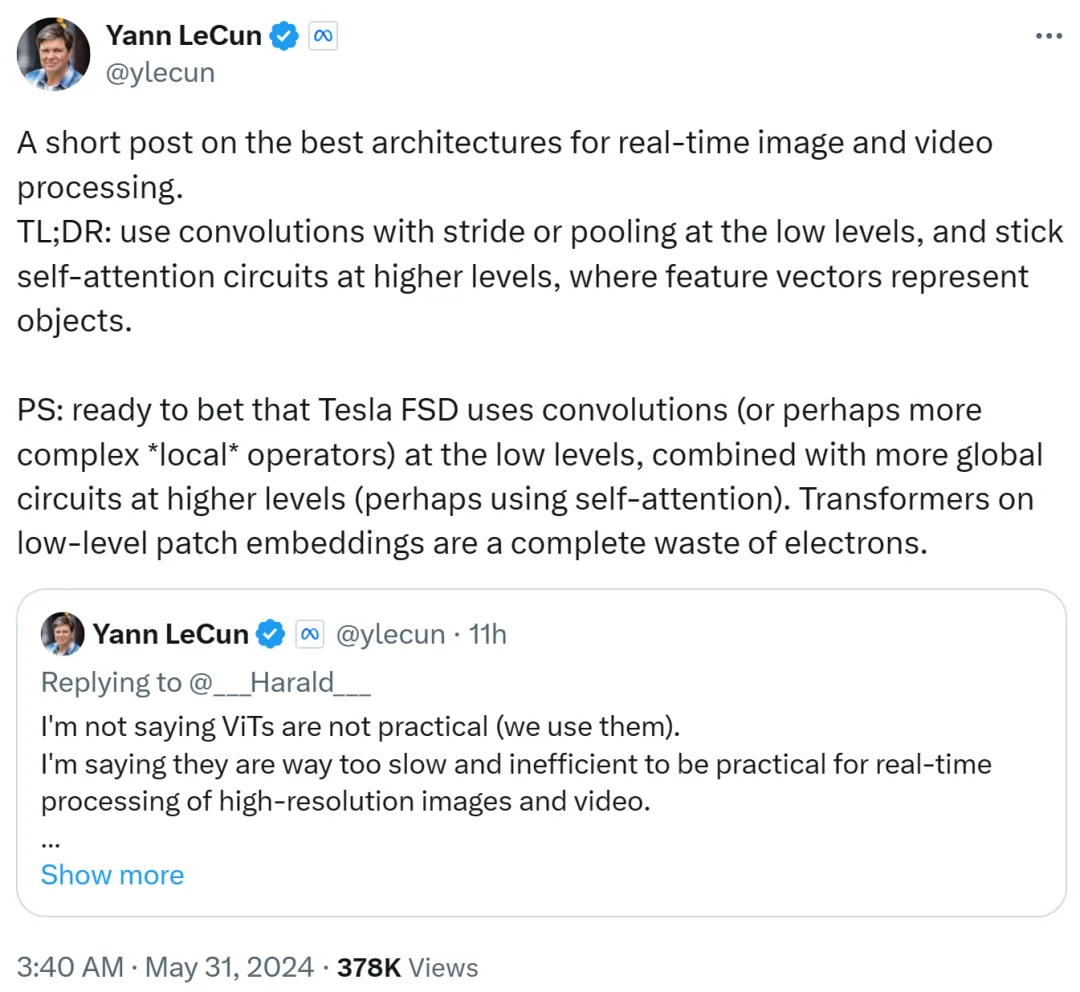
Je suppose que l'ennemi juré Musk utilise toujours la voie de la convolution.
Xie Senin a également exprimé son opinion. Il estime que ViT est très adapté aux images basse résolution de 224x224, mais que se passe-t-il si la résolution de l'image atteint 1 million x 1 million ? À l'heure actuelle, soit la convolution est utilisée, soit ViT est corrigé et traité à l'aide de poids partagés, ce qui est toujours de nature convolution.
Par conséquent, Xie Senin a déclaré qu'à ce moment-là, il avait réalisé que le réseau convolutionnel n'est pas une architecture, mais une façon de penser.
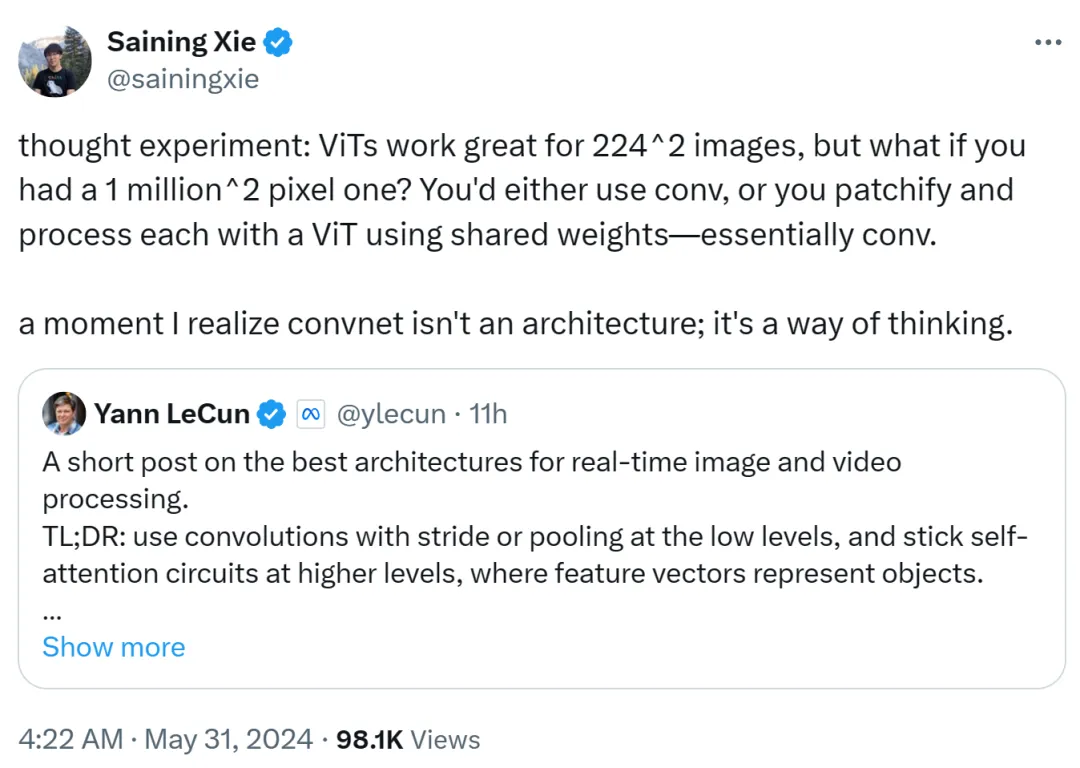
Cette vue est reconnue par Yann LeCun.

Lucas Beyer, chercheur chez Google DeepMind, a également déclaré que grâce au remplissage nul des réseaux convolutifs conventionnels, il est sûr que la "convolution ViT" (plutôt que ViT + convolution) fonctionnera bien .
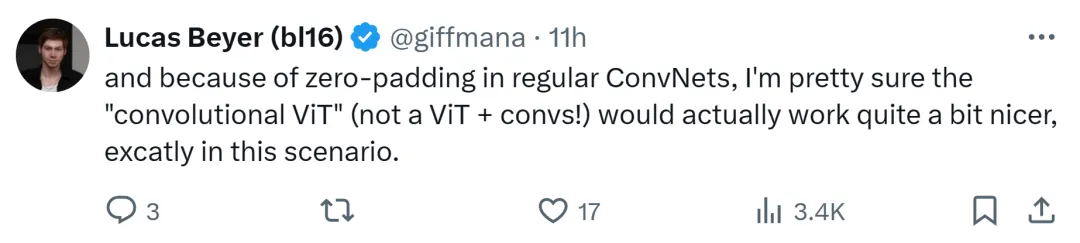
Il est prévisible que ce débat entre ViT et CNN se poursuivra jusqu'à ce qu'une autre architecture plus puissante émerge dans le futur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les fichiers ai peuvent-ils être ouverts avec ps ?
- Que signifie le courrier électronique ?
- Quatre façons dont la vision par ordinateur va remodeler les transports urbains
- Techniques de traitement d'images et de vision par ordinateur en Java
- Comment utiliser le C++ pour le traitement d'images et la vision par ordinateur hautes performances ?