
 interface Webjs tutorielExplication détaillée du mode interprète des modèles de conception Javascript_compétences Javascript
interface Webjs tutorielExplication détaillée du mode interprète des modèles de conception Javascript_compétences JavascriptExplication détaillée du mode interprète des modèles de conception Javascript_compétences Javascript

Qu'est-ce que le « mode interprète » ?
Ouvrez d'abord "GOF" et regardez la définition :
Étant donné une langue, définissez une représentation de sa grammaire et définissez un interprète qui utilise cette représentation pour interpréter des phrases dans la langue.
Avant de commencer, il me reste encore à vulgariser quelques concepts :
Arbre de syntaxe abstraite :
Le mode interpréteur n'explique pas comment créer une syntaxe abstraite arbre. Cela n’implique pas d’analyse syntaxique. L'arbre de syntaxe abstraite peut être complété par un analyseur basé sur une table, ou il peut être créé par un analyseur manuscrit (généralement de descente récursive), ou fourni directement par le client.
Parseur :
fait référence à un programme qui analyse les expressions décrivant les exigences d'appel du client pour former un arbre de syntaxe abstrait.
Interprète :
fait référence au programme qui interprète l'arbre de syntaxe abstraite et exécute la fonction correspondant à chaque nœud.
Pour utiliser le mode interprète, un prérequis important est de définir un ensemble de règles grammaticales, également appelées grammaire. Que les règles de cette grammaire soient simples ou complexes, ces règles doivent être en place car le mode interprète analyse et exécute les fonctions correspondantes selon ces règles.
Jetons d'abord un coup d'œil au schéma de structure et à la description du mode interpréteur :

AbstractExpression : Définir l'interface de l'interprète et se mettre d'accord sur le fonctionnement d'interprétation de l'interprète.
TerminalExpression : L'interpréteur de terminal est utilisé pour implémenter les opérations liées aux symboles de terminal dans les règles de grammaire. Il ne contient plus d'autres interpréteurs si vous utilisez le mode combinaison pour construire un arbre de syntaxe abstrait. Pour les objets feuille en mode composite, il peut y avoir plusieurs interpréteurs de terminal.
NonterminalExpression : Interpréteur non terminal, utilisé pour implémenter des opérations liées aux symboles non terminaux dans les règles de grammaire. Habituellement, un interprète correspond à une règle de grammaire et peut inclure d'autres interprètes si le mode combiné est utilisé pour construire un. Arbre de syntaxe abstraite, il est équivalent à l'objet combinaison dans le modèle de combinaison. Il peut y avoir plusieurs interprètes non terminaux.
Contexte : Le contexte contient généralement des données ou des fonctions publiques requises par chaque interprète.
Client : Le client fait référence au client qui utilise l'interpréteur. Habituellement, les expressions faites selon la grammaire du langage sont converties en arbres de syntaxe abstraite décrits à l'aide de l'objet interpréteur, puis appelés Expliquer le opération.
Ci-dessous, nous utilisons un exemple XML pour comprendre le mode interpréteur :
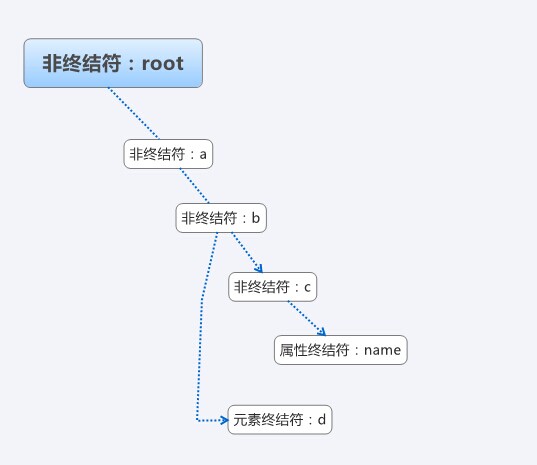
Tout d'abord, nous devons concevoir une grammaire simple pour les expressions, pour l'universalité, utilisez root pour représenter l'élément racine, abc, etc. pour représenter les éléments, un simple xml Comme suit :
/c>
>d3> ;
🎜>
La grammaire de l'expression convenue est la suivante :
1. Obtenez la valeur d'un seul élément : en commençant par l'élément racine et en allant à l'élément où vous souhaitez obtenir la valeur. séparé par "/", avant l'élément racine. N'ajoutez pas de "/". Par exemple, l'expression « root/a/b/c » signifie obtenir la valeur de l'élément a, de l'élément b et de l'élément c sous l'élément racine.
2. Récupérer la valeur de l'attribut d'un seul élément : bien sûr, il y en a plusieurs. L'attribut pour obtenir la valeur doit être l'attribut du dernier élément de l'expression et ajouter "." puis ajoutez le nom de l'attribut. Par exemple, l'expression « root/a/b/c.name » signifie obtenir la valeur de l'attribut name de l'élément a, de l'élément b et de l'élément c sous l'élément racine.
3. Obtenez la valeur du même nom d'élément, bien sûr il y en a plusieurs. L'élément pour obtenir la valeur doit être le dernier élément de l'expression, ajoutez "$" après le dernier élément. Par exemple, l'expression "root/a/b/d$" signifie obtenir l'ensemble des valeurs de plusieurs éléments d sous l'élément racine, sous l'élément a et sous l'élément b.
4. Récupérez la valeur de l'attribut avec le même nom d'élément, bien sûr il y en a plusieurs : l'élément pour obtenir la valeur de l'attribut doit être le dernier élément de l'expression, ajoutez "$" après le dernier élément. Par exemple, l'expression "root/a/b/d$.id$" signifie obtenir l'ensemble des valeurs d'attribut id de plusieurs éléments d sous l'élément racine, sous l'élément a et sous l'élément b.
Le XML ci-dessus, l'arbre de syntaxe abstraite correspondant, la structure possible est comme indiqué dans la figure :
Jetons un coup d'œil au code spécifique :
Définir le contexte :
/**
* Contexte, utilisé pour contenir certaines informations globales nécessaires à l'interpréteur
* @param {String} filePathName [le chemin et le nom du XML qui doit être lu]
*/
function Context(filePathName) {
// Élément traité précédent
this.preEle = null;
// Objet document xml
this.document = XmlUtil.getRoot(filePathName);
>
Context.prototype = {
// Réinitialiser le contexte
reInit: function() {
this.preEle = null;
},
/**
* Méthodes couramment utilisées par diverses expressions
* Obtenez l'élément actuel en fonction du nom de l'élément parent et de l'élément actuel
* @param {Element} pEle [Élément parent]
* @param {String} eleName [Nom de l'élément actuel]
* @return {Element|null} [Élément actuel trouvé]
*/
getNowEle : function (pEle, eleName) {
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1)
if (nowEle .nodeName === eleName)
return null;
getPreEle: function () {
return this.preEle;
},
setPreEle: function (preEle) {
this.preEle = preEle;
},
getDocument: function () {
return this.document;
}
};
// Objet outil
// Analyser XML et obtenir l'objet Document correspondant
var ;
var xmldom = parser.parseFromString('
return xmldom;
Voici le code de l'interprète :
Copier le code
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpréter : fonction (contexte) {
var pEle = context.getPreEle();
var ele = null;
if (!pEle) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEle(pEle, this.eleName);
context.setPreEle(ele);
}
// Récupère la valeur de l'élément
Return Ele.firstChild.NodeValue
}
}
/**
* L'interpréteur correspondant à l'attribut comme symbole terminal
* @param {String} propName [Nom de l'attribut]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpréter : function (context) {
// Récupère directement la valeur du dernier attribut de l'élément
return context.getPreEle().getAttribute(this.propName);
}
};
Voyons d'abord comment utiliser l'interpréteur pour obtenir la valeur d'un seul élément :
void function() {
var c = new Context();
// Si vous souhaitez obtenir la valeur de plusieurs éléments d, c'est-à-dire la valeur de l'expression suivante : "root/a/b/c"
// Tout d'abord, vous devez construire l'arbre de syntaxe abstraite de l'interpréteur
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b' );
var cEle = new ElementTerminalExpression ('c');
// Combinaison
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
console.log('La valeur de c est = ' root.interpret(c));
}();
Sortie : La valeur de c est = 12345
Ensuite, nous utilisons le code ci-dessus pour obtenir la valeur de l'attribut d'un seul élément :
void function() {
var c = new Context();
// Vous souhaitez obtenir l'attribut id de l'élément d, qui est la valeur de l'expression suivante : "a/ b/c .name"
// c n'est pas terminé pour le moment, vous devez modifier c en ElementExpression
var root = new ElementExpression('root');
var aEle = new ElementExpression(' a');
var bEle = new ElementExpression('b');
var cEle = new ElementExpression('c');
var prop = new PropertyTerminalExpression('name');
// Combinaison
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
cEle.addEle(prop);
console.log('La valeur du nom d'attribut de c est = ' root.interpret(c));
// Si vous souhaitez utiliser le même contexte pour une analyse continue, vous devez réinitialiser l'objet contexte
// Par exemple, si vous souhaitez réobtenir continuellement la valeur du nom de l'attribut, de bien sûr, vous pouvez recombiner les éléments
/ / Ré-analyser, tant que vous utilisez le même contexte, vous devez réinitialiser l'objet de contexte
c.reInit( ));
} ();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
C'est précisément à cause de la manière dont un objet interpréteur est responsable d'une règle de grammaire qu'il est très facile d'étendre de nouvelles grammaires. Pour étendre la nouvelle syntaxe, il vous suffit de créer l'objet interpréteur correspondant et d'utiliser ce nouvel objet interpréteur lors de la création de l'arbre de syntaxe abstraite.
Inconvénients :
Ne convient pas aux syntaxes complexes
Si la grammaire est particulièrement complexe, le travail de construction de l'arbre de syntaxe abstraite requis pour le mode interpréteur est très ardu, et plusieurs arbres de syntaxe abstraite peuvent devoir être construits. Le mode interprète n’est donc pas adapté aux grammaires complexes. Il serait peut-être préférable d'utiliser un analyseur ou un générateur de compilateur.
Quand utiliser ?
Lorsqu'il y a un langage qui doit être interprété et exécuté, et que les phrases du langage peuvent être représentées comme un arbre de syntaxe abstraite, vous pouvez envisager d'utiliser le mode interprète.
Lors de l'utilisation du mode interprète, il y a deux autres caractéristiques à prendre en compte. L'une est que la syntaxe doit être relativement simple et qu'elle n'est pas adaptée à l'utilisation du mode interprète. les exigences ne sont pas très élevées ; élevées, ne conviennent pas à l’utilisation.
L'article précédent a expliqué comment obtenir la valeur d'un seul élément et la valeur d'un seul attribut d'élément. Voyons comment obtenir la valeur de plusieurs éléments, ainsi que les valeurs des noms de. plusieurs éléments, ainsi que les tests précédents.Pour l'arbre de syntaxe abstraite artificiellement assemblé, nous avons également implémenté l'analyseur simple suivant pour convertir les expressions conformes à la grammaire précédemment définie dans l'arbre de syntaxe abstraite de l'interpréteur précédemment implémenté : J'ai posté le code directement :
// 读取多个元素或属性的值
(function () {
/**
* 上下文,用来包含解释器需要的一些全局信息
* @param {String} filePathName [需要读取的xml的路径和名字]
*/
function Context(filePathName) {
// 上一个被处理的多个元素
this.preEles = [];
// xml的Document对象
this.document = XmlUtil.getRoot(filePathName);
}
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
/**
* 依照分解的位置和名稱來設定需要分析的元素名稱
* @param {String} ele [元素名稱]
* @param {Boolean} propertyValue [是否取屬性]
* @param {Object} mapPath */
var pm = new ParserModel();
pm.setEnd(end);
// 如果有「$」符號就表示不是值
pm.setSingleValue(!(ele.indexOf(DOLLLLAR) >= 0)); ;
//去掉"$"
listEle.push(ele);
}
// 開始達到第二步-------------------------------------
/**
* 以對應的解析模型轉換為對應的解釋器物件
]

 Javascript et le web: fonctionnalité de base et cas d'utilisationApr 18, 2025 am 12:19 AM
Javascript et le web: fonctionnalité de base et cas d'utilisationApr 18, 2025 am 12:19 AMLes principales utilisations de JavaScript dans le développement Web incluent l'interaction client, la vérification du formulaire et la communication asynchrone. 1) Mise à jour du contenu dynamique et interaction utilisateur via les opérations DOM; 2) La vérification du client est effectuée avant que l'utilisateur ne soumette les données pour améliorer l'expérience utilisateur; 3) La communication de rafraîchissement avec le serveur est réalisée via la technologie AJAX.
 Comprendre le moteur JavaScript: détails de l'implémentationApr 17, 2025 am 12:05 AM
Comprendre le moteur JavaScript: détails de l'implémentationApr 17, 2025 am 12:05 AMComprendre le fonctionnement du moteur JavaScript en interne est important pour les développeurs car il aide à écrire du code plus efficace et à comprendre les goulots d'étranglement des performances et les stratégies d'optimisation. 1) Le flux de travail du moteur comprend trois étapes: analyse, compilation et exécution; 2) Pendant le processus d'exécution, le moteur effectuera une optimisation dynamique, comme le cache en ligne et les classes cachées; 3) Les meilleures pratiques comprennent l'évitement des variables globales, l'optimisation des boucles, l'utilisation de const et de locations et d'éviter une utilisation excessive des fermetures.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisationApr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisationApr 16, 2025 am 12:12 AMPython convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
 Python vs JavaScript: communauté, bibliothèques et ressourcesApr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressourcesApr 15, 2025 am 12:16 AMPython et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 De C / C à JavaScript: comment tout cela fonctionneApr 14, 2025 am 12:05 AM
De C / C à JavaScript: comment tout cela fonctionneApr 14, 2025 am 12:05 AMLe passage de C / C à JavaScript nécessite de s'adapter à la frappe dynamique, à la collecte des ordures et à la programmation asynchrone. 1) C / C est un langage dactylographié statiquement qui nécessite une gestion manuelle de la mémoire, tandis que JavaScript est dynamiquement typé et que la collecte des déchets est automatiquement traitée. 2) C / C doit être compilé en code machine, tandis que JavaScript est une langue interprétée. 3) JavaScript introduit des concepts tels que les fermetures, les chaînes de prototypes et la promesse, ce qui améliore la flexibilité et les capacités de programmation asynchrones.
 Moteurs JavaScript: comparaison des implémentationsApr 13, 2025 am 12:05 AM
Moteurs JavaScript: comparaison des implémentationsApr 13, 2025 am 12:05 AMDifférents moteurs JavaScript ont des effets différents lors de l'analyse et de l'exécution du code JavaScript, car les principes d'implémentation et les stratégies d'optimisation de chaque moteur diffèrent. 1. Analyse lexicale: convertir le code source en unité lexicale. 2. Analyse de la grammaire: générer un arbre de syntaxe abstrait. 3. Optimisation et compilation: générer du code machine via le compilateur JIT. 4. Exécuter: Exécutez le code machine. Le moteur V8 optimise grâce à une compilation instantanée et à une classe cachée, SpiderMonkey utilise un système d'inférence de type, résultant en différentes performances de performances sur le même code.
 Au-delà du navigateur: Javascript dans le monde réelApr 12, 2025 am 12:06 AM
Au-delà du navigateur: Javascript dans le monde réelApr 12, 2025 am 12:06 AMLes applications de JavaScript dans le monde réel incluent la programmation côté serveur, le développement des applications mobiles et le contrôle de l'Internet des objets: 1. La programmation côté serveur est réalisée via Node.js, adaptée au traitement de demande élevé simultané. 2. Le développement d'applications mobiles est effectué par le reactnatif et prend en charge le déploiement multiplateforme. 3. Utilisé pour le contrôle des périphériques IoT via la bibliothèque Johnny-Five, adapté à l'interaction matérielle.
 Construire une application SaaS multi-locataire avec next.js (intégration backend)Apr 11, 2025 am 08:23 AM
Construire une application SaaS multi-locataire avec next.js (intégration backend)Apr 11, 2025 am 08:23 AMJ'ai construit une application SAAS multi-locataire fonctionnelle (une application EdTech) avec votre outil technologique quotidien et vous pouvez faire de même. Premièrement, qu'est-ce qu'une application SaaS multi-locataire? Les applications saas multi-locataires vous permettent de servir plusieurs clients à partir d'un chant


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

Version Mac de WebStorm
Outils de développement JavaScript utiles

Dreamweaver Mac
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

