
Maison >Périphériques technologiques >IA >Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-02 14:44:001566parcourir
Lors de l'interview d'hier, on m'a demandé si j'avais déjà posé des questions à longue traîne, j'ai donc pensé donner un bref résumé.
Le problème de la longue traîne des voitures autonomes fait référence aux cas limites dans les voitures autonomes, c'est-à-dire aux scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles.
Scénarios Edge dans la conduite autonome
La « longue traîne » fait référence aux cas Edge dans les véhicules autonomes (AV). Les cas Edge sont des scénarios possibles avec une faible probabilité d'occurrence. Ces événements rares sont souvent omis dans les ensembles de données car ils se produisent moins fréquemment et sont plus uniques. Si les humains sont naturellement doués pour gérer les cas extrêmes, on ne peut pas en dire autant de l’IA. Les facteurs pouvant provoquer des scènes de bordure comprennent : des camions ou des véhicules de forme spéciale avec des saillies, des véhicules effectuant des virages serrés, conduisant dans des foules bondées, des piétons marchant sur la route, des conditions météorologiques extrêmes ou de mauvaises conditions d'éclairage, des personnes tenant des parapluies, des personnes dans des voitures, puis des cartons en mouvement, des chutes d'arbres. au milieu de la route, etc.Exemple :
- Placez un film transparent devant la voiture, l'objet transparent sera-t-il reconnu et le véhicule ralentira-t-il
- La société lidar Aeye a lancé un défi, comment la conduite autonome gère-t-elle ? un ballon flottant au milieu de la route ? Les voitures sans conducteur L4 ont tendance à éviter les collisions. Dans ce cas, elles prendront des mesures d’évitement ou freineront pour éviter des accidents inutiles. Le ballon est un objet mou et peut passer directement sans aucun obstacle.
Méthodes pour résoudre le problème de la longue traîne
Les données synthétiques sont un grand concept, et les données perceptuelles (nerf, simulation de caméra/capteur) ne sont que l'une des branches les plus remarquables. Dans l’industrie, les données synthétiques sont depuis longtemps devenues la réponse standard en matière de simulation de comportement à longue traîne. Les données synthétiques, ou suréchantillonnage de signaux clairsemés, sont l’une des premières solutions au problème de la longue traîne. La capacité à longue traîne est le produit de la capacité de généralisation du modèle et de la quantité d’informations contenues dans les données.Solution Tesla :
Utiliser des données synthétiques pour générer des scènes de bord afin d'augmenter l'ensemble de données Principe du moteur de données : Détecter d'abord les inexactitudes dans le modèle existant, puis utiliser ce cas de classe ajouté à ses tests unitaires . Il collecte également davantage de données sur des cas similaires pour recycler le modèle. Cette approche itérative lui permet de capturer autant de cas extrêmes que possible. Le principal défi dans la création de cas extrêmes est que le coût de la collecte et de l'étiquetage des cas extrêmes est relativement élevé, et l'autre est que le comportement de collecte peut être très dangereux, voire impossible à réaliser.
Solution NVIDIA :
NVIDIA a récemment proposé une approche stratégique appelée "Imitation Training" (photo ci-dessous). Dans cette approche, des cas réels de défaillance du système sont recréés dans un environnement simulé, puis utilisés comme données de formation pour les véhicules autonomes. Ce cycle est répété jusqu'à ce que les performances du modèle convergent. Le but de cette approche est d’améliorer la robustesse du système de conduite autonome en simulant en continu des scénarios de pannes. La formation par simulation permet aux développeurs de mieux comprendre et résoudre différents scénarios de défaillance dans le monde réel. De plus, il peut générer rapidement de grandes quantités de données d’entraînement pour améliorer les performances du modèle. En répétant ce cycle,
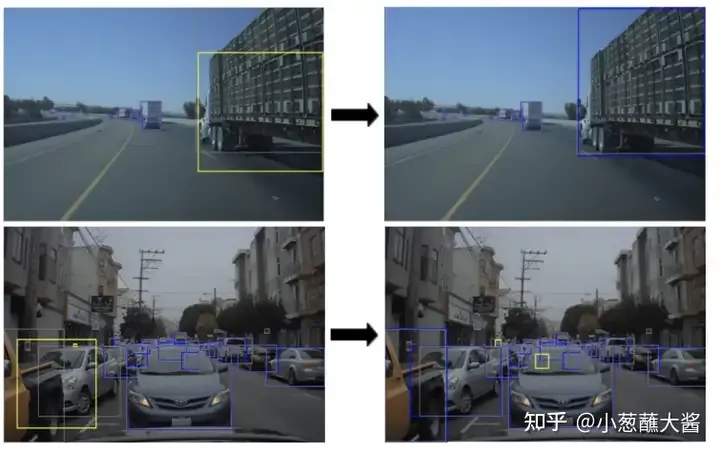
Quelques réflexions :
Q : Les données synthétiques sont-elles précieuses ? A : La valeur ici est divisée en deux types. Le premier est l'efficacité du test, c'est-à-dire tester si certaines lacunes dans l'algorithme de détection peuvent être trouvées dans la scène générée. Le second est l'efficacité de la formation, c'est-à-dire la scène générée. est utilisé Si la formation de l'algorithme peut également améliorer efficacement les performances. Q : Comment utiliser les données virtuelles pour améliorer les performances ? Est-il vraiment nécessaire d'ajouter des données factices à l'ensemble d'entraînement ? Son ajout entraînera-t-il une régression des performances ? A : Il est difficile de répondre à ces questions, c'est pourquoi de nombreuses solutions différentes ont été proposées pour améliorer la précision de l'entraînement :- Entraînement hybride : ajoutez différentes proportions de données virtuelles aux données réelles pour améliorer les performances.
- Transfert d'apprentissage : utilisez des données réelles pour pré-entraîner le modèle, puis gelez certaines couches, puis ajoutez des données mixtes pour l'entraînement.
- Apprentissage par imitation : il est également très naturel de concevoir des scénarios d'erreurs de modèle et de générer des données, améliorant ainsi progressivement les performances du modèle. Lors de la collecte de données réelle et de la formation du modèle, certaines données supplémentaires sont également collectées de manière ciblée pour améliorer les performances.
Quelques extensions :
Pour évaluer en profondeur la robustesse d'un système d'IA, les tests unitaires doivent inclure à la fois des cas généraux et des cas extrêmes. Cependant, certains cas extrêmes peuvent ne pas être disponibles à partir des ensembles de données réels existants. Pour ce faire, les praticiens de l’IA peuvent utiliser des données synthétiques à des fins de tests.
Un exemple est ParallelEye-CS, un ensemble de données synthétiques utilisé pour tester l'intelligence visuelle des véhicules autonomes. L'avantage de la création de données synthétiques par rapport à l'utilisation de données du monde réel réside dans le contrôle multidimensionnel de la scène pour chaque image.
Les données synthétiques constitueront une solution viable pour les cas extrêmes dans les modèles audiovisuels de production. Il complète les ensembles de données du monde réel avec des cas extrêmes, garantissant que l'AV reste robuste même en cas d'événements inhabituels. Il est également plus évolutif, moins sujet aux erreurs et moins cher que les données du monde réel.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les scénarios applicables pour le modèle de stratégie ?
- Quels sont les scénarios d'utilisation du middleware de messages ?
- Démontage physique du matériel Tesla Autopilot 4.0 : ajout d'un radar et fourniture de plus de caméras
- Une discussion approfondie sur l'état actuel et les tendances futures des chaînes d'outils de développement de la conduite autonome
- Tesla innove une fois de plus dans la technologie de conduite autonome : introduisant l'affichage de scènes 3D pour améliorer les fonctions d'aide au stationnement