

 Périphériques technologiquesIAS'adaptant à de multiples formes et tâches, le système d'apprentissage robot open source le plus puissant 'Octopus' est né
Périphériques technologiquesIAS'adaptant à de multiples formes et tâches, le système d'apprentissage robot open source le plus puissant 'Octopus' est né
En termes d'apprentissage robotique, une approche courante consiste à collecter un ensemble de données spécifiques à un robot et à une tâche spécifiques, puis à l'utiliser pour entraîner une politique. Cependant, si cette méthode est utilisée pour apprendre à partir de zéro, suffisamment de données doivent être collectées pour chaque tâche, et la capacité de généralisation de la politique qui en résulte est généralement faible.
« En principe, l'expérience collectée auprès d'autres robots et tâches peut fournir des solutions possibles, permettant au modèle de voir une variété de problèmes de contrôle du robot, et ces problèmes peuvent améliorer les performances générales du robot sur les tâches en aval. Cependant, même s'il y en a. sont des modèles généraux capables de gérer une variété de tâches de langage naturel et de vision par ordinateur, il est encore difficile de construire un « modèle de robot universel » pour former une stratégie de contrôle unifiée pour le robot. Extrêmement difficile, impliquant de nombreuses difficultés, notamment le fonctionnement de différents corps de robot, configurations de capteurs, espaces d'action, spécifications de tâches, environnements et budgets de calcul.
Afin d'atteindre cet objectif, certains résultats de recherche liés au « modèle de base du robot » sont apparus ; leur approche consiste à mapper directement les observations du robot en actions, puis à les généraliser à de nouveaux domaines ou à de nouveaux robots grâce à des solutions sans échantillon. Ces modèles sont souvent appelés « politiques robotiques généralistes » ou GRP, qui mettent l'accent sur la capacité du robot à effectuer un contrôle visuomoteur de bas niveau sur une variété de tâches, d'environnements et de systèmes robotiques.
GNM (General Navigation Model) convient à une variété de scénarios de navigation de robots différents. RoboCat peut faire fonctionner différents corps de robot en fonction des objectifs de la mission. RT-X peut faire fonctionner cinq corps de robot différents via le langage. Bien que ces modèles constituent en effet une avancée importante, ils souffrent également de multiples limitations : leurs observations d'entrée sont souvent prédéfinies et souvent limitées (comme par exemple un flux vidéo d'entrée d'une seule caméra) ; modèles Les plus grandes versions ne sont pas disponibles pour les utilisateurs (c'est important).
Récemment, l'équipe Octo Model composée de 18 chercheurs de l'Université de Californie à Berkeley, de l'Université de Stanford, de l'Université Carnegie Mellon et de Google DeepMind a publié ses résultats de recherche révolutionnaires : le modèle Octo. Ce projet surmonte efficacement les limitations ci-dessus.

- Adresse de l'article : https://arxiv.org/pdf/2405.12213
- Projets open source : https://octo-models.github.io/
- Ils ont conçu un système qui permet à GRP de faire face plus facilement aux problèmes de diversification des interfaces des applications robotiques en aval.
Le cœur du modèle est l'architecture Transformer, qui mappe des jetons d'entrée arbitraires (créés sur la base d'observations et de tâches) en jetons de sortie (puis codés en actions), et cette architecture peut être utilisée avec divers ensembles de données de robots et de tâches. former. La politique peut accepter différentes configurations de caméras sans formation supplémentaire, contrôler différents robots et être guidée par des commandes verbales ou des images cibles, le tout en modifiant simplement les jetons entrés dans le modèle.
Plus important encore, le modèle peut également s'adapter à de nouvelles configurations de robots avec différentes entrées de capteurs, espaces de fonctionnement ou morphologies de robots. Il suffit d'adopter un adaptateur approprié et d'utiliser un petit ensemble de données de domaine cible et une petite quantité de données. données. Calculer le budget pour un réglage fin.
De plus, Octo a également été pré-formé sur le plus grand ensemble de données de manipulation de robots à ce jour : 800 000 démonstrations de robots issues de l'ensemble de données Open X-Embodiment. Octo n'est pas seulement le premier GRP à être adapté efficacement aux nouveaux espaces d'observation et d'action, c'est aussi la première stratégie généraliste de manipulation de robots entièrement open source (workflow de formation, points de contrôle du modèle et données). L'équipe a également souligné dans le document la nature unique et innovante de ses composants Octo combinés.
Modèle Octo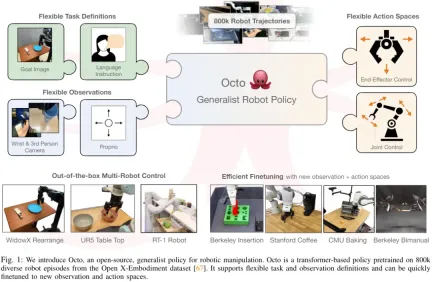
Voyons comment Octo, une stratégie de robot généraliste open source, est construite. Dans l’ensemble, Octo est conçu pour être une stratégie robotique généraliste flexible et largement applicable qui peut être utilisée par un certain nombre d’applications robotiques et de projets de recherche différents en aval.
Architecture
Le cœur d'Octo est basé sur la stratégie π de Transformer. Il contient trois éléments clés : le tokenizer d'entrée, le réseau fédérateur Transformer et la tête de lecture.
Comme le montre la figure 2, la fonction du tokenizer d'entrée est de convertir les instructions de langage, les cibles et les séquences d'observation en jetons. Le squelette du Transformer traitera ces jetons en intégrations et la tête de lecture obtiendra la sortie requise. c'est-à-dire l'action.
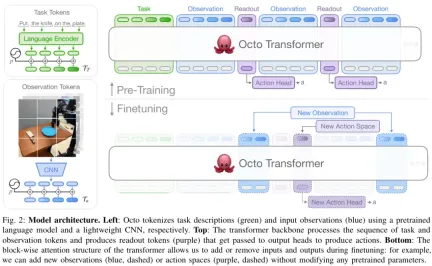
Task and Observation Tokenizer
Pour convertir les définitions de tâches (telles que les instructions linguistiques et les images cibles) et les observations (telles que les flux vidéo de caméra) en formats tokenisés couramment utilisés, l'équipe a ciblé Différentes modalités utilisent différents tokeniseurs :
Pour la saisie du langage, il est d'abord tokenisé, puis traité en une séquence de jetons intégrant un langage via un transformateur pré-entraîné. Plus précisément, le modèle qu'ils ont utilisé est la base t5 (111M).
Pour les observations d'images et les cibles, elles sont traitées à travers une pile de convolution moins profonde, puis divisées en une séquence de tuiles aplaties.
Enfin, la séquence d'entrée du Transformateur est construite en ajoutant des intégrations de positions apprenables aux jetons de tâche et d'observation et en les organisant dans un certain ordre.
Spine dorsale du transformateur et tête de lecture
Après avoir traité l'entrée en une séquence de jetons unifiée, elle peut être transmise au Transformer pour traitement. Ceci est similaire aux travaux de recherche antérieurs sur la formation de politiques basées sur des transformateurs basées sur des observations et des séquences d'action.
Le mode attention d'Octo est un masquage bloc par bloc : les jetons d'observation ne peuvent prêter attention qu'aux jetons et aux jetons de tâche du même pas de temps ou des pas de temps précédents selon la relation causale. Les jetons correspondant à des observations inexistantes sont complètement masqués (comme les jeux de données sans instructions de langage). Cette conception modulaire facilite l'ajout ou la suppression d'observations ou de tâches pendant la phase de mise au point.
En plus de ces modules de jetons d'entrée, l'équipe a également inséré des jetons de lecture appris. Le jeton de lecture prêtera attention à ses jetons d'observation et de tâche précédents, mais ne sera pris en compte par aucun jeton d'observation ou de tâche. Par conséquent, les jetons de lecture peuvent uniquement lire et traiter l'intégration interne, mais ne peuvent pas affecter l'intégration interne. Le jeton de lecture agit de la même manière que le jeton [CLS] dans BERT, agissant jusqu'à présent comme un vecteur compact intégrant la séquence d'observations. Pour l'intégration des jetons de lecture, un « en-tête d'action » léger qui implémente le processus de diffusion sera utilisé. Cet en-tête d'action prédit un « morceau » de plusieurs actions consécutives.
Cette conception permet aux utilisateurs d'ajouter de manière flexible de nouvelles tâches et des en-têtes d'entrée d'observation ou de sortie d'action au modèle lors du réglage fin en aval. Lors de l'ajout de nouvelles tâches, observations ou fonctions de perte en aval, vous pouvez conserver les poids pré-entraînés du Transformer dans leur ensemble et ajouter uniquement de nouvelles intégrations positionnelles, un nouvel encodeur léger ou de nouveaux en-têtes nécessaires en raison des modifications des paramètres de spécification. Cela diffère des architectures précédentes, qui nécessitaient la réinitialisation ou le recyclage de nombreux composants du modèle pré-entraîné si des entrées d'image étaient ajoutées ou supprimées ou si les spécifications des tâches étaient modifiées.
Pour faire d'Octo un véritable modèle "généraliste", cette flexibilité est cruciale : puisqu'il nous est impossible de couvrir toutes les configurations possibles de capteurs et d'actions du robot en phase de pré-entraînement, si nous pouvons ajuster Octo en fin d'entraînement. étape de réglage Ses entrées et sorties en font un outil polyvalent pour la communauté robotique. De plus, les conceptions de modèles précédentes qui utilisaient une structure de transformateur standard ou fusionnaient un encodeur visuel avec une tête de sortie MLP fixaient le type et l'ordre des entrées du modèle. En revanche, changer d'observations ou de tâches d'Octo ne nécessite pas de réinitialisation d'une grande partie du modèle.
Données d'entraînement
L'équipe a pris un ensemble de données mixte de 25 ensembles de données d'Open X-Embodiment. La figure 3 donne la composition de l'ensemble de données.

Veuillez vous référer au document original pour plus de détails sur les objectifs de formation et la configuration du matériel de formation.
Modèles de points de contrôle et de code
Voici le point ! L'équipe a non seulement publié l'article d'Octo, mais a également rendu toutes les ressources entièrement open source, notamment :
- Points de contrôle Octo pré-entraînés, dont Octo-Small avec 27 millions de paramètres et Octo-Base avec 93 millions de paramètres.
- Script de mise au point pour les modèles Octo, basé sur JAX.
- Modéliser le workflow de pré-formation pour la pré-formation d'Octo sur l'ensemble de données Open X-Embodiment, basé sur JAX. Chargeur de données pour les données Open X-Embodiment, compatible avec JAX et PyTorch.
Expérience
L'équipe a également mené une analyse empirique d'Octo à travers des expériences et évalué ses performances en tant que modèle de robot de base dans plusieurs dimensions :
- Octo peut-il être directement utilisé pour contrôler plusieurs robots Robot ? corps et résoudre des tâches linguistiques et cibles ?
- Les poids Octo peuvent-ils servir de bonne base d'initialisation pour prendre en charge un réglage fin et efficace des données pour de nouvelles tâches et de nouveaux robots, et sont-ils supérieurs aux méthodes de formation à partir de zéro et aux représentations pré-entraînées couramment utilisées ?
- Quelle décision de conception dans Octo est la plus importante lorsqu'il s'agit de construire une stratégie robotique généraliste ?
La figure 4 montre les 9 tâches pour évaluer Octo.

Utilisez directement Octo pour contrôler plusieurs robots
L'équipe a comparé les capacités de contrôle sans échantillon d'Octo, RT-1-X et RT-2-X. Les résultats sont présentés dans. Graphique 5.
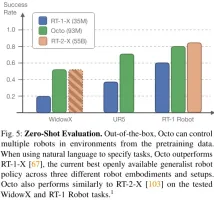
On constate que le taux de réussite d'Octo est 29% supérieur à celui du RT-1-X (35 millions de paramètres). Dans l'évaluation WidowX et RT-1 Robot, les performances d'Octo sont équivalentes à celles de RT-2-X avec 55 milliards de paramètres.
De plus, RT-1-X et RT-2-X ne prennent en charge que les commandes de langage, tandis qu'Octo prend également en charge les images conditionnelles sur la cible. L’équipe a également constaté que sur la tâche WidowX, les taux de réussite étaient 25 % plus élevés lorsqu’ils étaient conditionnés aux images cibles que lorsqu’ils étaient conditionnés au langage. Cela peut être dû au fait que les images cibles fournissent plus d'informations sur l'achèvement des tâches.
Octo peut utiliser efficacement les données pour s'adapter à de nouveaux champs
Le Tableau 1 donne les résultats expérimentaux d'un réglage fin efficace des données.

Vous pouvez voir qu'un réglage fin d'Octo donne de meilleurs résultats qu'un entraînement à partir de zéro ou un pré-entraînement avec des poids VC-1 pré-entraînés. Sur 6 paramètres d'évaluation, l'avantage moyen d'Octo par rapport à la deuxième place est de 52 % !
Et je dois mentionner : pour toutes ces tâches d'évaluation, les recettes et hyperparamètres utilisés lors du réglage fin d'Octo étaient tous les mêmes, ce qui montre que l'équipe a trouvé une très bonne configuration par défaut.
Décisions de conception pour une formation généraliste aux politiques robotiques
Les résultats ci-dessus montrent qu'Octo peut en effet être utilisé comme un contrôleur multi-robot à tir nul et peut également être utilisé comme base d'initialisation pour le réglage fin des politiques . Ensuite, l'équipe a analysé l'impact de différentes décisions de conception sur les performances de la stratégie Octo. Plus précisément, ils se concentrent sur les aspects suivants : l'architecture du modèle, les données de formation, les objectifs de formation et la taille du modèle. Pour ce faire, ils ont mené des études d’ablation.
Le tableau 2 présente les résultats de l'étude d'ablation sur l'architecture du modèle, les données de formation et les objectifs de formation.

La figure 6 montre l'impact de la taille du modèle sur le taux de réussite de l'échantillon zéro. On peut voir que les modèles plus grands ont de meilleures capacités de perception visuelle de la scène.
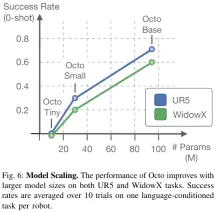
Dans l’ensemble, l’efficacité des composants d’Octo a été prouvée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 L'écart de compétences en IA ralentit les chaînes d'approvisionnementApr 26, 2025 am 11:13 AM
L'écart de compétences en IA ralentit les chaînes d'approvisionnementApr 26, 2025 am 11:13 AMLe terme «main-d'œuvre prêt pour l'IA» est fréquemment utilisé, mais qu'est-ce que cela signifie vraiment dans l'industrie de la chaîne d'approvisionnement? Selon Abe Eshkenazi, PDG de l'Association for Supply Chain Management (ASCM), il signifie des professionnels capables de critique
 Comment une entreprise travaille tranquillement pour transformer l'IA pour toujoursApr 26, 2025 am 11:12 AM
Comment une entreprise travaille tranquillement pour transformer l'IA pour toujoursApr 26, 2025 am 11:12 AMLa révolution de l'IA décentralisée prend tranquillement de l'ampleur. Ce vendredi à Austin, au Texas, le Sommet de fin de partie Bittensor marque un moment pivot, en transition de l'IA décentralisée (DEAI) de la théorie à l'application pratique. Contrairement à la publicité fastueuse
 NVIDIA publie des microservices NEMO pour rationaliser le développement des agents AIApr 26, 2025 am 11:11 AM
NVIDIA publie des microservices NEMO pour rationaliser le développement des agents AIApr 26, 2025 am 11:11 AML'IA de l'entreprise fait face à des défis d'intégration des données L'application de l'IA de l'entreprise est confrontée à un défi majeur: la construction de systèmes qui peuvent maintenir la précision et la pratique en apprenant continuellement les données commerciales. Les microservices NEMO résolvent ce problème en créant ce que NVIDIA décrit comme "Data Flywheel", permettant aux systèmes d'IA de rester pertinents par une exposition continue aux informations de l'entreprise et à l'interaction des utilisateurs. Cette boîte à outils nouvellement lancée contient cinq microservices clés: NEMO Customizer gère le réglage fin des modèles de grands langues avec un débit de formation plus élevé. L'évaluateur NEMO fournit une évaluation simplifiée des modèles d'IA pour les repères personnalisés. NEMO Guar-Rails met en œuvre des contrôles de sécurité pour maintenir la conformité et la pertinence
 L'IA dépeint une nouvelle image pour l'avenir de l'art et du designApr 26, 2025 am 11:10 AM
L'IA dépeint une nouvelle image pour l'avenir de l'art et du designApr 26, 2025 am 11:10 AMAI: L'avenir de l'art et du design L'intelligence artificielle (IA) modifie le domaine de l'art et de la conception de manière sans précédent, et son impact ne se limite plus aux amateurs, mais affectant plus profondément les professionnels. Les schémas d'œuvres d'art et de conception générés par l'IA remplacent rapidement les images et les concepteurs de matériaux traditionnels dans de nombreuses activités de conception transactionnelles telles que la publicité, la génération d'images des médias sociaux et la conception Web. Cependant, les artistes et designers professionnels trouvent également la valeur pratique de l'IA. Ils utilisent l'IA comme outil auxiliaire pour explorer de nouvelles possibilités esthétiques, mélanger différents styles et créer de nouveaux effets visuels. L'IA aide les artistes et les concepteurs à automatiser les tâches répétitives, à proposer différents éléments de conception et à fournir une contribution créative. L'IA prend en charge le transfert de style, qui doit appliquer un style d'image
 Comment le zoom révolutionne le travail avec l'agent AI: des réunions aux jalonsApr 26, 2025 am 11:09 AM
Comment le zoom révolutionne le travail avec l'agent AI: des réunions aux jalonsApr 26, 2025 am 11:09 AMZoom, initialement connu pour sa plate-forme de vidéoconférence, dirige une révolution en milieu de travail avec son utilisation innovante de l'IA agentique. Une conversation récente avec le CTO de Zoom, XD Huang, a révélé la vision ambitieuse de l'entreprise. Définition de l'IA agentique Huang D
 La menace existentielle pour les universitésApr 26, 2025 am 11:08 AM
La menace existentielle pour les universitésApr 26, 2025 am 11:08 AML'IA va-t-elle révolutionner l'éducation? Cette question provoque une réflexion sérieuse entre les éducateurs et les parties prenantes. L'intégration de l'IA dans l'éducation présente à la fois des opportunités et des défis. Comme le note Matthew Lynch de The Tech Edvocate, Universit
 Le prototype: les scientifiques américains recherchent des emplois à l'étrangerApr 26, 2025 am 11:07 AM
Le prototype: les scientifiques américains recherchent des emplois à l'étrangerApr 26, 2025 am 11:07 AMLe développement de la recherche scientifique et de la technologie aux États-Unis peut faire face à des défis, peut-être en raison de coupes budgétaires. Selon la nature, le nombre de scientifiques américains postulant pour des emplois à l'étranger a augmenté de 32% de janvier à mars 2025 par rapport à la même période en 2024. Un sondage précédent a montré que 75% des chercheurs interrogés envisageaient de rechercher des emplois en Europe et au Canada. Des centaines de subventions NIH et NSF ont été licenciées au cours des derniers mois, avec les nouvelles subventions du NIH d'environ 2,3 milliards de dollars cette année, une baisse de près d'un tiers. Le projet de budget divulgué montre que l'administration Trump envisage de réduire fortement les budgets pour les institutions scientifiques, avec une réduction possible allant jusqu'à 50%. La tourmente dans le domaine de la recherche fondamentale a également affecté l'un des principaux avantages des États-Unis: attirer des talents à l'étranger. 35
 Tout sur la dernière famille GPT 4.1 d'Open AI - Analytics VidhyaApr 26, 2025 am 10:19 AM
Tout sur la dernière famille GPT 4.1 d'Open AI - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI dévoile la puissante série GPT-4.1: une famille de trois modèles de langage avancé conçus pour des applications réelles. Ce saut significatif en avant offre des temps de réponse plus rapides, une compréhension améliorée et des coûts considérablement réduits par rapport à T


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

SublimeText3 Linux nouvelle version
Dernière version de SublimeText3 Linux

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

VSCode Windows 64 bits Télécharger
Un éditeur IDE gratuit et puissant lancé par Microsoft

ZendStudio 13.5.1 Mac
Puissant environnement de développement intégré PHP

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

