
Maison >Périphériques technologiques >IA >Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe
Plus qu'une simple gaussienne 3D ! Dernier aperçu des techniques de reconstruction 3D de pointe

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-02 18:57:351097parcourir
Écrit auparavant et compréhension personnelle de l'auteur
La reconstruction 3D basée sur l'image est une tâche difficile qui consiste à déduire la forme 3D d'un objet ou d'une scène à partir d'un ensemble d'images d'entrée. Les méthodes basées sur l’apprentissage ont attiré l’attention pour leur capacité à estimer directement des formes 3D. Cet article de synthèse se concentre sur les techniques de reconstruction 3D de pointe, notamment la génération de nouvelles vues inédites. Un aperçu des développements récents dans les méthodes d'éclaboussure gaussienne est fourni, y compris les types d'entrée, les structures de modèle, les représentations de sortie et les stratégies de formation. Les défis non résolus et les orientations futures sont également discutés. Compte tenu des progrès rapides dans ce domaine et des nombreuses opportunités d’améliorer les méthodes de reconstruction 3D, un examen approfondi de l’algorithme semble crucial. Par conséquent, cette étude fournit un aperçu complet des progrès récents en matière de diffusion gaussienne.
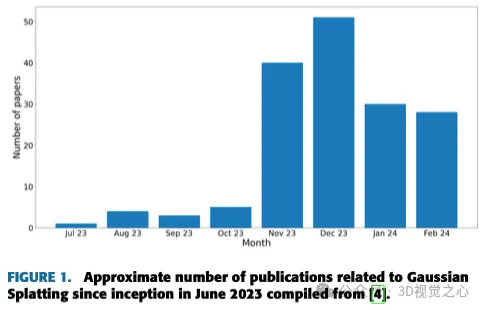
(Faites glisser votre pouce vers le haut, cliquez sur la carte en haut pour me suivre, L'opération entière ne vous prendra que 1,328 secondes, et vous emporterez ensuite tous les trucs gratuits à l'avenir , au cas où il y aurait du contenu correct, êtes-vous utile ~)
Introduction à la reconstruction 3D et à la synthèse de nouvelles vues
La reconstruction 3D et NVS sont deux domaines étroitement liés en infographie qui visent à capturer et à rendre réaliste Représentations 3D de scènes physiques. La reconstruction 3D consiste à extraire des informations géométriques et d'apparence à partir d'une série d'images 2D, généralement capturées sous différents points de vue. Bien qu’il existe de nombreuses techniques de numérisation 3D, cette capture de différentes images 2D constitue un moyen très simple et peu coûteux en termes de calcul de collecter des informations sur un environnement 3D. Ces informations peuvent ensuite être utilisées pour créer un modèle 3D de la scène, qui peut être utilisé à diverses fins, telles que des applications de réalité virtuelle (VR), des superpositions de réalité augmentée (RA) ou une modélisation de conception assistée par ordinateur (CAO). .
NVS, quant à lui, se concentre sur la génération d'une nouvelle vue 2D de la scène à partir d'un modèle 3D précédemment acquis. Cela permet la création d'images photoréalistes d'une scène depuis n'importe quel point de vue souhaité, même si l'image originale n'a pas été prise sous cet angle. Les progrès récents en matière d’apprentissage profond ont conduit à des améliorations significatives en matière de reconstruction 3D et de NVS. Les modèles d'apprentissage profond peuvent être utilisés pour extraire efficacement la géométrie et l'apparence 3D des images, et ces modèles peuvent également être utilisés pour générer de nouvelles vues réalistes à partir de modèles 3D. En conséquence, ces technologies deviennent de plus en plus populaires dans diverses applications et devraient jouer un rôle encore plus important à l’avenir.
Cette section présentera comment stocker ou représenter des données 3D, puis présentera les ensembles de données publics les plus couramment utilisés pour cette tâche, puis développera divers algorithmes, en se concentrant principalement sur le splash gaussien.
Représentation des données 3D
La nature spatiale complexe des données tridimensionnelles, y compris les dimensions volumétriques, fournit une représentation détaillée des cibles et des environnements. Ceci est essentiel pour créer des simulations immersives et des modèles précis dans divers domaines de recherche. La structure multidimensionnelle des données tridimensionnelles permet de combiner la profondeur, la largeur et la hauteur, conduisant à des avancées significatives dans des disciplines telles que la conception architecturale et la technologie d'imagerie médicale.
Le choix de la représentation des données joue un rôle crucial dans la conception de nombreux systèmes de deep learning 3D. Les nuages de points n'ont pas de structure de type grille et ne peuvent généralement pas être directement convolués. D’un autre côté, les représentations de voxels caractérisées par des structures de type grille nécessitent souvent des besoins en mémoire de calcul élevés.
L'évolution de la représentation 3D s'accompagne de la manière dont les données ou les modèles 3D sont stockés. Les représentations de données 3D les plus couramment utilisées peuvent être divisées en méthodes traditionnelles et nouvelles.
Approches traditionnelles :
- Nuage de points
- Mesh
- Voxel

Approches nouvelles :
- Réseau neuronal/perceptron multicouche (MLP)
- Splats gaussiens
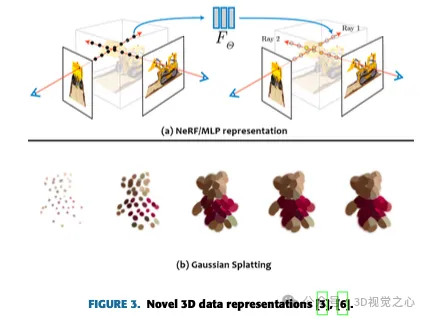
ensemble de données
Reconstruction tridimensionnelle avec la technologie NVS
Pour évaluer les progrès actuels dans ce domaine, une étude de la littérature a été menée pour identifier et examiner attentivement les travaux universitaires pertinents. L'analyse se concentre en particulier sur deux domaines clés : la reconstruction 3D et le NVS. Le développement de la reconstruction volumétrique 3D à partir de plusieurs images de caméras s’étend sur des décennies, avec diverses applications en infographie, en robotique et en imagerie médicale. La section suivante explore l'état actuel de cette technologie.
Photogrammétrie : Depuis les années 1980, des technologies avancées de photogrammétrie et de vision stéréo ont émergé pour identifier automatiquement les points correspondants dans des paires d'images stéréo. La photogrammétrie est une méthode qui combine la photographie et la vision par ordinateur pour générer des modèles 3D d'objets ou de scènes. Cela nécessite de capturer des images sous différents angles, en utilisant un logiciel tel qu'Agisoft Metashape pour estimer la position de la caméra et générer des nuages de points. Ce nuage de points est ensuite converti en un maillage 3D texturé, permettant la création de visualisations détaillées et photoréalistes d'objets ou de scènes reconstruits.
Structure à partir du mouvement : dans les années 1990, la technologie SFM a pris de l'importance, capable de reconstruire la structure 3D et le mouvement de la caméra à partir de séquences d'images 2D. SFM est le processus d'estimation de la structure 3D d'une scène à partir d'un ensemble d'images 2D. SFM nécessite des corrélations ponctuelles entre les images. Trouvez les points correspondants en faisant correspondre les caractéristiques ou en suivant les points dans plusieurs images et triangulez pour trouver des emplacements 3D.
Deep Learning : Ces dernières années, la technologie d'apprentissage profond, en particulier les réseaux de neurones convolutifs (CNN), a été intégrée. Les méthodes basées sur l’apprentissage profond s’accélèrent dans la reconstruction 3D. Le plus remarquable est le 3D Occupancy Network, une architecture de réseau neuronal conçue pour la compréhension et la reconstruction de scènes 3D. Il fonctionne en divisant l'espace 3D en petites unités volumétriques, ou voxels, chaque voxel indiquant s'il contient une cible ou s'il s'agit d'un espace vide. Ces réseaux utilisent des techniques d'apprentissage profond, telles que les réseaux neuronaux convolutifs 3D, pour prédire l'occupation des voxels, ce qui les rend utiles pour des applications telles que la robotique, les véhicules autonomes, la réalité augmentée et la reconstruction de scènes 3D. Ces réseaux s'appuient fortement sur des convolutions et des transformateurs. Ils sont essentiels pour des tâches telles que l’évitement des collisions, la planification de trajectoires et l’interaction en temps réel avec le monde physique. De plus, les réseaux d'occupation 3D peuvent estimer l'incertitude mais peuvent présenter des limites de calcul lorsqu'il s'agit de scènes dynamiques ou complexes. Les progrès dans l’architecture des réseaux neuronaux continuent d’améliorer leur précision et leur efficacité.
Neural Radiation Field : Lancé en 2020, NeRF combine les réseaux de neurones avec les principes classiques de reconstruction tridimensionnelle et a attiré une attention considérable dans le domaine de la vision par ordinateur et du graphisme. Il reconstruit des scènes 3D détaillées en modélisant les fonctions de volume et en prédisant la couleur et la densité via des réseaux neuronaux. Les NeRF sont largement utilisés en infographie et en réalité virtuelle. Récemment, NeRF a amélioré la précision et l’efficacité grâce à des recherches approfondies. Des recherches récentes ont également exploré l’applicabilité du NeRF dans des scénarios sous-marins. Tout en fournissant une représentation robuste de la géométrie de la scène 3D, des défis tels que les exigences informatiques subsistent. Les futures recherches NeRF doivent se concentrer sur l’interprétabilité, le rendu en temps réel, les nouvelles applications et l’évolutivité, ouvrant ainsi la voie à la réalité virtuelle, aux jeux et à la robotique.
Diffusion gaussienne : Enfin, en 2023, la diffusion gaussienne 3D apparaît comme une nouvelle technologie de rendu 3D en temps réel. Dans la section suivante, cette approche est discutée en détail.
Les bases du GAUSSIAN SPLATTING
Gaussian Splash utilise de nombreuses gaussiennes ou particules 3D pour représenter une scène 3D, chacune équipée d'informations de position, d'orientation, d'échelle, d'opacité et de couleur. Pour restituer ces particules, convertissez-les en espace 2D et organisez-les de manière stratégique pour un rendu optimal.
La figure 4 montre l'architecture de l'algorithme de splash gaussien. Dans l'algorithme original, les étapes suivantes sont suivies :
- Structure à partir du mouvement
- Conversion en splats gaussiens
- Formation
- Rastérisation gaussienne différenciable
ÉTAT DE L'ART
Dans les deux prochaines sections, ce sera exploré diverses applications et avancées de Gaussian Splash, approfondissant son utilisation dans la conduite autonome, les avatars, la compression, la diffusion, la dynamique et la déformation, l'édition, la génération basée sur du texte, l'extraction de maillage et la physique, la régularisation et l'optimisation, le rendu, la représentation clairsemée et différents implémentations dans des domaines tels que la localisation et la cartographie simultanées (SLAM). Chaque sous-catégorie sera examinée pour donner un aperçu de la polyvalence des méthodes d'éclaboussement gaussiennes pour relever des défis spécifiques et réaliser des progrès significatifs dans ces divers domaines. La figure 5 montre la liste complète de toutes les méthodes.
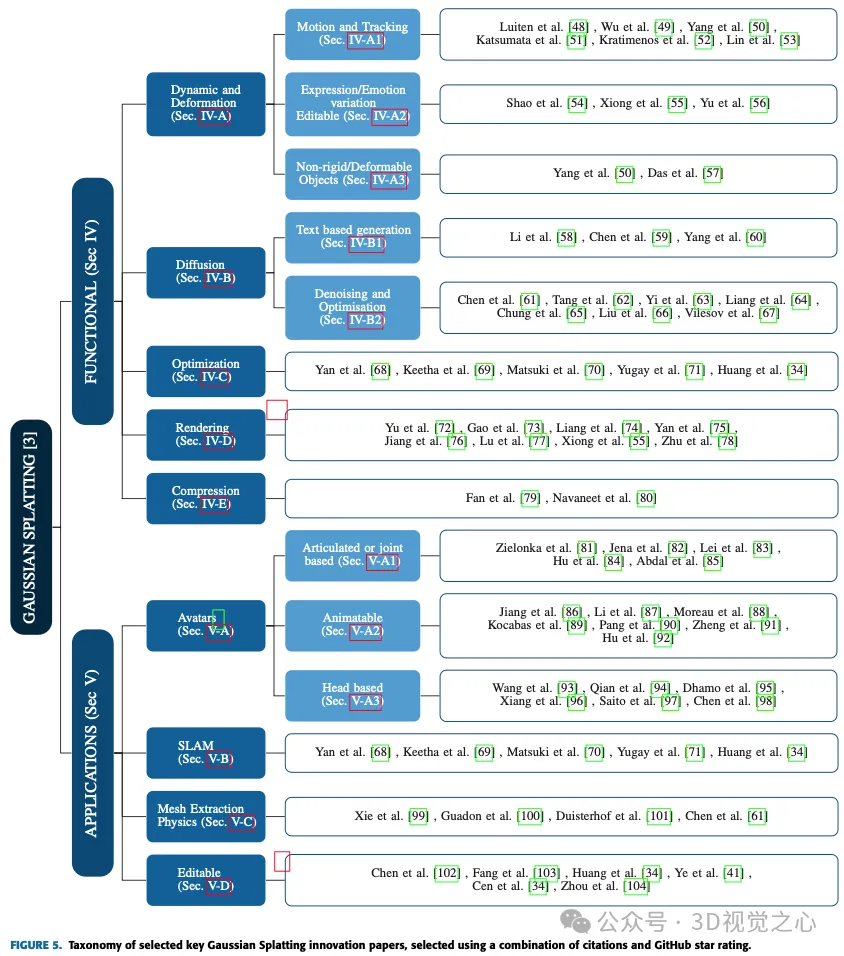
AVANCÉES FONCTIONNELLES
Cette section examine les progrès réalisés dans les capacités fonctionnelles depuis la première introduction de l'algorithme de splash gaussien.
Dynamique et déformations
Par rapport au splash gaussien général, où tous les paramètres de la matrice de covariance 3D dépendent uniquement de l'image d'entrée, dans ce cas, afin de capturer la dynamique du splash au fil du temps, certains paramètres dépendent à l'heure ou au pas de temps. Par exemple, la position dépend du pas de temps ou de la trame. Cette position peut être mise à jour par la trame suivante de manière cohérente dans le temps. Il est également possible d'apprendre certains codages sous-jacents qui peuvent être utilisés pour éditer ou propager des Gaussiennes à chaque pas de temps pendant le rendu afin d'obtenir certains effets tels que des changements d'expression dans les avatars et l'application de forces sur des corps non rigides. La figure 6 montre quelques méthodes basées sur la dynamique et la déformation.
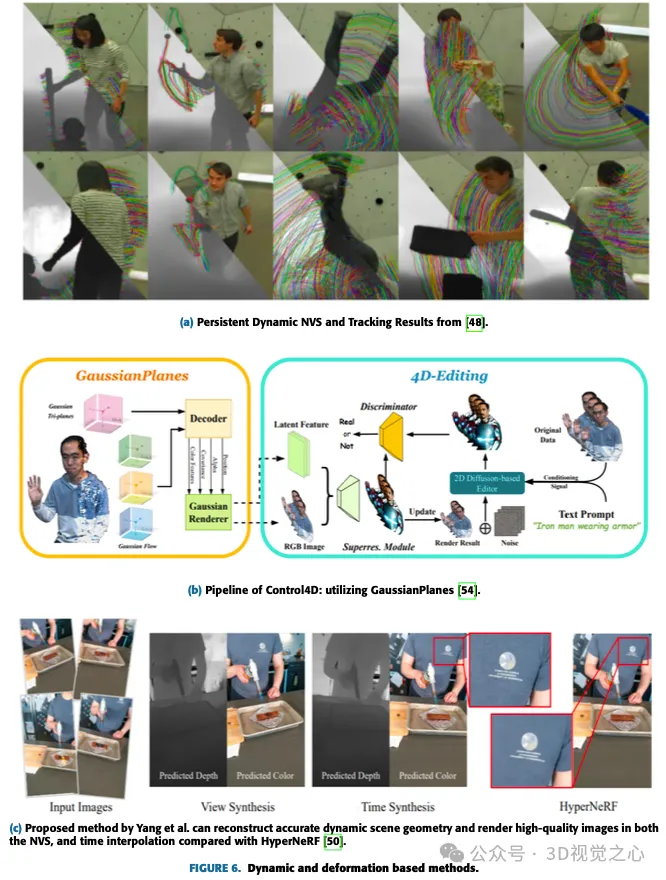
Les modèles dynamiques et déformables peuvent être facilement représentés par de légères modifications à la représentation originale du splash gaussien :

Mouvement et suivi
La plupart du travail lié au splash gaussien dynamique étendu au gaussien 3D suivi de mouvement sur plusieurs pas de temps, plutôt qu'un splash séparé pour chaque pas de temps. Katsumata et al. ont proposé l'approximation de Fourier de la position et l'approximation linéaire du quaternion de rotation.
L'article de Luiten et al. présente une méthode pour capturer les 6 degrés de liberté complets de tous les points 3D dans des scènes dynamiques. En incorporant des contraintes de rigidité locales, la gaussienne 3D dynamique représente une rotation spatiale cohérente, permettant un suivi et une reconstruction denses à 6 degrés de liberté sans avoir besoin de correspondance ou d'entrée en streaming. Cette méthode surpasse le PIP en matière de suivi 2D, atteignant une erreur de trajectoire médiane 10 fois inférieure, une précision de trajectoire plus élevée et un taux de survie de 100 %. Cette représentation polyvalente facilite des applications telles que le montage vidéo 4D, la synthèse de vues à la première personne et la génération de scènes dynamiques.
Lin et al. introduisent un nouveau modèle de déformation à double domaine (DDDM), explicitement conçu pour modéliser la déformation des attributs de chaque point de Gauss. Le modèle utilise un ajustement de série de Fourier dans le domaine fréquentiel et un ajustement polynomial dans le domaine temporel pour capturer les résidus dépendant du temps. DDDM excelle dans la gestion des déformations dans les scènes vidéo complexes sans avoir besoin de former un modèle 3D Gaussian Splash (3D-GS) distinct pour chaque image. Notamment, la modélisation explicite de la déformation par points gaussiens discrets garantit un entraînement rapide et un rendu de scène 4D, similaire au 3D-GS original pour la reconstruction 3D statique. Cette approche présente des améliorations significatives en termes d'efficacité, avec une formation presque 5 fois plus rapide par rapport à la modélisation 3D-GS. Cependant, il existe des possibilités d'amélioration pour conserver des structures fines haute fidélité dans le rendu final.
Variation d'expression ou d'émotion et modifiable dans les avatars
Shao et al. ont introduit GaussianPlanes, une représentation 4D obtenue par décomposition plane dans l'espace et le temps tridimensionnels, améliorant l'efficacité de l'édition 4D. De plus, Control4D utilise un générateur 4D pour optimiser l'espace de création continue de photos incohérentes, ce qui entraîne une meilleure cohérence et qualité. La méthode proposée utilise GaussianPlanes pour former des représentations implicites de scènes de portrait 4D, qui sont ensuite restituées en caractéristiques latentes et en images RVB à l'aide du rendu gaussien. Un générateur basé sur un réseau contradictoire génératif (GAN) et un éditeur basé sur la diffusion 2D affinent l'ensemble de données et génèrent des images réelles et fausses pour la différenciation. Les résultats discriminants contribuent à la mise à jour itérative du générateur et du discriminateur. Cependant, cette approche se heurte à des difficultés dans la gestion de mouvements non rigides rapides et étendus en raison de sa dépendance à l'égard de nuages de points gaussiens canoniques avec des représentations de flux. Cette méthode est soumise à ControlNet, limitant l'édition à un niveau grossier et empêchant l'édition précise d'expressions ou d'actions. De plus, le processus d’édition nécessite une optimisation itérative, sans solution en une seule étape.
Objets non rigides ou déformables
La représentation neuronale implicite apporte des changements significatifs dans la reconstruction et le rendu dynamiques des scènes. Cependant, les méthodes contemporaines de rendu neuronal dynamique rencontrent des difficultés pour capturer des détails complexes et réaliser un rendu en temps réel de scènes dynamiques.
Pour relever ces défis, Yang et al. ont proposé des Gaussiennes 3D déformables pour la reconstruction de scènes dynamiques monoculaires haute fidélité. Une nouvelle méthode 3D-GS déformable est proposée. La méthode utilise des Gaussiennes 3D apprises dans un espace canonique avec un champ de déformation spécifiquement conçu pour les scènes dynamiques monoculaires. Cette méthode introduit un mécanisme d'entraînement en douceur (AST) adapté aux scènes dynamiques monoculaires du monde réel, résolvant efficacement l'impact des poses incorrectes sur la tâche d'interpolation temporelle sans introduire de surcharge d'entraînement supplémentaire. En utilisant un rastériseur gaussien différentiel, le gaussien 3D déformable améliore non seulement la qualité du rendu, mais atteint également une vitesse en temps réel, surpassant les méthodes existantes dans les deux aspects. Cette méthode s'est avérée bien adaptée aux tâches telles que NVS et offre une polyvalence pour les tâches de post-production en raison de sa nature basée sur des points. Les résultats expérimentaux mettent en évidence les effets de rendu supérieurs et les performances en temps réel de cette méthode, confirmant son efficacité dans la modélisation dynamique de scènes.
DIFFUSION
La diffusion et le Splash gaussien sont une technique puissante pour générer des objets 3D à partir de descriptions/indices de texte. Il combine les avantages de deux méthodes différentes : les modèles de diffusion et la diffusion gaussienne. Les modèles de diffusion sont des réseaux de neurones qui apprennent à générer des images à partir d'entrées bruyantes. En alimentant le modèle avec une série d'images de plus en plus propres, le modèle apprend à inverser le processus de corruption des images, générant finalement des images propres à partir d'entrées complètement aléatoires. Cela peut être utilisé pour générer des images à partir de descriptions textuelles, car le modèle peut apprendre à associer des mots aux caractéristiques visuelles correspondantes. Le pipeline texte-3D avec diffusion et splash gaussien fonctionne en générant d'abord un nuage de points 3D initial à partir d'une description textuelle à l'aide d'un modèle de diffusion. La diffusion gaussienne est ensuite utilisée pour convertir le nuage de points en un ensemble de sphères gaussiennes. Enfin, la sphère gaussienne est rendue pour générer une image 3D de la cible.
Génération basée sur du texte
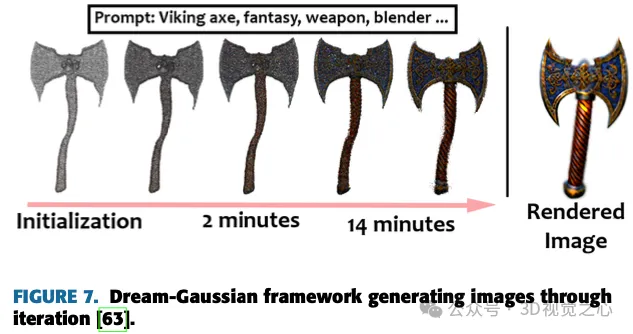
Le travail de Yi et al. introduit Gaussian Dreamer, une méthode texte-3D qui connecte de manière transparente les modèles de diffusion 3D et 2D via la division gaussienne, garantissant la cohérence 3D et la génération de détails complexes. La figure 7 montre le modèle proposé pour générer des images. Pour enrichir davantage le contenu, la croissance des points de bruit et la perturbation des couleurs sont introduites pour compléter la gaussienne 3D initialisée. Cette méthode se caractérise par sa simplicité et son efficacité, générant des instances 3D en 15 minutes sur un seul GPU, ce qui est supérieur en vitesse par rapport aux méthodes précédentes. Les instances tridimensionnelles générées peuvent être directement restituées en temps réel, soulignant le caractère pratique de cette méthode. Le cadre global comprend l'initialisation à l'aide d'un modèle de diffusion 3D préalable et l'optimisation à l'aide d'un modèle de diffusion 2D, permettant la création d'actifs 3D diversifiés et de haute qualité à partir d'indices textuels en tirant parti des avantages des deux modèles de diffusion.
Chen et al. ont proposé la génération de texte en 3D basée sur la diffusion gaussienne (GSGEN), qui est une méthode de génération de texte en 3D qui utilise des gaussiennes 3D comme représentations. En tirant parti des a priori géométriques, nous mettons en évidence les avantages uniques de la diffusion gaussienne dans la génération de texte en 3D. La stratégie d'optimisation en deux étapes combine le guidage conjoint de la diffusion 2D et 3D pour former une structure brute cohérente dans l'optimisation géométrique, qui est ensuite densifiée dans un raffinement d'apparence basé sur la compacité. Le cadre GaussianDiffusion de Li et al. représente une nouvelle approche texte en 3D, tirant parti des modèles d'éclaboussure gaussienne et de diffusion dynamique Langevin pour accélérer le rendu et atteindre un réalisme inégalé. L'introduction du bruit structuré résout le défi de la géométrie multi-vue, tandis que le modèle de diffusion gaussienne variationnelle atténue les problèmes de convergence et les artefacts. Bien que les résultats actuels montrent un réalisme amélioré, les recherches en cours visent à affiner le flou et la brume introduits par les Gaussiennes variationnelles pour une amélioration ultérieure.
Yang et al. procèdent à un examen approfondi des priors de diffusion existants et proposent un cadre unifié pour améliorer ces priors en optimisant les scores de débruitage. La polyvalence de l'approche s'étend à une variété de cas d'utilisation, offrant systématiquement des améliorations substantielles des performances. Dans les évaluations expérimentales, notre approche atteint des performances sans précédent, surpassant les méthodes contemporaines. Malgré son succès dans l'affinement des textures générées en 3D, il reste encore des progrès à faire pour améliorer la géométrie des modèles 3D générés. OPTIMISATION ET VITESSE
Cette sous-section abordera les techniques développées par les chercheurs pour des vitesses de formation et/ou d'inférence plus rapides. Dans l'étude de Chung et al., une méthode est introduite pour optimiser la diffusion gaussienne pour la représentation de scènes 3D en utilisant un nombre limité d'images tout en atténuant le problème de surajustement. La méthode traditionnelle de représentation de scènes 3D avec des points de dispersion gaussiens peut conduire à un surajustement, notamment lorsque les images disponibles sont limitées. Cette technique utilise des cartes de profondeur provenant d'un modèle d'estimation de profondeur monoculaire pré-entraîné comme guides géométriques et les aligne avec des points caractéristiques clairsemés d'un pipeline SFM. Ceux-ci permettent d’optimiser la diffusion gaussienne 3D, de réduire les artefacts flottants et d’assurer la cohérence géométrique. La stratégie d'optimisation guidée en profondeur proposée est testée sur l'ensemble de données LLFF, montrant une géométrie améliorée par rapport à l'utilisation d'images uniquement. La recherche comprend l'introduction d'une stratégie d'arrêt précoce et d'un terme de lissage pour les cartes de profondeur, qui contribuent toutes deux à améliorer les performances. Cependant, des limites sont également reconnues, telles que la confiance dans la précision du modèle d'estimation de profondeur monoculaire et la confiance dans les performances de COLMAP. Des travaux futurs sont recommandés pour explorer l'interdépendance des profondeurs estimées et relever les défis de l'estimation de la profondeur dans des régions difficiles, telles que les plaines ou le ciel sans texture.
Fu et al. ont présenté COLMAP Free 3D Gaussian Splatting (CF-3DGS), un nouveau cadre de bout en bout pour l'estimation simultanée de la pose de la caméra et du NVS à partir d'images de séquence, qui résout le problème du mouvement de la caméra dans les méthodes précédentes. par la longue durée de la formation Yamato. Contrairement à la représentation implicite de NeRF, CF-3DGS utilise des nuages de points explicites pour représenter la scène. La méthode traite séquentiellement les images d'entrée et étend progressivement la gaussienne 3D pour reconstruire la scène entière, démontrant ainsi des performances et une robustesse améliorées sur des scènes difficiles telles que des vidéos à 360°. Cette méthode optimise conjointement les poses de caméra et le 3D-GS de manière séquentielle, ce qui la rend particulièrement adaptée au streaming vidéo ou à l'acquisition d'images ordonnées. L'utilisation de l'éclaboussement gaussien permet des vitesses d'entraînement et d'inférence rapides, démontrant les avantages de cette approche par rapport aux méthodes précédentes. Tout en démontrant son efficacité, il est reconnu que l'optimisation séquentielle limite principalement les applications aux collections d'images ordonnées, laissant la possibilité d'explorer des extensions aux collections d'images non ordonnées dans les recherches futures.
MÉTHODES DE RENDU ET D'OMBRAGE
Yu et al. ont observé en 3D-GS que des artefacts apparaissaient dans NVS, notamment lors du changement du taux d'échantillonnage. La solution introduite consiste à incorporer un filtre de lissage 3D pour ajuster la fréquence maximale des primitives gaussiennes 3D, corrigeant ainsi les artefacts dans le rendu hors distribution. De plus, le filtre de dilatation 2D a été remplacé par un filtre MIP 2D pour résoudre les problèmes d'alias et de dilatation. L'évaluation sur des ensembles de données de référence démontre l'efficacité de Mip Splatting, notamment lors de la modification du taux d'échantillonnage. Les modifications proposées sont fondées sur des principes, simples et nécessitent des modifications minimes du code 3D-GS d'origine. Cependant, il existe des limites reconnues, telles que l'erreur introduite par l'approximation du filtre gaussien et une légère augmentation du temps système de formation. Cette étude présente Mip Splatting comme une solution compétitive, démontrant la parité des performances avec les méthodes de pointe et une généralisation supérieure dans les scénarios hors distribution, démontrant sa capacité à obtenir un rendu sans alias à n'importe quelle échelle potentielle.
Gao et al. ont proposé une nouvelle méthode de rendu de nuages de points 3D capable de décomposer les matériaux et l'éclairage à partir d'images multi-vues. Le cadre permet l'édition de scènes, le lancer de rayons et le rééclairage en temps réel de manière distincte. Chaque point de la scène est représenté par une gaussienne 3D « rééclairable », transportant des informations sur sa direction normale, les propriétés du matériau telles que la fonction de distribution de réflectance bidirectionnelle (BRDF) et la lumière entrante provenant de différentes directions. Pour une estimation précise de l'éclairage, la lumière incidente est divisée en composantes globales et locales et la visibilité basée sur l'angle de vision est prise en compte. L'optimisation de la scène utilise l'éclaboussure gaussienne 3D, tandis que le rendu différenciable basé sur la physique gère le BRDF et la décomposition de l'éclairage. Une approche innovante de traçage de rayons basée sur des points exploite les hiérarchies de volumes englobants pour permettre une visualisation efficace et des ombres réalistes lors du rendu en temps réel. Les expériences montrent que l'estimation BRDF et le rendu des vues sont meilleurs que les méthodes existantes. Cependant, des défis subsistent pour les scènes qui n'ont pas de limites claires et qui nécessitent des masques cibles lors de l'optimisation. Des travaux futurs pourraient explorer l’intégration d’indices stéréo multi-vues (MVS) pour améliorer la précision géométrique des nuages de points générés par la diffusion gaussienne 3D. Ce pipeline « Reliable 3D Gaussian » démontre des capacités de rendu en temps réel prometteuses et ouvre la porte à des graphiques révolutionnaires basés sur un maillage via une approche basée sur un nuage de points qui permet le rééclairage, l'édition et le traçage de rayons.
COMPRESSION
Fan et al. introduisent une nouvelle technique de compression des représentations gaussiennes 3D utilisées dans le rendu. Leur méthode identifie et supprime les gaussiennes redondantes en fonction de leur importance, similaire à l'élagage du réseau, garantissant ainsi un impact minimal sur la qualité visuelle. Tirant parti de l'extraction de connaissances et de l'amélioration de la pseudo-vue, LightGaussian fournit des informations dans une représentation moins complexe avec moins d'harmoniques sphériques, réduisant ainsi davantage la redondance. De plus, un schéma hybride appelé quantification VecTree optimise la représentation en quantifiant les valeurs d'attribut, obtenant ainsi des tailles plus petites sans perte significative de précision. Par rapport aux méthodes standards, LightGaussian atteint un taux de compression moyen de plus de 15 fois et augmente considérablement la vitesse de rendu de 139 FPS à 215 FPS sur des ensembles de données tels que Mip NeRF 360 et Tanks&Temples. Les étapes clés impliquées sont le calcul de la saillance globale, l'élagage des gaussiennes, l'extraction de connaissances avec des pseudo-vues et la quantification des attributs à l'aide de VecTree. Dans l'ensemble, LightGaussian fournit une solution révolutionnaire pour convertir de grandes représentations basées sur des points dans un format compact, réduisant considérablement la redondance des données et améliorant considérablement l'efficacité du rendu.
Applications et études de cas
Cette section approfondit les avancées significatives dans les applications de l'algorithme Gaussian Splash depuis sa création en juillet 2023. Ces avancées ont des utilisations spécifiques dans divers domaines tels que les avatars, le SLAM, l'extraction de maillage et les simulations physiques. Lorsqu'il est appliqué à ces cas d'utilisation spécialisés, le Gaussian Splatting démontre sa polyvalence et son efficacité dans différents scénarios d'application.
AVATARS
Avec la montée de l'engouement pour les applications AR/VR, une grande partie des recherches de Gauss Splash se concentrent sur le développement de la version numérique des humains. Capturer un sujet depuis moins de points de vue et créer un modèle 3D est une tâche difficile, et Gaussian Splash aide les chercheurs et l'industrie à atteindre cet objectif.
Angles articulaires ou articulation
Cette technique de diffusion gaussienne se concentre sur la modélisation du corps humain en fonction des angles articulaires. Certains paramètres de ce type de modèle reflètent les positions, angles et autres paramètres similaires des articulations tridimensionnelles. Décodez l’image d’entrée pour connaître les positions et les angles des articulations 3D de l’image actuelle.
Zielonka et al. ont proposé un modèle de représentation du corps humain utilisant la diffusion gaussienne et mis en œuvre un rendu en temps réel à l'aide de la technologie innovante 3D-GS. Contrairement aux avatars pilotables photoréalistes existants, Drivable 3D Gaussian Splash (D3GA) ne repose pas sur un enregistrement 3D précis pendant la formation ou sur des images d'entrée denses pendant les tests. Au lieu de cela, il utilise une vidéo multi-vues densément calibrée pour un rendu en temps réel et introduit des déformations basées sur des cages tétraédriques entraînées par des points clés et des angles dans les articulations, ce qui le rend efficace pour les applications impliquant la communication, comme le montre la figure 9.

Animatable
Ces méthodes entraînent généralement des Gaussiens dépendants de la pose pour capturer des apparences dynamiques complexes, y compris des détails plus fins dans les vêtements, ce qui donne lieu à des avatars de haute qualité. Certaines de ces méthodes prennent également en charge les capacités de rendu en temps réel.

Jiang et al. ont proposé HiFi4G, qui peut efficacement restituer de vrais humains. HiFi4G combine une représentation gaussienne 3D avec un suivi non rigide, en utilisant un mécanisme à double graphe avec priorisations de mouvement et une optimisation gaussienne 4D avec un régularisateur spatio-temporel adaptatif. HiFi4G atteint environ 25 fois le taux de compression, nécessite moins de 2 Mo d'espace de stockage par image et fonctionne bien en termes de vitesse d'optimisation, de qualité de rendu et de surcharge de stockage, comme le montre la figure 10. Il propose une représentation gaussienne 4D compacte qui fait le pont entre les éclaboussures gaussiennes et le suivi non rigide. Cependant, la dépendance à l'égard de la segmentation, la susceptibilité à une mauvaise segmentation conduisant à des artefacts et la nécessité d'une reconstruction par image et d'un suivi par grille posent toutes des limites. Les recherches futures pourraient se concentrer sur l’accélération du processus d’optimisation et la réduction de la dépendance aux commandes de GPU pour un déploiement plus large sur les visionneuses Web et les appareils mobiles.
Basé sur la tête
Les méthodes précédentes d'avatar de tête reposaient principalement sur des primitives explicites fixes (grilles, points) ou des surfaces implicites (SDF). Les modèles basés sur la diffusion gaussienne ouvriront la voie à l'essor des applications AR/VR et basées sur des filtres, permettant aux utilisateurs d'essayer différents looks de maquillage, tons, coiffures, etc.
Wang et al. ont utilisé la transformation gaussienne canonique pour représenter des scènes dynamiques. En utilisant un triplan "dynamique" explicite comme conteneur efficace pour la géométrie de tête paramétrée, bien aligné avec la géométrie sous-jacente et les facteurs du triplan, les auteurs ont obtenu des facteurs de régularisation alignés pour les gaussiennes régulières. À l'aide d'un petit MLP, les facteurs sont décodés en opacité et en coefficients harmoniques sphériques de primitives gaussiennes 3D. Quin et al. ont créé des avatars de tête ultra-réalistes avec une perspective, une pose et une expression contrôlables. Au cours du processus de reconstruction de l'avatar, l'auteur a optimisé simultanément les paramètres du modèle de déformation et les paramètres d'éclaboussures gaussiennes. L'œuvre met en valeur la capacité de l'avatar à s'animer dans une variété de scénarios difficiles. Dhamo et al. ont proposé HeadGaS, un modèle hybride qui étend la représentation explicite du 3D-GS basée sur des fonctionnalités latentes apprenables. Ces caractéristiques peuvent ensuite être mélangées de manière linéaire avec des paramètres de faible dimension du modèle de tête paramétrique pour dériver des valeurs de couleur et d'opacité dépendantes de l'expression finale. La figure 11 montre quelques exemples d'images.
SLAM
SLAM est une technologie utilisée dans les voitures autonomes pour créer simultanément une carte et déterminer la position du véhicule sur cette carte. Il permet aux véhicules de naviguer et de cartographier des environnements inconnus. Comme son nom l'indique, le SLAM visuel (vSLAM) s'appuie sur des images provenant de caméras et de divers capteurs d'images. Cette méthode fonctionne avec une variété de types de caméras, notamment les caméras simples, à œil composé et RVB-D, ce qui en fait une solution rentable. Grâce à la caméra, la détection de points de repère peut être combinée à une optimisation basée sur des graphiques pour améliorer la flexibilité de la mise en œuvre du SLAM. Le SLAM monoculaire est un sous-ensemble du vSLAM qui utilise une seule caméra et fait face à des défis de perception de la profondeur, qui peuvent être résolus en incorporant des capteurs supplémentaires, tels que l'odométrie et les encodeurs d'une unité de mesure inertielle (IMU). Les technologies clés liées au vSLAM comprennent le SFM, l'odométrie visuelle et l'ajustement du faisceau. Les algorithmes Visual SLAM sont divisés en deux catégories principales : les méthodes clairsemées, qui utilisent la correspondance de points caractéristiques (par exemple, le suivi et le mappage parallèles, ORB-SLAM), et les méthodes denses, qui utilisent la luminosité globale de l'image (par exemple, DTAM, LSD-SLAM, DSO). , SVO).
Extraction de maillage avec physique
La diffusion gaussienne peut être utilisée pour des simulations et des rendus basés sur la physique. En ajoutant davantage de paramètres au noyau gaussien 3D, la vitesse, la déformation et d'autres propriétés mécaniques peuvent être modélisées. C'est pourquoi diverses méthodes ont été développées en quelques mois, notamment la simulation de la physique par diffusion gaussienne.

Xie et al. ont introduit une méthode cinématique gaussienne tridimensionnelle basée sur la mécanique des milieux continus, utilisant des équations aux dérivées partielles (EDP) pour piloter l'évolution du noyau gaussien et de ses harmoniques sphériques associées. Cette innovation permet l'utilisation d'un pipeline de rendu de simulation unifié, simplifiant la génération de mouvement en éliminant le besoin de maillages cibles explicites. Leur approche fait preuve de polyvalence grâce à des analyses comparatives complètes et à des expériences sur une variété de matériaux, démontrant des performances en temps réel dans des scénarios à dynamique simple. Les auteurs présentent PhysGaussian, un cadre qui génère simultanément et de manière transparente des dynamiques physiques et des rendus photoréalistes. Tout en reconnaissant les limites du cadre telles que le manque d'évolution des ombres et l'utilisation de la quadrature à point unique pour l'intégration de volumes, les auteurs suggèrent des pistes pour des travaux futurs, notamment l'utilisation de la quadrature d'ordre supérieur dans la méthode du point matériel (MPM) et l'exploration l'utilisation de réseaux de neurones intégrés pour une modélisation plus réaliste. Le cadre peut être étendu pour gérer une variété de matériaux, tels que les liquides, et intégrer des contrôles utilisateur avancés utilisant des modèles de langage étendus (LLM). La figure 13 montre le processus de formation du cadre PhysGaussian.
Édition
Gaussian Splash étend également ses ailes à l'édition 3D et à la manipulation ponctuelle de scènes. L'édition 3D de scènes basée sur des astuces est même possible grâce aux dernières avancées qui seront discutées. Ces méthodes représentent non seulement la scène sous la forme d'une carte gaussienne 3D, mais ont également une compréhension sémantique et controversée de la scène.
Chen et al. ont présenté GaussianEditor, un nouvel algorithme d'édition 3D basé sur le Gaussian Splatting, qui vise à surmonter les limites des méthodes d'édition 3D traditionnelles. Alors que les méthodes traditionnelles qui s'appuient sur des maillages ou des nuages de points ont du mal à obtenir des représentations réalistes, les représentations 3D implicites comme NeRF sont confrontées aux défis d'un traitement lent et d'un contrôle limité. GaussianEditor résout ces problèmes en tirant parti du 3D-GS, en améliorant la précision et le contrôle grâce au suivi sémantique gaussien et en introduisant le Hierarchical Gaussian Splash (HGS) pour des résultats stables et raffinés sous guidage génératif. L'algorithme comprend une méthode de réparation 3D spécialisée pour une suppression et une intégration efficaces des objets, démontrant un contrôle, une efficacité et des performances rapides supérieurs dans des expériences approfondies. La figure 14 montre les différentes invites textuelles testées par Chen et al. GaussianEditor marque une avancée majeure dans l'édition 3D, offrant une efficacité, une vitesse et un contrôle améliorés. Les contributions de cette recherche incluent l'introduction du suivi sémantique gaussien pour un contrôle d'édition détaillé, la proposition de HGS pour atteindre une convergence stable sous guidage de génération, le développement d'un algorithme de réparation 3D pour la suppression et l'ajout rapides de cibles, et des expériences approfondies démontrant que cela La méthode est supérieure aux méthodes d'édition 3D précédentes. Malgré les progrès de GaussianEditor, il s'appuie sur un modèle de diffusion 2D pour une supervision efficace et présente des limites dans la gestion des signaux complexes, ce qui constitue un défi courant rencontré par d'autres méthodes d'édition 3D basées sur des modèles similaires.

Discussion
Traditionnellement, les scènes 3D sont représentées à l'aide de maillages et de points en raison de leur nature explicite et de leur compatibilité avec la rastérisation rapide basée sur GPU/CUDA. Cependant, les progrès récents, tels que les méthodes NeRF, se concentrent sur la représentation continue de scènes, en utilisant des techniques telles que l'optimisation des perceptrons multicouches et la nouvelle synthèse de vues via une marche de rayons volumétriques. Bien que la représentation continue facilite l'optimisation, l'échantillonnage aléatoire requis pour le rendu introduit un bruit coûteux. Gaussian Splash comble cette lacune en exploitant des représentations gaussiennes 3D optimisées pour obtenir une qualité visuelle de pointe et des temps d'entraînement compétitifs. De plus, une solution de démarrage basée sur des tuiles garantit un rendu en temps réel de qualité supérieure. Gaussian Splash fournit certains des meilleurs résultats en termes de qualité et d'efficacité lors du rendu de scènes 3D.
Gaussian Splash a été développé pour gérer des cibles dynamiques et déformables en modifiant leur représentation originale. Cela implique d'incorporer des paramètres tels que la position 3D, la rotation, les facteurs d'échelle et les coefficients harmoniques sphériques pour la couleur et l'opacité. Les progrès récents dans ce domaine incluent l'introduction de pertes de parcimonie pour encourager le partage de trajectoire de base, l'introduction de modèles de déformation à double domaine pour capturer les résidus dépendant du temps et la cartographie de coque gaussienne qui connecte les réseaux de générateurs au rendu gaussien 3D. Des efforts sont également déployés pour relever des défis tels que le suivi non rigide, les changements d'expression des avatars et le rendu efficace des performances humaines réalistes. Ensemble, ces avancées contribuent à un rendu en temps réel, à une efficacité optimisée et à des résultats de haute qualité lorsque vous travaillez avec des cibles dynamiques et déformables.
D'autre part, Diffusion et Gaussian Splash fonctionnent ensemble pour créer des cibles 3D à partir d'invites de texte. Un modèle de diffusion est un réseau neuronal qui apprend à générer des images à partir d'une entrée bruyante en inversant le processus de corruption des images grâce à une série d'images de plus en plus propres. Dans le pipeline texte-3D, un modèle de diffusion génère un nuage de points 3D initial basé sur la description textuelle, qui est ensuite converti en une sphère gaussienne à l'aide de la diffusion gaussienne. La sphère gaussienne rendue génère l'image cible 3D finale. Les avancées dans ce domaine incluent l'utilisation du bruit structuré pour résoudre les problèmes de géométrie multi-vues, l'introduction de modèles de diffusion gaussienne variationnelle pour résoudre les problèmes de convergence et l'optimisation des scores de débruitage pour améliorer les a priori de diffusion, dans le but d'atteindre un réalisme sans précédent dans la génération de sexe et de performances 3D basée sur du texte. .
Gaussian Splash a été largement utilisé dans la création d'avatars numériques pour les applications AR/VR. Cela implique de capturer un objet à partir d'un nombre minimum de points de vue et de construire un modèle 3D. La technologie a été utilisée pour modéliser les articulations humaines, les angles des articulations et d'autres paramètres, permettant la génération d'avatars expressifs et contrôlables. Les avancées dans ce domaine incluent le développement de méthodes permettant de capturer les détails du visage à haute fréquence, de préserver les expressions exagérées et de transformer efficacement les avatars. En outre, des modèles hybrides sont proposés qui combinent des représentations explicites avec des caractéristiques latentes apprenables pour obtenir des valeurs finales de couleur et d'opacité dépendant de l'expression. Ces avancées sont conçues pour améliorer la géométrie et la texture des modèles 3D générés afin de répondre à la demande croissante d'avatars réalistes et contrôlables dans les applications AR/VR.
Gaussian Splatting trouve également des applications polyvalentes dans SLAM, offrant des capacités de suivi et de cartographie en temps réel sur le GPU. En utilisant une représentation gaussienne 3D et un pipeline de rastérisation par éclaboussures différentiable, il permet un rendu rapide et photoréaliste de scènes réelles et synthétiques. La technique s'étend à l'extraction de maillage et à la simulation basée sur la physique, permettant de modéliser les propriétés mécaniques sans maillage cible explicite. Les progrès de la mécanique des milieux continus et des équations aux dérivées partielles ont permis l'évolution des noyaux gaussiens, simplifiant ainsi la génération de mouvement. L'optimisation implique notamment des structures de données efficaces telles qu'OpenVDB, des termes de régularisation pour l'alignement et des termes inspirés de la physique pour la réduction des erreurs, améliorant ainsi l'efficacité et la précision globales. D'autres travaux ont été réalisés sur la compression et l'amélioration de l'efficacité du rendu de la diffusion gaussienne.
Comparaison
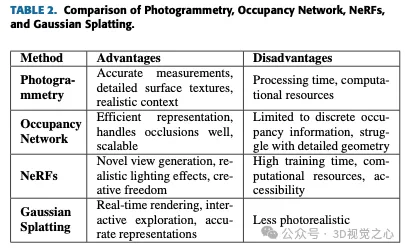
Il ressort clairement du tableau 2 qu'au moment de la rédaction, Gaussian Splash est l'option la plus proche du rendu en temps réel et de la représentation dynamique de la scène. L'occupation du réseau n'est tout simplement pas adaptée aux cas d'utilisation de NVS. La photogrammétrie est idéale pour créer des modèles très précis et réalistes avec un sens aigu du contexte. NeRF excelle dans la génération de vues inédites et d'effets d'éclairage réalistes, offrant une liberté créative et gérant des scènes complexes. Gaussian Splash brille par ses capacités de rendu en temps réel et son exploration interactive, ce qui le rend adapté aux applications dynamiques. Chaque méthode a sa niche et se complète, offrant une grande variété d’outils de reconstruction et de visualisation 3D.
Défis et limites
Bien que Gaussian Splash soit une technique très robuste, elle comporte quelques mises en garde. Certains d'entre eux sont répertoriés ci-dessous :
- 1) Complexité informatique : la diffusion gaussienne nécessite l'évaluation d'une fonction gaussienne pour chaque pixel, ce qui peut nécessiter beaucoup de calculs, en particulier lorsqu'il s'agit d'un grand nombre de points ou de particules.
- 2) Utilisation de la mémoire : le stockage des résultats intermédiaires de l'éclaboussement gaussien, tels que la contribution pondérée de chaque point aux pixels voisins, peut consommer beaucoup de mémoire.
- 3) Artefacts de bord : la diffusion gaussienne peut produire des artefacts indésirables, tels que des sonneries ou un flou, près des bords ou des zones très contrastées de l'image.
- 4) Compromis entre performances et précision : l'obtention de résultats de haute qualité peut nécessiter l'utilisation de noyaux de grande taille ou l'évaluation de plusieurs fonctions gaussiennes par pixel, ce qui affecte les performances.
- 5) Intégration avec d'autres techniques de rendu : Intégrer la diffusion gaussienne avec d'autres techniques comme le shadow mapping ou l'occlusion ambiante tout en conservant les performances et la cohérence visuelle peut s'avérer complexe.
Orientations futures
La technologie de reconstruction 3D en temps réel réalisera une variété de fonctions dans l'infographie et les domaines connexes, telles que l'exploration interactive en temps réel de scènes ou de modèles 3D et la manipulation de points de vue et de cibles grâce à un retour instantané. . Il peut également restituer des scènes dynamiques avec des cibles mobiles ou des environnements changeants en temps réel, améliorant ainsi le réalisme et l'immersion. La reconstruction 3D en temps réel peut être utilisée dans des environnements de simulation et de formation pour fournir un retour visuel réaliste pour des scènes virtuelles dans des domaines tels que l'automobile, l'aérospatiale et la médecine. Il prendra également en charge le rendu en temps réel d'expériences immersives AR et VR, où les utilisateurs pourront interagir avec des cibles ou des environnements virtuels en temps réel. Dans l'ensemble, Gaussian Splash en temps réel améliore l'efficacité, l'interactivité et le réalisme pour une variété d'applications dans les domaines de l'infographie, de la visualisation, de la simulation et des technologies immersives.
Conclusion
Dans cet article, nous avons discuté de divers aspects fonctionnels et applicatifs liés à la diffusion gaussienne pour la reconstruction 3D et la synthèse de nouvelles vues. Il couvre la modélisation dynamique et déformable, le suivi de mouvement, les cibles non rigides/déformables, les changements d'expression/émotion, la diffusion générative basée sur du texte, le débruitage, l'optimisation, les avatars, les cibles animables, la modélisation basée sur la tête, la localisation simultanée et des sujets tels que la planification, extraction et physique du maillage, techniques d'optimisation, capacités d'édition, méthodes de rendu, compression, etc.
Plus précisément, cet article se penche sur les défis et les progrès de la reconstruction 3D basée sur l'image, le rôle des méthodes basées sur l'apprentissage dans l'amélioration de l'estimation de la forme 3D et l'application de la technologie d'éclaboussure gaussienne dans la gestion des scènes dynamiques, la manipulation interactive de cibles et la segmentation 3D. et Applications potentielles et orientations futures dans le montage de scènes.
Gaussian Splash est transformateur dans divers domaines, notamment l'imagerie générée par ordinateur, la VR/AR, la robotique, le cinéma et l'animation, la conception automobile, la vente au détail, la recherche environnementale et les applications aérospatiales. Cependant, il convient de noter que la diffusion gaussienne peut avoir des limites en termes de réalisme par rapport à d’autres méthodes telles que les NeRF. De plus, les défis liés au surajustement, aux ressources de calcul et aux limitations de la qualité du rendu doivent également être pris en compte. Malgré ces limites, les recherches en cours et les progrès en matière de diffusion gaussienne continuent de relever ces défis et d'améliorer encore l'efficacité et l'applicabilité de la méthode.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!