
Maison >Périphériques technologiques >IA >Pour améliorer l'utilisation des ensembles de données optiques, l'équipe Tianda a proposé un modèle d'IA pour améliorer l'effet de prédiction spectrale
Pour améliorer l'utilisation des ensembles de données optiques, l'équipe Tianda a proposé un modèle d'IA pour améliorer l'effet de prédiction spectrale

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-06 12:09:28734parcourir

Editeur | Dead Leaf Butterfly
Récemment, l'équipe du professeur agrégé Wu Liang et de l'académicien Yao Jianquan de l'Institut de laser et d'optoélectronique de l'Université de Tianjin et l'équipe du professeur Xiong Deyi du Laboratoire de traitement du langage naturel ont rapporté une profonde modèle d'apprentissage qui utilise une entrée supplémentaire multifréquence pour les solutions pour améliorer les performances de prédiction spectrale. Ce schéma peut améliorer la précision de la prédiction spectrale en utilisant des données d'entrée multifréquences. De plus, cette solution peut également réduire les interférences sonores dans le processus de prédiction spectrale, améliorant ainsi l'effet de prédiction.
Cette solution peut améliorer l'utilisation des ensembles de données optiques existants et améliorer l'effet de prédiction de la réponse spectrale correspondant à la structure de la métasurface sans augmenter le coût de formation.
Les résultats de la recherche pertinents étaient intitulés « Enhanced Spectrum Prediction using Deep Learning Models with Multi- Frequency Supplemental Inputs » et ont été publiés dans « APL Machine Learning » le 16 mai 2024.

Lien papier : https://doi.org/10.1063/5.0203931
Contexte de recherche
Ces dernières années, le développement rapide de la technologie d'apprentissage profond a apporté des changements et des innovations sans précédent dans divers domaines. Il est devenu un outil efficace pour traiter des données complexes et volumineuses dans plusieurs disciplines.
Les méthodes basées sur les réseaux de neurones peuvent détecter efficacement les caractéristiques pertinentes et les modèles potentiels de données cibles, mais certains défis subsistent si les modèles d'apprentissage profond apprennent directement ces données associées provenant de différents domaines et de différents formats. Pour résoudre ce problème, des techniques d’extraction de fonctionnalités peuvent être utilisées. Les techniques d'extraction de fonctionnalités peuvent transformer les données brutes en une représentation adaptée à une tâche spécifique. Différentes méthodes d'extraction de caractéristiques peuvent être utilisées, telles que la FFT basée sur l'analyse du domaine fréquentiel, la WT basée sur la transformée en ondelettes, etc. En appliquant ces technologies, différents domaines peuvent être combinés.
Ces dernières années, les domaines de recherche qui combinent la technologie du deep learning sont généralement confrontés à des problèmes tels que la petite taille et la faible qualité des ensembles de données existants, ce qui affecte l'effet d'apprentissage du modèle sur le tâche cible.
Dans l'ensemble du processus de recherche « AI for Science », la partie la plus coûteuse est principalement la construction d'ensembles de données. Il est donc crucial de savoir comment utiliser plus efficacement les ensembles de données existants.
L'équipe de l'Université de Tianjin a prouvé par des recherches que l'ajout d'informations d'entrée multifréquence supplémentaires à l'ensemble de données existant pendant le processus de prédiction du spectre cible peut améliorer considérablement la précision de la prédiction du réseau. Cette approche fournit de nouvelles idées pour l'utilisation d'ensembles de données pour la recherche interdisciplinaire et les applications dans l'apprentissage profond et dans d'autres domaines tels que la photonique, la conception de matériaux composites et la biomédecine.
Points forts de la recherche
Le point innovant de la recherche est de proposer l'idée de diviser les informations spectrales dans toute la gamme de fréquences, ce qui se manifeste par la combinaison des exigences de conception réelles et la division des informations spectrales pleine fréquence en apprentissage. tâches en fonction de la partie de fréquence de travail et de la partie de fréquence de non-travail.
Pour démontrer l'universalité de cette solution, la bande de fréquences de fonctionnement cible a été affinée en partie informations basse fréquence (0-1 THz) et partie informations haute fréquence (1-2 THz) pour démontrer l'effet amélioré de l'apprentissage du modèle.
Par rapport à la prédiction directe des données de plage de fréquence de travail, après avoir complété d'autres informations de fréquence, l'erreur globale de prédiction des données du spectre de transmission a chuté d'environ 80 %. Parmi eux, le modèle basé sur le transformateur après avoir complété les informations basse fréquence, l'erreur de prédiction. était seulement Pour environ 40 % des prédictions directes, la structure de la métasurface conçue et l'architecture du modèle sont présentées dans la figure 1 :
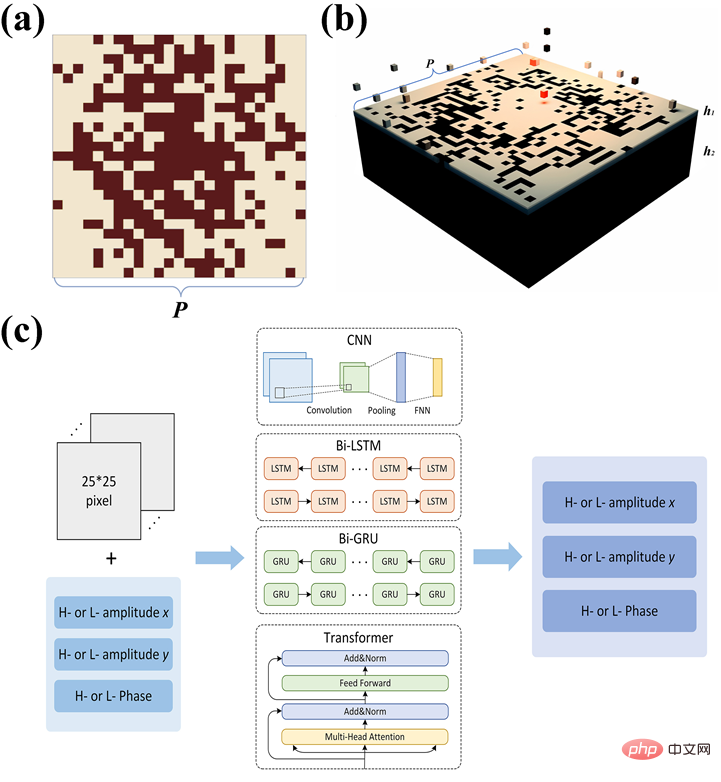
Afin d'afficher de manière plus intuitive l'effet de prédiction des paramètres d'amplitude et de phase à différentes fréquences de fonctionnement après optimisation, certaines structures de métasurface sont sélectionnées au hasard pour une démonstration de simulation dans le logiciel CST Studio Suite, comme le montre la figure 2 :

Figure 2 Diagramme schématique de l'effet de prédiction des données optimisées haute fréquence et basse fréquence. (a) - (f) Démontrer les différentes performances de prédiction du modèle de réseau optimisé dans différentes plages de fréquences en comparant les données réelles (ligne continue violette) avec les données prédites (ligne pointillée noire). Les zones vertes représentent les données d'informations de fréquence utilisées comme entrée supplémentaire, tandis que les zones jaunes représentent les zones utilisées pour valider les performances de prédiction optimisées. où a et b représentent les résultats de prédiction des amplitudes haute fréquence et basse fréquence de l’état de polarisation x. (c) - (d) Résultats de prédiction des amplitudes haute fréquence et basse fréquence de l'état de polarisation y. (e) - (f) Résultats de prédiction des phases haute fréquence et basse fréquence.
Résumé et perspectives
Cette recherche améliore efficacement l'efficacité d'utilisation des ensembles de données existants en divisant les ensembles de données de manière ciblée pour les tâches d'apprentissage de différents problèmes optiques, améliorant ainsi l'effet d'apprentissage du modèle d'apprentissage en profondeur.
Cette solution d'optimisation atténue efficacement le problème des petits ensembles de données optiques existants (en particulier les ensembles de données associés dans la bande térahertz) et propose également davantage de domaines de recherche combinant technologie d'apprentissage en profondeur et données coûteuses, tels que la conception de matériaux composites et l'analyse d'images médicales. , la prédiction des données financières, etc. offrent une nouvelle perspective pour l'optimisation des ensembles de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Théorie des expressions régulières PHP
- Introduction détaillée à la théorie MySQL et aux connaissances de base
- Quelle théorie du programme est à la base du système de gestion du stockage virtuel ?
- L'Université de Pékin et Alibaba créent un laboratoire commun pour se concentrer sur la théorie de l'intelligence artificielle et la recherche sur les algorithmes innovants
- 'Appel à innovation : UCL Wang Jun discute de la théorie et des perspectives d'application de l'intelligence artificielle générale ChatGPT'