
Maison >Périphériques technologiques >IA >Une nouvelle façon de jouer au crowdsourcing ! Le test de référence est né au LLM Arena pour séparer strictement les mauvais étudiants et les meilleurs étudiants.
Une nouvelle façon de jouer au crowdsourcing ! Le test de référence est né au LLM Arena pour séparer strictement les mauvais étudiants et les meilleurs étudiants.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-02 13:21:08487parcourir
Quelle entreprise est la meilleure dans le classement des grands modèles ? Regardez également LLM Arena~
À ce jour, un total de 90 LLM ont rejoint la bataille et le nombre total de votes des utilisateurs a dépassé 770 000.
 Photos
Photos
Cependant, tandis que les internautes se moquent des nouveaux modèles se précipitant vers le sommet et des anciens modèles perdant leur dignité,
LMSYS, l'organisation derrière Renjia Arena, a tranquillement achevé la transformation des résultats : du test de référence le plus convaincant né en combat réel-Arena-Hard.
 Photos
Photos
Les quatre avantages démontrés par Arena-Hard sont exactement ce dont le benchmark LLM actuel a le plus besoin :
-La séparabilité (87,4%) est nettement meilleure que celle du banc MT (22,6%) ;
- Classé le plus proche de Chatbot Arena à 89,1% ;
- Rapide et bon marché (25 $)
- Fréquemment mis à jour avec des données en temps réel
La traduction chinoise est, tout d'abord, cet examen à grande échelle doit être différencié, et même les étudiants pauvres ne peuvent pas obtenir 90 points
Deuxièmement, les questions de l'examen doivent être plus réalistes et la notation doit être stricte. Aligner les préférences humaines ; , les questions ne doivent pas être divulguées, les données du test doivent donc être mises à jour fréquemment pour garantir l'équité de l'examen
- Les deux dernières exigences sont taillées sur mesure pour le LLM Arena ;
Jetons un coup d'œil à l'effet du nouveau benchmark :
Photos
 L'image ci-dessus compare Arena Hard v0.1 avec le précédent benchmark SOTA MT Bench.
L'image ci-dessus compare Arena Hard v0.1 avec le précédent benchmark SOTA MT Bench.
Nous pouvons constater que par rapport à MT Bench, Arena Hard v0.1 a une séparabilité plus forte (surtension de 22,6% à 87,4%), et l'intervalle de confiance est également plus étroit.
De plus, jetez un œil à ce classement, qui est fondamentalement cohérent avec le dernier classement LLM Arena ci-dessous :
Photos
 Cela montre que l'évaluation d'Arena Hard est très proche de la préférence humaine (89,1 %) .
Cela montre que l'évaluation d'Arena Hard est très proche de la préférence humaine (89,1 %) .
——Arena Hard peut être considérée comme ouvrant une nouvelle voie de crowdsourcing :
Les internautes bénéficient d'une expérience gratuite et la plateforme officielle obtient les classements les plus influents, ainsi que des données fraîches et de haute qualité— — Le monde où personne n’est blessé est terminé.
 Questions pour les grands modèles
Questions pour les grands modèles
Voyons comment construire ce benchmark.
Pour faire simple, il s'agit de savoir comment en sélectionner de meilleures parmi les 200 000 invites (questions) des utilisateurs dans l'arène.
Ce « bien » se reflète sous deux aspects : la diversité et la complexité. L'image suivante montre le flux de travail d'Arena-Hard :
Images
 Pour résumer : classez d'abord toutes les invites (plus de 4 000 sujets sont divisés ici), puis définissez artificiellement certaines normes pour classer chaque astuce. , et les pourboires de la même catégorie sont calculés en moyenne.
Pour résumer : classez d'abord toutes les invites (plus de 4 000 sujets sont divisés ici), puis définissez artificiellement certaines normes pour classer chaque astuce. , et les pourboires de la même catégorie sont calculés en moyenne.
Les catégories avec des scores élevés peuvent être considérées comme étant d'une grande complexité (ou qualité) - ce qui est le sens de "Hard" dans Arena-Hard.
Sélectionnez les 250 catégories les mieux notées (250 garantissent la diversité) et sélectionnez au hasard 2 invites chanceuses de chaque catégorie pour former l'ensemble de référence final (500 invites).
Développez en détail ci-dessous :
Diversité
Les chercheurs ont d'abord transformé chaque astuce à l'aide du text-embedding-3-small d'OpenAI, ont réduit la dimensionnalité à l'aide de UMAP et ont identifié les clusters à l'aide d'un algorithme de clustering hiérarchique (HDBSCAN), puis ont utilisé GPT-4. -turbo pour l'agrégation.
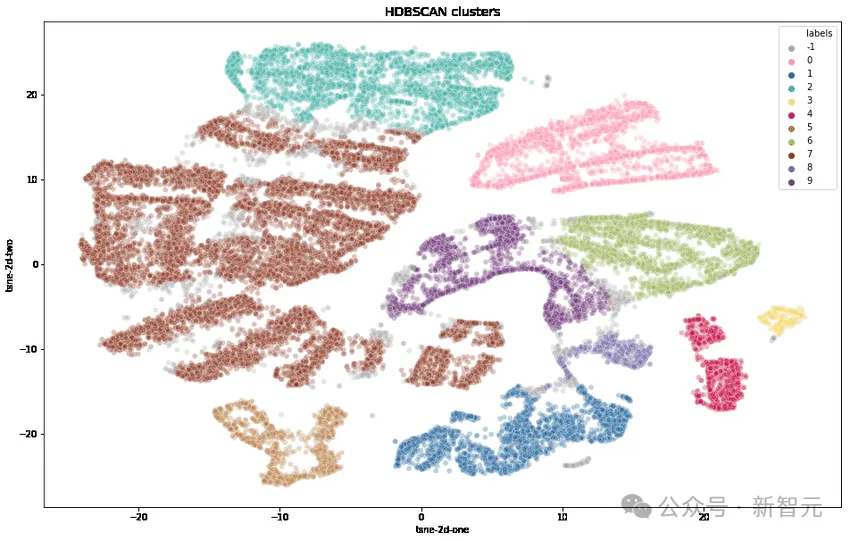
Complexité
Sélectionnez les requêtes des utilisateurs de haute qualité selon sept critères clés dans le tableau ci-dessous :
 Image
Image
1. Demander s'il faut demander une sortie spécifique ?
2. Couvre-t-il un ou plusieurs domaines spécifiques ?
3. Avez-vous plusieurs niveaux de raisonnement, de composantes ou de variables ?
4. L’IA doit-elle démontrer directement sa capacité à résoudre des problèmes ?
5. Y a-t-il un niveau de créativité impliqué ?
6. L'exactitude technique de la réponse est-elle requise ?
7. Est-ce pertinent pour les applications pratiques ?
Pour chaque astuce, utilisez LLM (GPT-3.5-Turbo, GPT-4-Turbo) pour marquer le nombre de critères auxquels elle répond (score de 0 à 7), puis calculez la moyenne de chaque groupe d'astuces (clustering) Fraction.
La figure suivante montre le classement des scores moyens de certains clusters :
 Image
Image
Nous pouvons observer que les clusters avec des scores plus élevés sont généralement des sujets plus difficiles (tels que le développement de jeux, la preuve mathématique), tandis que les clusters avec des scores inférieurs appartiennent à des problèmes triviaux ou ambigus.
Avec cette complexité, l'écart entre les meilleurs étudiants et les étudiants pauvres peut être élargi. Regardons les résultats expérimentaux ci-dessous :
 Photos
Photos
Dans les 3 comparaisons ci-dessus, supposons que GPT-4 soit plus fort. que Llama2-70b, la grande coupe de Claude est plus forte que la coupe moyenne, Mistral-Large est plus forte que Mixtral,
Nous pouvons voir qu'à mesure que le score (de complexité) augmente, le taux de victoire du modèle plus fort Il s'améliore également - les meilleurs étudiants sont distingués et les mauvais étudiants sont filtrés.
Car plus le score est élevé (plus le problème est complexe), meilleure est la discrimination, c'est ainsi que 250 classements de haute qualité avec un score moyen >= 6 points (sur 7 points) ont finalement été retenus.
Ensuite, 2 astuces de chaque catégorie ont été sélectionnées au hasard pour former cette version du benchmark - Arena-Hard-v0.1.
Le correcteur du test est-il fiable ?
Maintenant que les épreuves sont sorties, qui les jugera est une question.
Bien sûr, le travail manuel est le plus précis, et comme il s'agit du "mode difficile", de nombreux problèmes impliquant des connaissances dans le domaine nécessitent encore une évaluation par des experts - ce n'est évidemment pas possible.
Ensuite, la meilleure chose à faire est de choisir GPT-4, le modèle le plus intelligent actuellement reconnu, comme professeur de test.
Par exemple, dans les graphiques ci-dessus, tous les aspects de la notation sont gérés par GPT-4. De plus, les chercheurs ont utilisé CoT pour inciter LLM à générer des réponses avant de rendre un verdict.
Résultats du jugement GPT-4
Ce qui suit utilise gpt-4-1106-preview comme modèle de jugement, et la ligne de base de comparaison utilise gpt-4-0314.
 Photos
Photos
Les coefficients Bradley-Terry de chaque modèle sont comparés et calculés dans le tableau ci-dessus, et convertis en taux gagnants par rapport à la ligne de base comme score final. Des intervalles de confiance de 95 % ont été calculés sur 100 cycles de bootstrap.
Claude a exprimé son mécontentement
——Moi, Claude-3 Opus, je suis également à égalité au premier rang du classement. Pourquoi devrais-je laisser GPT être juge ?
Ainsi, les chercheurs ont comparé les performances de GPT-4-1106-Preview et Claude-3 Opus en tant qu'enseignants de notation.
Résumé en une phrase : GPT-4 est un père strict et Claude-3 est une mère aimante.
 Image
Image
La séparabilité entre les modèles est plus élevée (allant de 23,0 à 78,0) lorsqu'elle est notée à l'aide de GPT-4.
Lorsque j'utilise Claude-3, les scores de la plupart des modèles se sont beaucoup améliorés : je dois absolument prendre soin de mes propres modèles, j'aime aussi les modèles open source (Mixtral, Yi, Starling), gpt-4-0125 -aperçu aussi Mieux que moi en effet.
Claude-3 aime même plus gpt-3.5-0613 que gpt-4-0613.
Le tableau ci-dessous compare plus en détail GPT-4 et Claude-3 en utilisant des métriques de séparabilité et de cohérence :
 Photos
Photos
À partir des données résultantes, GPT-4 est mieux évident sur toutes les métriques.
En comparant manuellement différents exemples de jugement entre GPT-4 et Claude-3, nous pouvons constater que lorsque deux LLM ne sont pas d'accord, ils peuvent généralement être divisés en deux grandes catégories :
Notation conservatrice et notation conservatrice Différents points de vue des invites utilisateur.
Claude-3-Opus est plus indulgent dans sa notation et est beaucoup moins susceptible de donner des notes sévères - il hésite particulièrement à prétendre qu'une réponse est "bien meilleure" qu'une autre.
En revanche, GPT-4-Turbo identifie les erreurs dans les réponses du modèle et pénalise le modèle avec des scores nettement inférieurs.
En revanche, Claude-3-Opus ignore parfois les petites erreurs. Même lorsque Claude-3-Opus détecte ces erreurs, il a tendance à les traiter comme des problèmes mineurs et se montre très indulgent lors du processus de notation.
Même dans les problèmes de codage et de mathématiques où de petites erreurs peuvent en fait complètement ruiner la réponse finale, Claude-3-Opus traite toujours ces erreurs avec indulgence, contrairement à GPT-4-Turbo.
 Photos
Photos
Pour un autre petit ensemble de conseils, Claude-3-Opus et GPT-4-Turbo sont jugés sous des perspectives fondamentalement différentes.
Par exemple, face à un problème de codage, Claude-3-Opus préfère une structure simple qui ne s'appuie pas sur des bibliothèques externes, qui peuvent apporter à l'utilisateur une réponse à valeur pédagogique maximale.
Et GPT-4-Turbo peut donner la priorité aux réponses qui fournissent les réponses les plus pratiques, quelle que soit sa valeur éducative pour l'utilisateur.
Bien que les deux explications soient des critères valables pour juger, le point de vue de GPT-4-Turbo est peut-être plus proche de celui des utilisateurs ordinaires.
Voir l'image ci-dessous pour des exemples spécifiques de différents jugements, dont beaucoup présentent ce phénomène.
 Photos
Photos
Test limité
LLM Vous aimez une réponse plus longue ?
La longueur moyenne des jetons et le score de chaque modèle sur MT-Bench et Arena-Hard-v0.1 sont tracés ci-dessous. Visuellement, il n’y a pas de forte corrélation entre fraction et longueur.
 Photos
Photos
Pour examiner plus en détail les biais de verbosité potentiels, les chercheurs ont utilisé GPT-3.5-Turbo pour supprimer trois invites système différentes (brutes, bavardes, verbeuses).
Les résultats montrent que les jugements de GPT-4-Turbo et Claude-3-Opus peuvent être affectés par une sortie plus longue, tandis que Claude est plus affecté (car le jugement de GPT-3.5-Turbo sur GPT-4-0314 The le taux de réussite dépasse 40 %).
Fait intéressant, « bavard » a eu peu d'impact sur les taux de victoire des deux juges, ce qui indique que la longueur du résultat n'est pas le seul facteur, et que des réponses plus détaillées peuvent également être favorisées par les juges LLM.
 Photos
Photos
Conseils pour l'expérimentation :
détaillé : Vous êtes un assistant utile qui explique les choses de manière approfondie avec autant de détails que possible
bavard : Vous êtes un assistant serviable et bavard .
Variance des jugements GPT-4
Les chercheurs ont découvert que même avec une température = 0, GPT-4-Turbo peut toujours produire des jugements légèrement différents.
Le jugement suivant sur gpt-3.5-turbo-0125 est répété trois fois et la variance est calculée.
 Photos
Photos
En raison d'un budget limité, une seule évaluation de tous les modèles est effectuée ici. Cependant, les auteurs recommandent d'utiliser des intervalles de confiance pour déterminer la séparation des modèles.
Référence : https://www.php.cn/link/6e361e90ca5f9bee5b36f3d413c51842
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les types de données simples en langage C ?
- comment créer une base de données SQL
- Quelles sont les étapes pour se connecter à la base de données à l'aide de jdbc ?
- Moda Community lance un cadre de développement d'agents IA, permettant à chacun de « créer » des applications d'agents intelligentes basées sur un LLM open source
- Comment utiliser l'algorithme Bellman-Ford en C++