La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. E-mail de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Dans le processus de formation de grands modèles de langage, la manière de traiter les données est cruciale. Les méthodes traditionnelles divisent et divisent généralement un grand nombre de documents en séquences de formation égales à la longueur du contexte du modèle. Bien que cela améliore l'efficacité de la formation, cela conduit souvent à une troncature inutile des documents, porte atteinte à l'intégrité des données et conduit à la perte d'informations contextuelles clés, ce qui à son tour affecte la cohérence logique et factuelle du contenu appris par le modèle, et rend le modèle plus efficace. modèle plus facile aux hallucinations. Les chercheurs d'AWS AI Labs ont mené des recherches approfondies sur cette méthode courante de traitement de texte par épissage et fragmentation et ont découvert qu'elle affecte sérieusement la capacité du modèle à comprendre la cohérence contextuelle et la cohérence factuelle. Cela affecte non seulement les performances du modèle sur les tâches en aval, mais augmente également le risque d'hallucinations. En réponse à ce problème, ils ont proposé une stratégie innovante de traitement des documents - Best-fit Packing (Best-fit Packing), qui élimine les troncatures de texte inutiles en optimisant la combinaison de documents et améliore considérablement les performances du modèle et réduit illusion de modèle. Cette recherche a été acceptée dans ICML 2024. 
Titre de l'article : Moins de troncatures améliorent la modélisation du langageLien papier : https://arxiv.org/pdf/2404.10830 Dans les grandes langues traditionnelles méthodes de formation de modèles, afin d'améliorer l'efficacité, les chercheurs assemblent généralement plusieurs documents d'entrée, puis segmentent ces documents épissés en séquences de longueur fixe. Bien que cette méthode soit simple et efficace, elle posera un problème majeur : la troncature des documents, qui porte atteinte à l'intégrité des données. La troncature d'un document entraîne une perte des informations contenues dans le document. De plus, la troncature des documents réduit la quantité de contexte dans chaque séquence, ce qui peut rendre la prédiction du mot suivant non pertinente par rapport au précédent, rendant le modèle plus sujet aux hallucinations. L'exemple suivant montre les problèmes causés par la troncature du document :
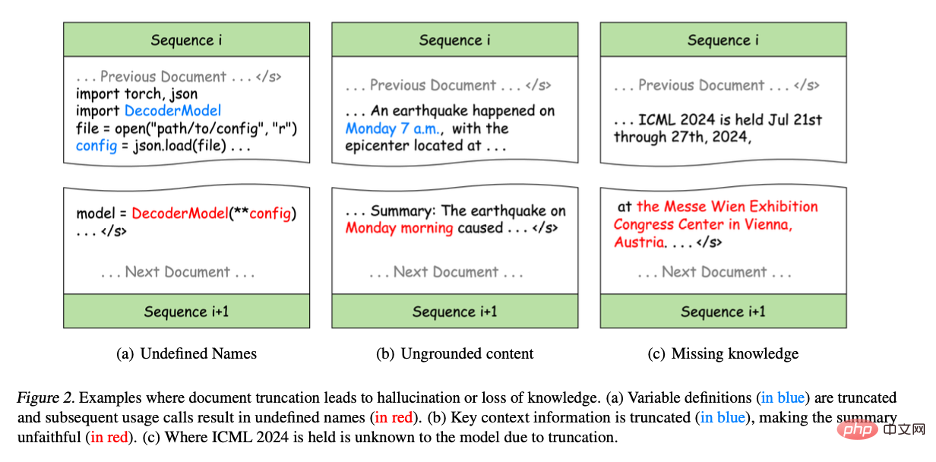
- Figure 2(a) : Dans la programmation Python, bien que le code d'origine soit correct, il divise la définition et l'utilisation des variables en différentes erreurs de syntaxe. sera introduit dans la séquence d'entraînement, ce qui entraînera la non-définition de certaines variables dans les séquences d'entraînement ultérieures, ce qui amènera le modèle à apprendre de mauvais modèles et éventuellement à créer des hallucinations dans les tâches en aval. Par exemple, dans les tâches de synthèse de programmes, les modèles peuvent utiliser directement des variables sans les définir.
- Figure 2(b) : La troncature nuit également à l'intégrité des informations. Par exemple, « lundi matin » dans le résumé ne peut correspondre à aucun contexte de la séquence de formation, ce qui entraîne un contenu inexact. Ce type d'informations incomplètes réduira considérablement la sensibilité du modèle aux informations contextuelles, ce qui rendra le contenu généré incohérent avec la situation réelle, ce qu'on appelle la génération infidèle.
- Figure 2(c) : La troncature gêne également l'acquisition de connaissances lors de la formation car la représentation des connaissances dans le texte repose souvent sur des phrases ou des paragraphes complets. Par exemple, le modèle ne peut pas apprendre l'emplacement de la conférence ICML car le nom et l'emplacement de la conférence sont répartis dans différentes séquences de formation.
Figure 2. Exemple de troncature de document entraînant une illusion ou une perte de connaissance.
(a) La définition de la variable (partie bleue) est tronquée et les appels d'utilisation ultérieurs aboutissent à un nom indéfini (partie rouge).
(b) Les informations contextuelles clés sont tronquées (partie bleue), ce qui rend le résumé moins précis que le texte original (partie rouge).
(c) En raison de la troncature, le modèle ne sait pas où se tiendra l'ICML 2024.
En réponse à ce problème, les chercheurs ont proposé le Best-fit Packing. Cette méthode utilise des techniques d'optimisation combinatoire tenant compte de la longueur pour regrouper efficacement les documents dans des séquences de formation, éliminant complètement les troncatures inutiles. Cela maintient non seulement l'efficacité de la formation des méthodes traditionnelles, mais améliore également considérablement la qualité de la formation des modèles en réduisant la fragmentation des données. L'auteur divise d'abord chaque texte en une ou plusieurs séquences qui correspondent au plus à la longueur du contexte modèle L. La limitation de cette étape vient du modèle, elle doit donc être réalisée. Maintenant, sur la base d'un grand nombre de blocs de fichiers d'une longueur maximale de L, les chercheurs espèrent les combiner raisonnablement et obtenir le moins de séquences d'entraînement possible. Ce problème peut être considéré comme un problème de Bin Packing. Le problème d’optimisation de l’assemblage est NP-difficile. Comme le montre l'algorithme ci-dessous, ils adoptent ici la stratégie heuristique de Best-Fit-Decreasing (BFD). Ensuite, nous discuterons de la faisabilité de BFD du point de vue de la complexité temporelle (Time Complexity) et de la compacité (Compactness).
La complexité temporelle du tri et de l'emballage des BFD est O (N log N), où N est le nombre de blocs de documents. Dans le traitement des données de pré-entraînement, étant donné que la longueur du bloc de document est un nombre entier et limité ([1, L]), le tri par nombre peut être utilisé pour réduire la complexité temporelle du tri à O(N). Dans la phase d'emballage, en utilisant la structure de données de l'arbre de segments, chaque opération de recherche du conteneur le mieux adapté ne prend qu'un temps logarithmique, c'est-à-dire O (log L). Et parce que L
La compacité est un autre indicateur important pour mesurer l'effet de l'algorithme de packaging sans détruire l'intégrité du document original, il est nécessaire de réduire au maximum le nombre de séquences d'entraînement. possible d'améliorer l'efficacité de la formation du modèle. Dans les applications pratiques, en contrôlant précisément le remplissage et la disposition des séquences, l'emballage le mieux adapté peut générer un nombre presque équivalent de séquences d'entraînement que les méthodes traditionnelles, tout en réduisant considérablement la perte de données due à la troncature.
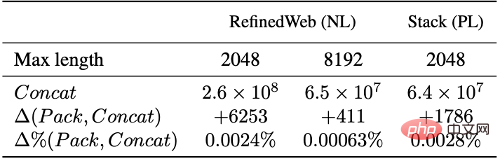
Sur la base d'expériences sur des ensembles de données en langage naturel (RefinedWeb) et en langage de programmation (The Stack), nous avons constaté que l'emballage le mieux adapté réduit considérablement la troncature du texte. Il convient de noter que la plupart des documents contiennent moins de 2048 jetons ; la troncature due à l'épissage et au découpage traditionnels se produit principalement dans cette plage, tandis qu'un emballage optimal ne tronquera aucun document dont la longueur est inférieure à L, conservant ainsi efficacement l'intégrité de la plupart des documents.
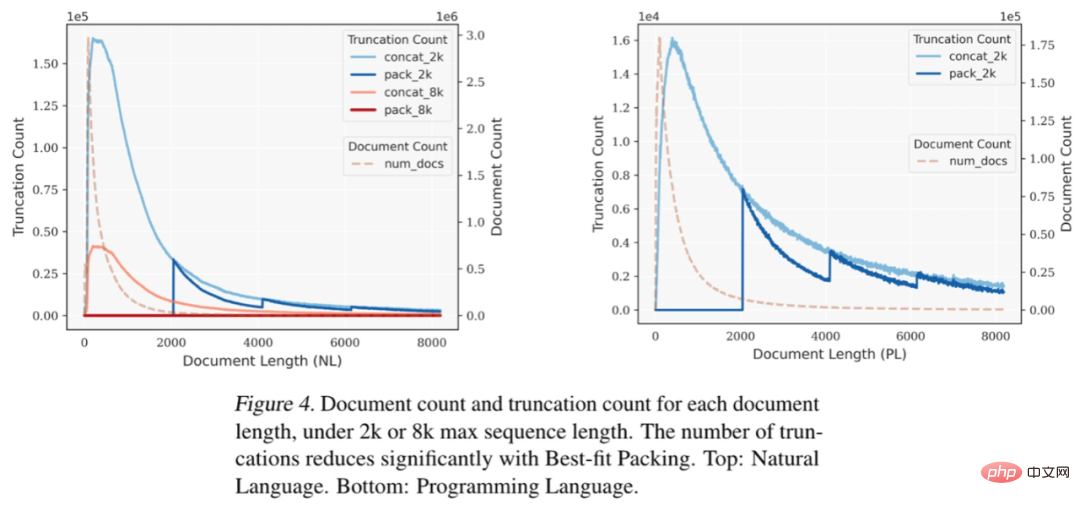
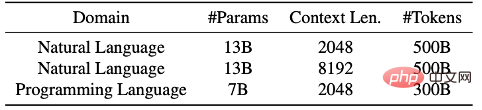
Figure 4 : Lorsque la longueur maximale de séquence est fixée à 2k ou 8k, sous différentes longueurs de document, le nombre de documents et le nombre de troncature correspondant à chaque longueur de document. Après avoir utilisé la technologie « Best-fit Packing », le nombre de troncatures est considérablement réduit. Ci-dessus : langage naturel. Ci-dessous : Langages de programmation. Les chercheurs ont rapporté en détail la comparaison des performances de modèles de langage formés à l'aide du packaging le mieux adapté et des méthodes traditionnelles (c'est-à-dire les méthodes d'épissage) sur différentes tâches, notamment : tâches de traitement du langage naturel et de langage de programmation, telles que la compréhension écrite (Reading Comprehension), l'inférence du langage naturel (Natural Language Inference), le suivi du contexte (Context Follow), le résumé de texte (Summarization), la connaissance du monde (Commonsense et Closed-book QA) et Synthèse du programme, un total de 22 sous-tâches. Les expériences impliquaient des tailles de modèles allant de 7 milliards à 13 milliards de paramètres, des longueurs de séquence de 2 000 à 8 000 jetons et des ensembles de données couvrant les langages naturels et les langages de programmation. Ces modèles sont formés sur des ensembles de données à grande échelle tels que Falcon RefinedWeb et The Stack, et les expériences sont menées à l'aide de l'architecture LLaMA.
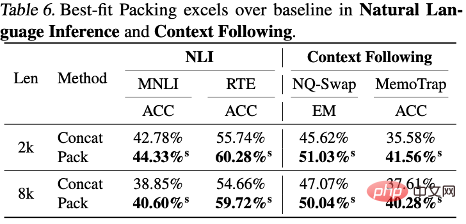
Les résultats expérimentaux montrent que l'utilisation d'un packaging d'adaptation optimal améliore les performances du modèle dans une série de tâches, notamment en compréhension écrite (+4,7%), en raisonnement en langage naturel (+9,3%) et en suivi de contexte (+ 16,8%) et synthèse du programme (+15,0 %) et autres tâches (en raison des différentes échelles de métriques pour différentes tâches, l'auteur utilise par défaut l'amélioration relative pour décrire les résultats.) Après des tests statistiques, les chercheurs ont trouvé que tous les résultats sont soit statistiquement significativement meilleur que la ligne de base (marqué par s) ou à égalité avec la ligne de base (marqué par n), et aucune dégradation significative des performances n'est observée en utilisant l'emballage le mieux adapté dans toutes les tâches évaluées. Cette amélioration de la cohérence et de la monotonie met en évidence qu'un emballage d'adaptation optimal peut non seulement améliorer les performances globales du modèle, mais également assurer la stabilité dans différentes tâches et conditions. Veuillez vous référer au texte pour les résultats détaillés et les discussions.
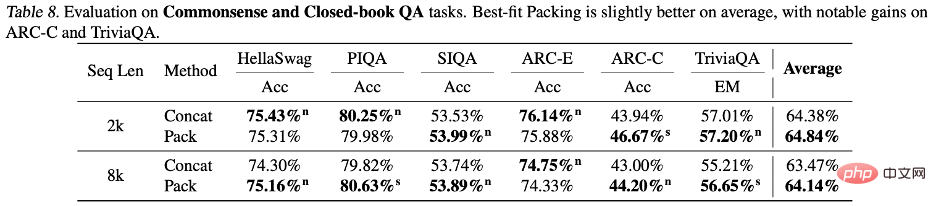
Les auteurs se sont concentrés sur l'étude de l'impact des emballages les plus adaptés sur les hallucinations. Dans la génération de résumés, à l'aide de la métrique QAFactEval, il a été constaté que les modèles avec l'emballage le mieux adapté avaient considérablement moins de génération d'hallucinations. Plus important encore, dans la tâche de synthèse du programme, les erreurs de « Nom non défini » ont été réduites jusqu'à 58,3 % lors de la génération de code à l'aide du modèle formé le mieux adapté, ce qui montre que le modèle a une compréhension plus complète de la structure du programme. et la logique, réduisant ainsi efficacement les hallucinations. Les auteurs ont également révélé des différences dans les performances du modèle lorsqu’il s’agit de différents types de connaissances. Comme mentionné précédemment, la troncature lors de la formation peut affecter l'intégrité de l'information, entravant ainsi l'acquisition des connaissances. Mais les questions de la plupart des ensembles d’évaluations standards se concentrent sur les connaissances communes, qui apparaissent fréquemment dans le langage humain. Ainsi, même si certaines connaissances sont perdues à cause de la troncature, le modèle a toujours de bonnes chances d'apprendre ces informations à partir des fragments du document. connaissances de queue rares sont plus susceptibles d'être tronquées, car la fréquence de ce type d'informations apparaissant dans les données d'entraînement elles-mêmes est faible et il est difficile pour le modèle de compléter la perte provenant d'autres sources. . connaissance.
En analysant les résultats des deux ensembles de tests ARC-C et ARC-E, les chercheurs ont découvert que par rapport à ARC-E, qui contient plus de connaissances communes, l'utilisation d'un packaging d'adaptation optimal permettra au modèle de mieux contenir Il y a des améliorations de performances plus significatives dans ARC-C avec plus de connaissances sur la queue.
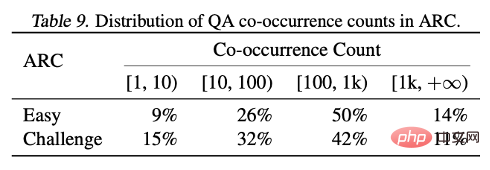
Ce résultat est en outre vérifié en comptant le nombre de cooccurrences de chaque paire question-réponse dans la carte d'entité Wikipédia prétraitée par Kandpal et al. Les résultats statistiques montrent que l'ensemble de défis (ARC-C) contient des paires co-occurrentes plus rares, ce qui vérifie l'hypothèse selon laquelle un packaging d'adaptation optimal peut soutenir efficacement l'apprentissage des connaissances de queue, et explique également pourquoi les grands modèles de langage traditionnels sont incapables d'apprendre à longue traîne. Les connaissances permettent d'expliquer les difficultés rencontrées.
Résumé
Cet article soulève le problème courant de troncature de documents dans la formation de grands modèles de langage.
Cet effet de troncature affecte la capacité du modèle à apprendre la cohérence logique et la cohérence factuelle, et augmente le phénomène d'hallucination pendant le processus de génération. Les auteurs ont proposé le Best-fit Packing, qui maximise l'intégrité de chaque document en optimisant le processus de tri des données. Cette méthode est non seulement adaptée au traitement d’ensembles de données à grande échelle contenant des milliards de documents, mais elle est également comparable aux méthodes traditionnelles en termes de compacité des données.
Les résultats expérimentaux montrent que cette méthode est extrêmement efficace pour réduire les troncatures inutiles, peut améliorer considérablement les performances du modèle dans diverses tâches de texte et de code et réduit efficacement l'illusion de génération de langage dans des domaines fermés. Bien que les expériences présentées dans cet article se concentrent principalement sur la phase de pré-formation, le conditionnement optimal de l'adaptation peut également être largement utilisé à d'autres étapes telles que le réglage fin. Ce travail contribue au développement de modèles de langage plus efficaces et plus fiables et fait progresser le développement de la technologie de formation des modèles de langage.
Pour plus de détails sur la recherche, veuillez consulter l'article original. Si vous êtes intéressé par un emploi ou un stage, vous pouvez contacter l'auteur de cet article par email zijwan@amazon.com.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn