
Maison >Périphériques technologiques >IA >La première reconstruction purement visuelle et statique de la conduite autonome
La première reconstruction purement visuelle et statique de la conduite autonome

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-02 15:24:401109parcourir
Une solution d'annotation purement visuelle utilise principalement la vision ainsi que certaines données du GPS, de l'IMU et des capteurs de vitesse de roue pour l'annotation dynamique. Bien entendu, pour les scénarios de production de masse, il n’est pas nécessaire que cela soit purement visuel. Certains véhicules produits en série seront équipés de capteurs comme le radar à semi-conducteurs (AT128). Si nous créons une boucle fermée de données dans la perspective d'une production de masse et utilisons tous ces capteurs, nous pouvons résoudre efficacement le problème de l'étiquetage des objets dynamiques. Mais notre plan ne prévoit pas de radar à semi-conducteurs. Par conséquent, nous présenterons cette solution d’étiquetage de production de masse la plus courante.
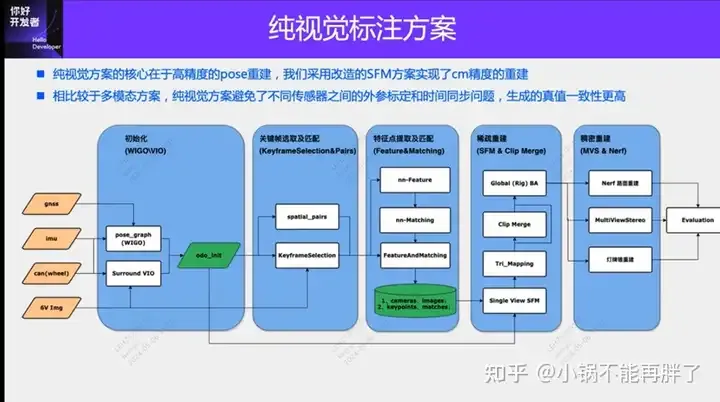
Le cœur de la solution d'annotation purement visuelle réside dans la reconstruction de pose de haute précision. Nous utilisons le schéma de reconstruction de pose Structure from Motion (SFM) pour garantir la précision de la reconstruction. Cependant, le SFM traditionnel, en particulier le SFM incrémentiel, est très lent et coûteux en termes de complexité de calcul. La complexité de calcul est O(n^4), où n est le nombre d'images. Ce type d'efficacité de reconstruction est inacceptable pour l'annotation de données de modèles à grande échelle. Nous avons apporté quelques améliorations à la solution SFM.
La reconstruction améliorée du clip est principalement divisée en trois modules : 1) Utilisez les données multi-capteurs, le GNSS, l'IMU et le compteur de vitesse de roue pour construire l'optimisation pose_graph et obtenir la pose initiale. Cet algorithme est appelé Wheel-Imu-GNSS -Odometry ( WIGO) ; 2) Extraction et mise en correspondance des caractéristiques de l'image, et triangulation directement en utilisant la pose initialisée pour obtenir les points 3D initiaux ; 3) Enfin, un BA (Bundle Adjustment) global est effectué ; D'une part, notre solution évite le SFM incrémental, et d'autre part, des opérations parallèles peuvent être réalisées entre différents clips, améliorant ainsi considérablement l'efficacité de la reconstruction de pose. Par rapport à la reconstruction incrémentale existante, elle peut être réalisée de 10 à 20. fois l'amélioration de l'efficacité.
Au cours du processus de reconstruction unique, notre solution a également apporté quelques optimisations. Par exemple, nous avons utilisé des fonctionnalités basées sur l'apprentissage (Superpoint et Superglue), l'une est le point caractéristique et l'autre est la méthode de correspondance , pour remplacer les points clés SIFT traditionnels. L'avantage de l'apprentissage de NN-Features est que d'une part, les règles peuvent être conçues de manière basée sur les données pour répondre à certains besoins personnalisés et améliorer la robustesse dans certaines textures faibles et situations d'éclairage sombre, d'autre part, cela peut s'améliorer ; Efficacité de la détection et de la correspondance des points clés. Nous avons réalisé quelques expériences comparatives et constaté que le taux de réussite des fonctionnalités NN dans les scènes de nuit sera environ 4 fois supérieur à celui de SFIT, de 20 % à 80 %.
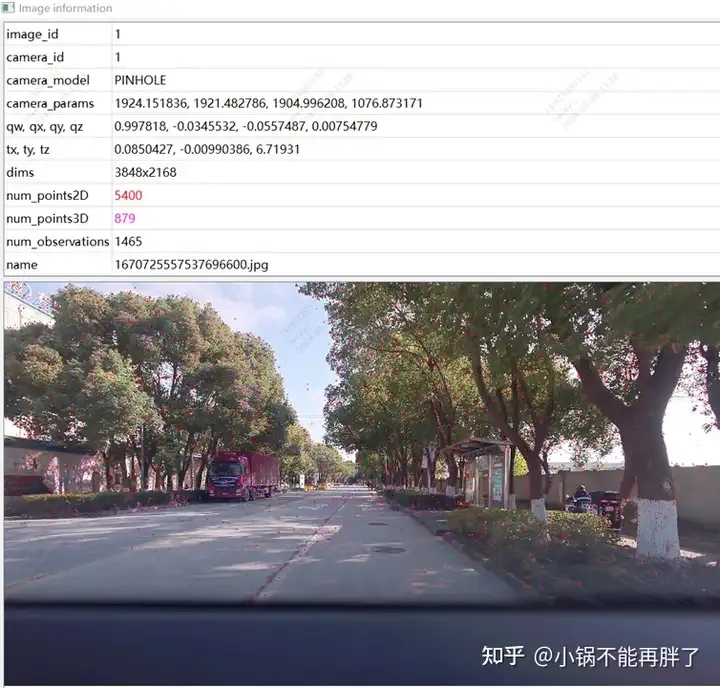
Après avoir obtenu le résultat de la reconstruction d'un seul clip, nous regrouperons plusieurs clips. Différent du schéma de correspondance de structure de mappage HDmap existant, afin de garantir la précision de l'agrégation, nous adoptons l'agrégation au niveau des points caractéristiques, c'est-à-dire que les contraintes d'agrégation entre les clips sont mises en œuvre via la correspondance des points caractéristiques. Cette opération est similaire à la détection de fermeture de boucle dans SLAM. Premièrement, le GPS est utilisé pour déterminer certaines trames de correspondance candidates ; puis, les points caractéristiques et les descriptions sont utilisés pour faire correspondre les images. Enfin, ces contraintes de fermeture de boucle sont combinées pour construire un BA (Bundle) global ; Ajustement) et optimiser. À l'heure actuelle, la précision et l'indice RTE de notre solution dépassent de loin certaines solutions de SLAM visuel ou de cartographie existantes. Expérience : utilisez la version colmap cuda, utilisez 180 images, une résolution de 3848*2168, définissez manuellement les paramètres internes et utilisez les paramètres par défaut pour le reste. La reconstruction clairsemée prend environ 15 minutes et l'ensemble de la reconstruction dense prend extrêmement longtemps. temps (1-2h)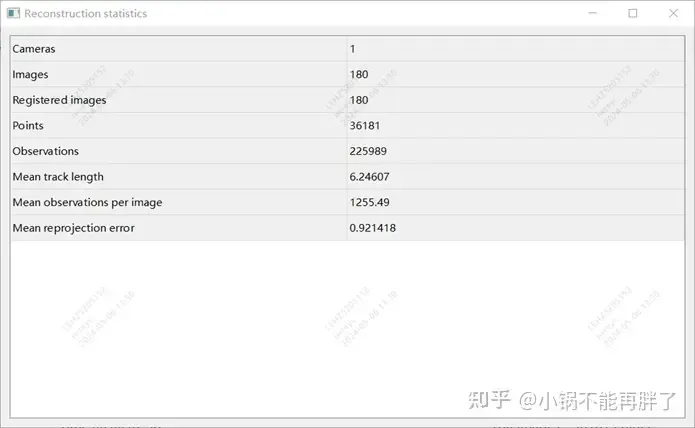





Utilisez des multi-caméras circonférentielles et panoramiques : optimisation de la carte de correspondance des points caractéristiques, éléments d'optimisation des paramètres internes et externes et utilisation de l'odom existant.
https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
pyceres.solve(solver_options, bundle_adjuster.problem, summary)
3DGS accélère la reconstruction dense, sinon cela prendra trop de temps accepter
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Cinq façons dont la vision par ordinateur peut aider à résoudre les défis commerciaux
- Cet article vous donnera une compréhension facile à comprendre de la conduite autonome
- Un article pour comprendre la perception lidar et fusion visuelle de la conduite autonome
- Introduction aux pratiques et méthodes de vision industrielle basées sur Java