
Maison >Périphériques technologiques >IA >Nouvelle recherche de NVIDIA : la longueur du contexte est sérieusement fausse et peu de performances 32K sont qualifiées
Nouvelle recherche de NVIDIA : la longueur du contexte est sérieusement fausse et peu de performances 32K sont qualifiées

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-05 16:22:471195parcourir
Exposer sans pitié le faux phénomène standard des grands modèles à « contexte long » -
La nouvelle recherche de NVIDIA a révélé que 10 grands modèles, dont GPT-4, génèrent des longueurs de contexte de 128 Ko, voire 1 M.
Mais après quelques tests, le nouvel indicateur « contexte effectif » a sérieusement diminué, et peu de gens peuvent atteindre 32K.
Le nouveau benchmark s'appelle RULER, qui comprend récupération, suivi multi-sauts, agrégation et questions et réponses 4 catégories avec un total de 13 tâches. RULER définit la « longueur de contexte effective », qui est la longueur maximale à laquelle le modèle peut maintenir les mêmes performances que la ligne de base du Llama-7B à une longueur de 4K.

Cette étude a été jugée « très perspicace » par les universitaires.

Après avoir vu cette nouvelle recherche, de nombreux internautes ont également voulu voir les résultats du défi des joueurs rois de la longueur du contexte Claude et Gémeaux. (Non couvert dans le document)


Jetons un coup d'œil à la manière dont NVIDIA définit l'indicateur de « contexte effectif ».

Il existe des tâches de test de plus en plus difficiles
Pour évaluer la capacité de compréhension de textes longs des grands modèles, vous devez d'abord choisir un bon standard, tel que ZeroSCROLLS, L-Eval, LongBench, InfiniteBench, etc. populaire dans le cercle, ou simplement évaluer. La capacité de récupération du modèle est soit limitée par l'interférence des connaissances antérieures.
Ainsi, la méthode RULER éliminée par NVIDIA peut être résumée en une phrase comme suit « Assurez-vous que l'évaluation se concentre sur la capacité du modèle à traiter et à comprendre un contexte long, plutôt que sur la capacité à rappeler des informations à partir des données d'entraînement » . Les données d'évaluation de
RULER réduisent le recours aux « connaissances paramétrées », qui sont les connaissances que le grand modèle a codées dans ses propres paramètres au cours du processus de formation.
Plus précisément, le benchmark RULER étend le test populaire « une aiguille dans une botte de foin » en ajoutant quatre nouvelles catégories de tâches.
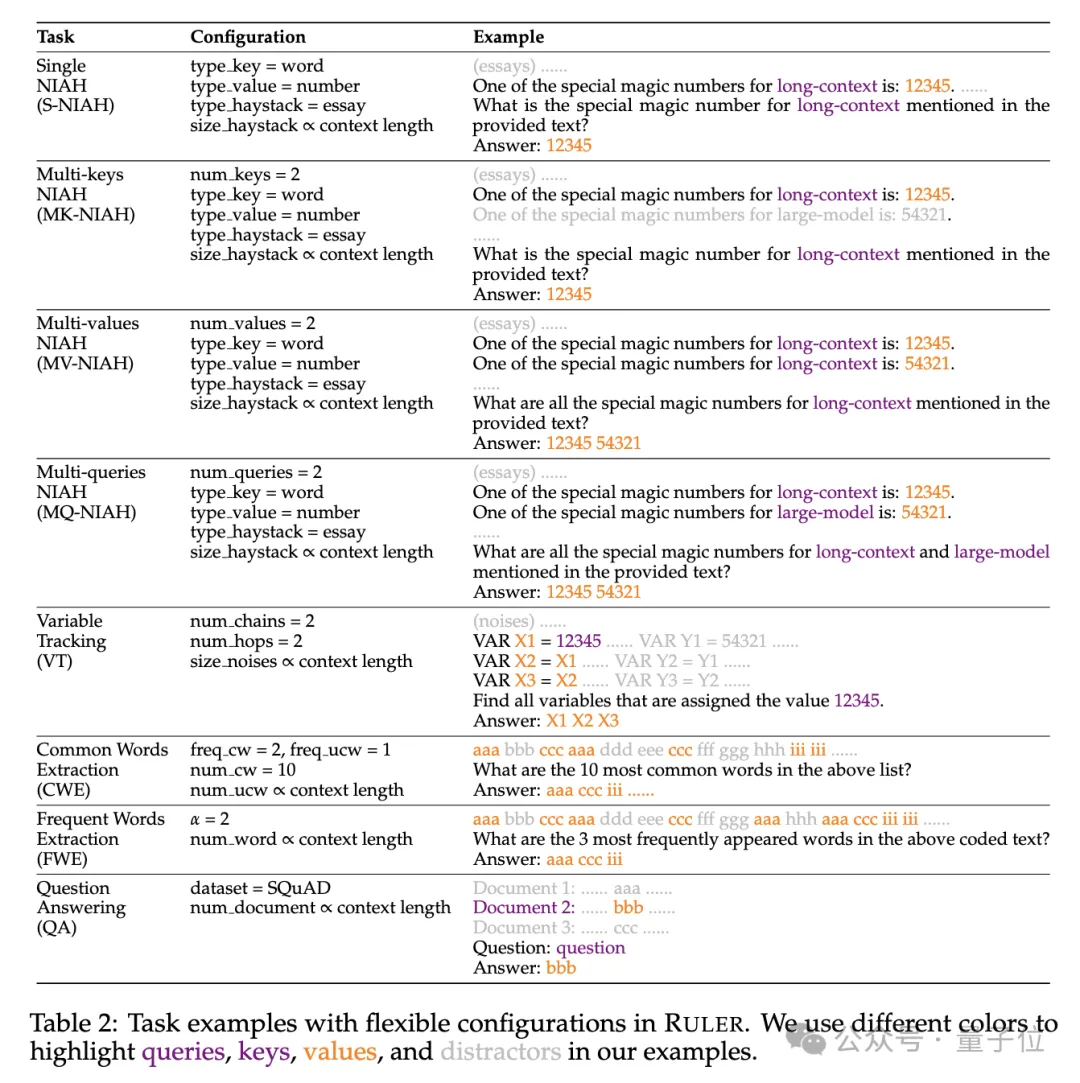
En termes de récupération, à partir de la tâche standard de récupération à une seule clé consistant à trouver une aiguille dans une botte de foin, les nouveaux types suivants ont été ajoutés :
- Récupération multi-clés (Multi -keys NIAH, MK-NIAH) : Plusieurs broches d'interférence sont insérées dans le contexte et le modèle doit récupérer celle spécifiée
- Récupération multi-valeurs (Multi-valeurs NIAH, MV-NIAH ) : Une clé(key) correspond à plusieurs valeurs (values), le modèle doit récupérer toutes les valeurs associées à une clé spécifique.
- Récupération multi-requêtes (Multi-requêtes NIAH, MQ-NIAH) : Le modèle doit récupérer plusieurs aiguilles correspondantes dans le texte en fonction de plusieurs requêtes.
En plus de la version améliorée de la récupération, RULER ajoute également le défi Traçage multi-sauts (Traçage multi-sauts).
Plus précisément, les chercheurs ont proposéVariable Tracking(VT), qui simule la tâche minimale de résolution de coréférence, exigeant que le modèle suive la chaîne d'affectation des variables dans le texte, même si ces affectations sont dans le texte. non continu. Le troisième niveau du défi est
Agrégation(Agrégation), comprenant :
- Extraction de mots communs
- (CWE) : Le modèle doit extraire les mots les plus courants du texte. Frequent Words Extraction
- (Frequent Words Extraction, FWE) : similaire à CWE, mais la fréquence d'un mot est déterminée en fonction de son classement dans le vocabulaire et du paramètre de distribution Zeta α.
Le quatrième niveau du défi est la Tâche de questions et réponses (QA) Sur la base de l'ensemble de données de compréhension en lecture existant (tel que SQuAD), un grand nombre de paragraphes d'interférence sont insérés pour tester la longue séquence. Capacité d’assurance qualité.
Quelle est la durée réelle de chaque contexte de modèle ?
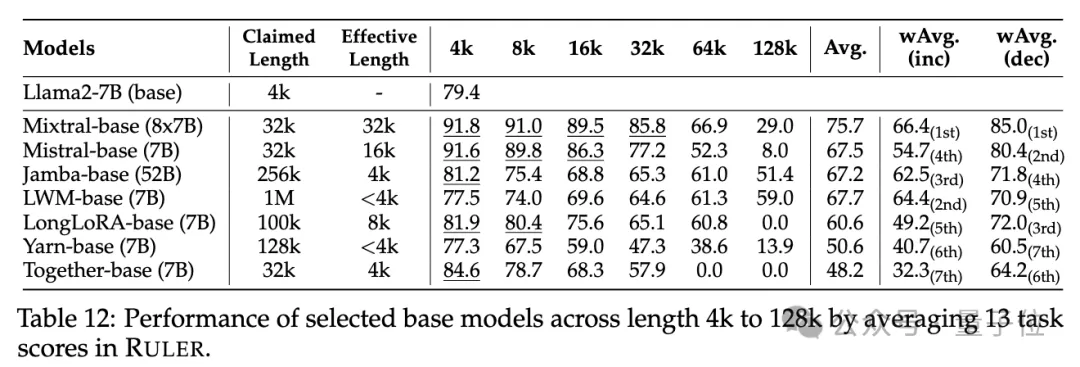
Dans la phase expérimentale, comme mentionné au début, les chercheurs ont évalué 10 modèles de langage prétendant prendre en charge un contexte long, dont GPT-4, et 9 modèles open source Command-R, Yi-34B, Mixtral (8x7B), Mixtral ( 7B), ChatGLM, LWM, Ensemble, LongChat, LongAlpaca.
Ces tailles de paramètres de modèle vont de 6B à 8x7B avec l'architecture MoE, et la longueur maximale du contexte varie de 32K à 1M.
Dans le test de référence RULER, chaque modèle a été évalué sur 13 tâches différentes, couvrant 4 catégories de tâches, allant de la difficulté simple à la difficulté complexe. Pour chaque tâche, 500 échantillons de test sont générés, avec des longueurs d'entrée allant de 4K à 128K sur 6 niveaux (4K, 8K, 16K, 32K, 64K, 128K).
 Pour éviter que le modèle refuse de répondre à la question, l'entrée est ajoutée à un préfixe de réponse et la présence de la sortie cible est vérifiée en fonction de la précision basée sur le rappel.
Pour éviter que le modèle refuse de répondre à la question, l'entrée est ajoutée à un préfixe de réponse et la présence de la sortie cible est vérifiée en fonction de la précision basée sur le rappel.
 Les chercheurs ont également défini la métrique de « longueur de contexte effective », c'est-à-dire que le modèle peut maintenir le même niveau de performance que le Llama-7B de base à une longueur de 4K à cette longueur.
Les chercheurs ont également défini la métrique de « longueur de contexte effective », c'est-à-dire que le modèle peut maintenir le même niveau de performance que le Llama-7B de base à une longueur de 4K à cette longueur.
Pour une comparaison plus détaillée des modèles, le score moyen pondéré
(Weighted Average, wAvg)est utilisé comme indicateur complet pour effectuer une moyenne pondérée des performances à différentes longueurs. Deux schémas de pondération sont adoptés :
wAvg(inc) : Le poids augmente linéairement avec la longueur, simulant des scénarios d'application dominés par de longues séquences- wAvg(dec) : Le poids diminue linéairement avec la longueur, simulant principalement des scènes de séquences courtes
- pour voir le résultat.
Aucune différence n'est visible dans les tests ordinaires de récupération de mot de passe et d'aiguille dans une botte de foin, presque tous les modèles obtenant des scores parfaits dans la plage de longueur de contexte revendiquée.
Avec RULER, bien que de nombreux modèles prétendent être capables de gérer des contextes de 32 000 jetons ou plus, aucun modèle, à l'exception de Mixtral, ne maintient des performances dépassant la ligne de base Llama2-7B à sa longueur revendiquée.
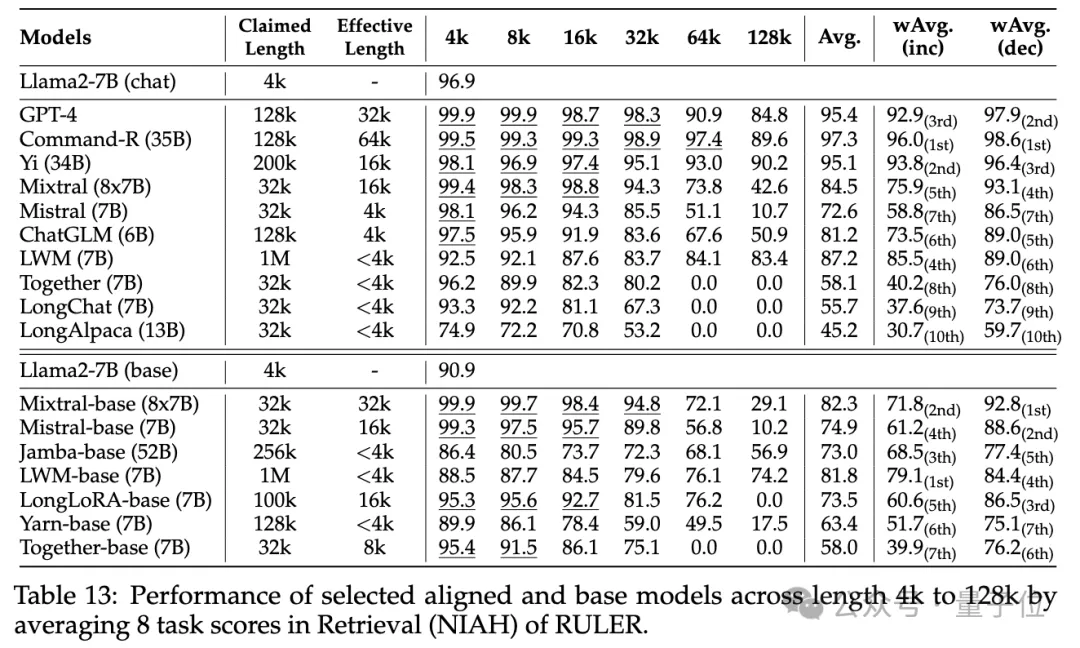
 Les autres résultats sont les suivants. Dans l'ensemble, GPT-4 fonctionne mieux à une longueur de 4K et présente une dégradation minime des performances
Les autres résultats sont les suivants. Dans l'ensemble, GPT-4 fonctionne mieux à une longueur de 4K et présente une dégradation minime des performances
lorsque le contexte est étendu à 128K. Les trois principaux modèles open source sont Command-R, Yi-34B et Mixtral, qui utilisent tous une fréquence de base RoPE plus grande et ont plus de paramètres que les autres modèles.

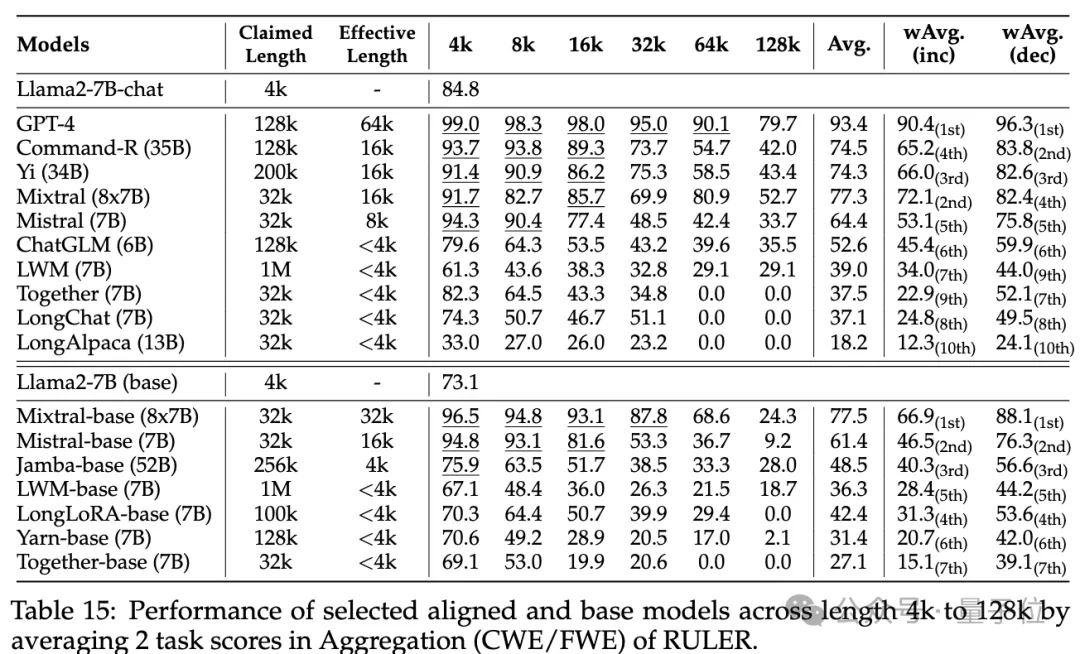
 De plus, les chercheurs ont mené une analyse approfondie des performances du modèle Yi-34B-200K sur des longueurs d'entrée croissantes
De plus, les chercheurs ont mené une analyse approfondie des performances du modèle Yi-34B-200K sur des longueurs d'entrée croissantes
et des tâches plus complexes pour comprendre les tâches Impact de la configuration et des modes de défaillance sur RULER. Ils ont également analysé l'impact de la longueur du contexte d'entraînement, de la taille et de l'architecture du modèle sur les performances du modèle et ont constaté que l'entraînement avec des contextes
plus grands conduit généralement à de meilleures performances, mais le classement des longues séquences peut être incohérent en augmentant la taille du modèle. pour la modélisation de contextes longs ; Pour plus de détails, les lecteurs intéressés peuvent consulter l'article original.
Lien papier : https://arxiv.org/abs/2404.06654
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La différence entre has et with dans le modèle d'association Laravel (introduction détaillée)
- Que signifie le modèle Python IPO ?
- Quel modèle de données la plupart des systèmes de gestion de bases de données utilisent-ils actuellement ?
- Nvidia prévoit de lancer la nouvelle génération de GPU Blackwell B100 au deuxième trimestre de l'année prochaine, en utilisant la mémoire HBM3E
- Les nouvelles réglementations américaines sur les exportations frappent NVIDIA, faisant chuter instantanément le cours de l'action de 8 %