
Maison >Périphériques technologiques >IA >Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-01 21:46:081103parcourir
1. Introduction
Les principaux détecteurs d'objets actuels sont des réseaux à deux étages ou à un étage basés sur le réseau de classificateurs de base réutilisé du Deep CNN. YOLOv3 est l'un de ces détecteurs à un étage de pointe bien connus qui reçoit une image d'entrée et la divise en une matrice de grille de taille égale. Les cellules de grille avec des centres cibles sont chargées de détecter des cibles spécifiques.
Ce que nous avons partagé aujourd'hui est de proposer une nouvelle méthode mathématique, qui attribue plusieurs grilles à chaque cible pour obtenir une prédiction précise et précise du cadre de délimitation. Les chercheurs ont également proposé une amélioration efficace des données par copier-coller hors ligne pour la détection de cibles. La méthode nouvellement proposée surpasse considérablement certains détecteurs d’objets de pointe actuels et promet de meilleures performances.
2. Contexte
Les réseaux de détection d'objets sont conçus pour localiser des objets sur des images et les étiqueter avec précision à l'aide de cadres de délimitation correspondant avec précision. Récemment, il y a eu deux manières différentes d’y parvenir. La première méthode est en termes de performances. La méthode la plus importante est la détection d'objets en deux étapes. Le meilleur représentant est le réseau neuronal convolutif régional (RCNN) et ses dérivés [Faster R-CNN : Vers une détection d'objets en temps réel avec des réseaux de proposition de région. ], [Rapide R-CNN]. En revanche, le deuxième groupe d'implémentations de détection d'objets est connu pour son excellente vitesse de détection et sa légèreté, et est appelé réseaux à une étape. Un exemple représentatif est [Vous ne regardez qu'une seule fois : Détection d'objets unifiée en temps réel], [SSD : Détecteur multibox à coup unique], [Perte focale pour la détection d'objets denses]. Le réseau à deux étages s'appuie sur un réseau de propositions de régions latentes qui génère des régions candidates d'images pouvant contenir des objets d'intérêt. Les régions candidates générées par ce réseau peuvent contenir la région d'intérêt de l'objet. Dans la détection d'objet en une seule étape, la détection est gérée simultanément avec la classification et la localisation dans une passe avant complète. Par conséquent, les réseaux à un seul étage sont généralement plus légers, plus rapides et plus faciles à mettre en œuvre.

Les recherches d'aujourd'hui adhèrent toujours à la méthode YOLO, en particulier YOLOv3, et proposent un hack simple qui peut utiliser plusieurs éléments d'unités de réseau en même temps pour prédire les coordonnées, les catégories et la confiance de la cible. La raison d'être des éléments unitaires multi-réseaux par objet est d'augmenter la probabilité de prédire des cadres de délimitation étroitement ajustés en forçant plusieurs éléments unitaires à travailler sur le même objet.

Certains avantages de l'allocation multi-grille incluent :
Le détecteur d'objet fournit une carte multi-vues de l'objet qu'il détecte, plutôt que de s'appuyer sur une seule cellule de grille pour prédire la classe de l'objet et coordonnées.
(b+) Prédictions de boîte englobante moins aléatoires et incertaines, ce qui signifie une précision et un rappel élevés car les unités de réseau proches sont entraînées pour prédire la même catégorie d'objet et les mêmes coordonnées
(c) Réduire le déséquilibre entre les cellules de la grille avec ; objets d'intérêt et cellules de grille sans objets d'intérêt.
De plus, étant donné que l'allocation multi-grille est une utilisation mathématique des paramètres existants et ne nécessite pas de couches de regroupement de points clés supplémentaires ni de post-traitement pour recombiner les points clés avec leurs cibles correspondantes, telles que CenterNet et CornerNet, on peut dire que cela est un moyen plus naturel d'obtenir ce que les détecteurs d'objets sans ancrage ou basés sur des points clés tentent d'atteindre. En plus des annotations redondantes multi-grilles, les chercheurs ont également introduit une nouvelle technologie d'amélioration des données basée sur le copier-coller hors ligne pour une détection précise des objets.
3. AFFECTATION MULTI-GRILLES

L'image ci-dessus contient trois cibles, à savoir les chiens, les vélos et les voitures. Par souci de concision, nous expliquerons notre affectation multi-grille sur un objet. L'image ci-dessus montre les cadres de sélection de trois objets, avec plus de détails sur le cadre de sélection du chien. L'image ci-dessous montre une zone agrandie de l'image ci-dessus, en se concentrant sur le centre du cadre de délimitation du chien. La coordonnée supérieure gauche de la cellule de la grille contenant le centre du cadre de sélection du chien porte le numéro 0, tandis que les huit autres cellules entourant la grille contenant le centre portent les étiquettes de 1 à 8.

Jusqu'à présent, j'ai expliqué les faits de base sur la façon dont un maillage contenant le centre du cadre de sélection d'un objet annote un objet. Cette dépendance à une seule cellule de grille par objet pour effectuer le travail difficile de prédire les catégories et les cadres de délimitation précis et bien ajustés soulève de nombreux problèmes, tels que :
(a) Écart énorme entre les grilles positives et négatives Déséquilibre, c'est-à-dire avec et sans coordonnées de grille du centre de l'objet
(b) Convergence lente de la boîte englobante vers GT
(c) Manque de vues multi-perspectives (angles) de l'objet à prédire.
Une question naturelle à poser ici est la suivante : « De toute évidence, la plupart des objets contiennent des zones de plus d'une cellule de grille. Existe-t-il donc un moyen mathématique simple d'attribuer davantage de ces cellules de grille pour essayer de prédire les catégories et les coordonnées de l'objet. avec la cellule centrale de la grille ?" Certains avantages de ceci sont (a) un déséquilibre réduit, (b) un entraînement plus rapide pour converger vers des boîtes englobantes puisque désormais plusieurs cellules de la grille ciblent simultanément le même objet, (c) une prédiction accrue des boîtes englobantes bien ajustées. L'opportunité (d) fournit une grille- des détecteurs basés sur YOLOv3 avec des vues multi-vues au lieu de vues d'objets à point unique. L’allocation multi-réseaux nouvellement proposée tente de répondre aux questions ci-dessus.
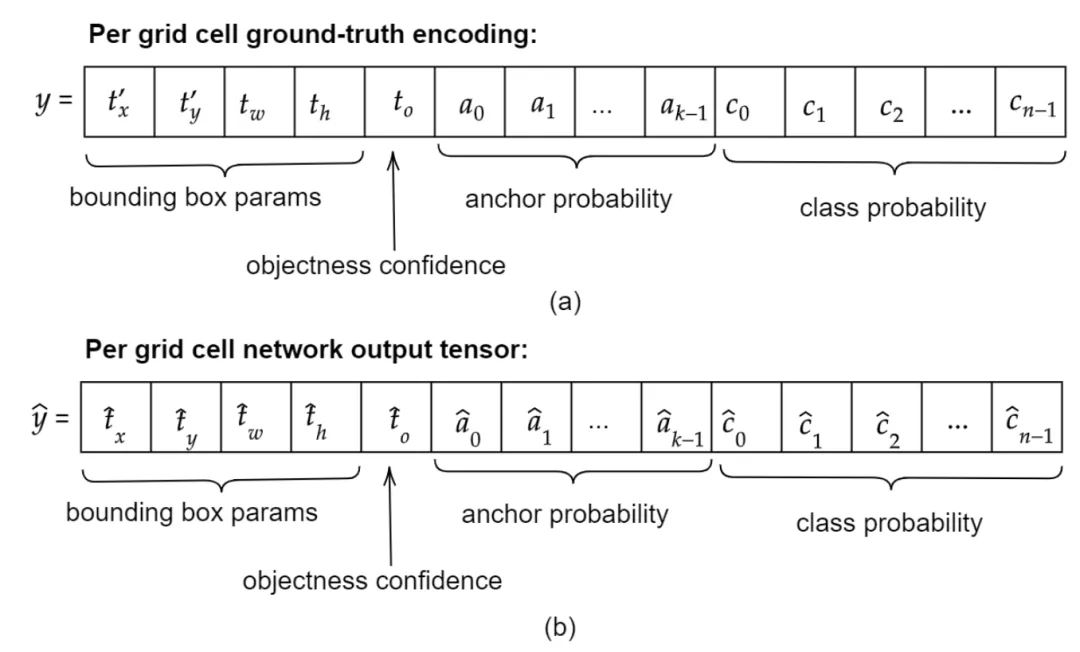
Encodage de la vérité terrain
IV. Formation
A. Le réseau de détection : MultiGridDet
Six darknets supprimés des blocs de convolution YOLOv3 pour y parvenir plus léger et plus rapide. Un bloc de convolution a un Conv2D+Batch Normalization+LeakyRelu. Les blocs supprimés ne proviennent pas du backbone de classification, c'est-à-dire Darknet53. Au lieu de cela, supprimez-les de trois réseaux ou têtes de sortie de détection multi-échelle, deux de chaque réseau de sortie. Bien que les réseaux profonds fonctionnent généralement bien, les réseaux trop profonds ont également tendance à surcharger rapidement ou à ralentir considérablement le réseau.
B. La fonction de perte
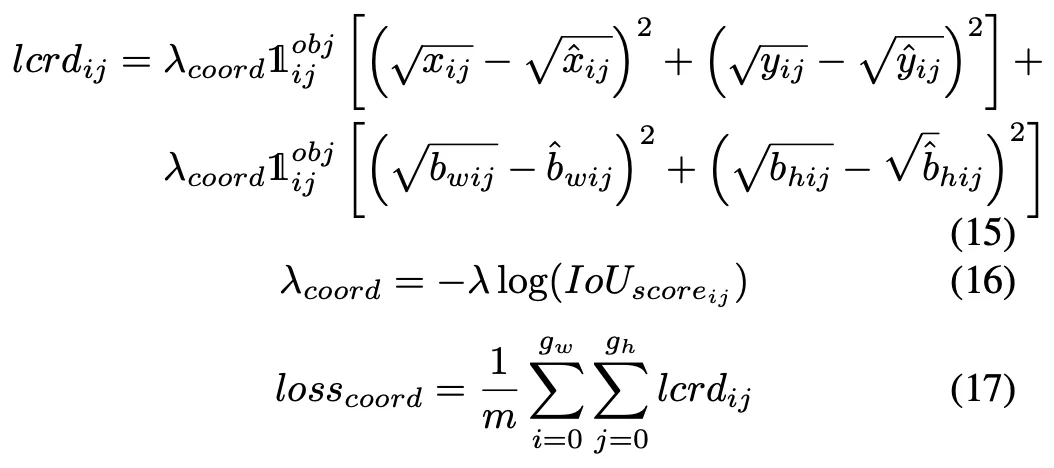
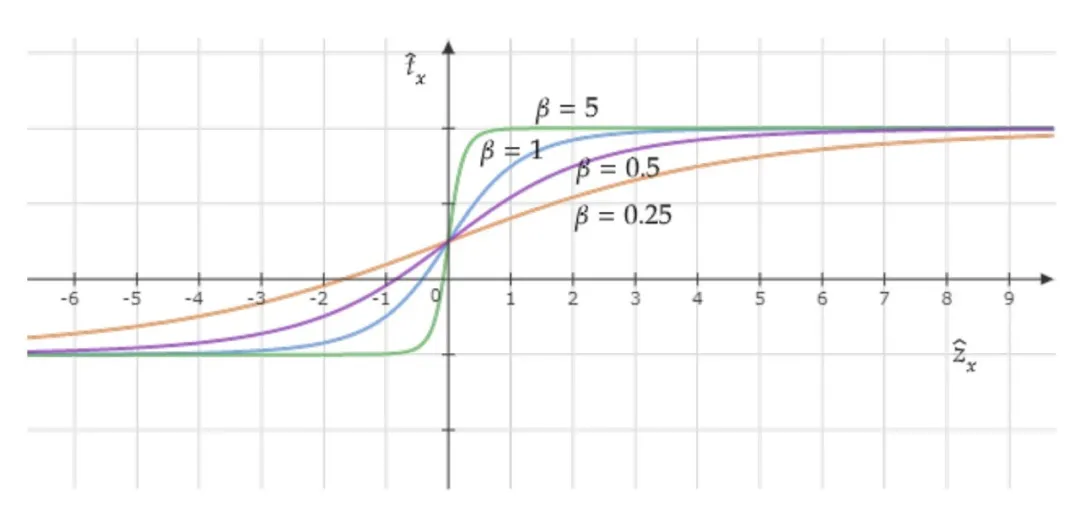
Coordonner le tracé de la fonction d'activation avec différentes valeurs β
C. fonctionne comme suit : Tout d'abord, en utilisant un simple script de recherche d'images pour télécharger des milliers d'images d'arrière-plan sans objet à partir de Google Images en utilisant des mots-clés tels que point de repère, pluie, forêt, etc., c'est-à-dire des images sans objet qui nous intéresse. Nous sélectionnons ensuite de manière itérative p objets et leurs cadres de délimitation à partir de q images aléatoires de l'ensemble de données d'entraînement. Nous générons ensuite toutes les combinaisons possibles de p boîtes englobantes sélectionnées en utilisant leurs indices comme identifiants. Dans l'ensemble combiné, nous sélectionnons un sous-ensemble de cadres de délimitation qui satisfont aux deux conditions suivantes :
s'ils sont disposés côte à côte dans un ordre aléatoire, ils doivent s'insérer dans une zone d'image d'arrière-plan cible donnée
- et devraient utiliser efficacement l'espace de l'image d'arrière-plan dans son intégralité ou au moins la majeure partie sans que les objets ne se chevauchent. Comparaison des performances sur l'ensemble de données coco
Comme le montre la figure, la première ligne montre les six. images d'entrée, tandis que la deuxième ligne montre le réseau avant la suppression non maximale (NMS). La dernière ligne montre la prédiction finale de la boîte englobante de MultiGridDet pour l'image d'entrée après NMS.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!