



想尝试爬下北邮人的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。
回复内容:
今天偶然发现了PyV8这个东西,感觉就是你想要的。它直接搭建了一个js运行环境,这意味着你可以直接在python里面执行页面上的js代码来获取你需要的内容。
参考:
http://www.silverna.org/blog/?p=252
https://code.google.com/p/pyv8/ 我是直接看js源码,分析完,然后爬的。
例如看页面是用Ajax请求一个JSON文件,我就先爬那个页面,获取Ajax所需的参数,然后直接请求JSON页,然后解码,再处理数据并入库。
如果你直接运行页面上所有js(就像浏览器做的那样),然后获取最终的HTML DOM树,这样的性能非常地糟糕,不建议使用这样的方法。因为Python和js性能本身都很差,如果这样做,会消耗大量CPU资源并且最终只能获得极低的抓取效率。 js代码是需要js引擎运行的,Python只能通过HTTP请求获取到HTML、CSS、JS原始代码而已。
不知道有没有用Python编写的JS引擎,估计需求不大。
我一般用PhantomJS、CasperJS这些引擎来做浏览器抓取。
直接在其中写JS代码来做DOM操控、分析,以文件方式输出结果。
让Python去调用该程序,通过读文件方式获得内容。 去年还真爬过这样的数据,因为赶时间,我的方法就比较丑陋了。
PyQt有一个具体的库来模拟浏览器请求和行为(好像是webkit,忘记了,查一下就好。使用时就几行代码就够了),在一次运行程序中,第一次(只有第一次)的返回结果是js运行之后的代码。于是写了一个py脚本做一次访问解析,然后再写了windows脚本通过传递命令行参数循环这个py脚本,最后搞到数据。
方法dirty了些,不过数据拿到了就好~ 针对某网站的,可以自己看网络请求找到返回实际内容的那些有针对性地发。如果是通用的,得用 headless browser 了,比如 PhantomJS。 又一个爬北邮人论坛的。。
文艺的方法,上浏览器引擎,比如 PhantomJS ,用它导出 html,再对html用 python 解析。千万别直接 PhantomJS 解析,虽然我知道这很容易,为什么?
普通的方法,分析 AJAX 请求。即使它是 JS 渲染的,数据还是通过 HTTP 协议传输的。什么?你模拟不出来?
X-Requested-With:XMLHttpRequest
这里举个栗子:拉勾网的职位列表
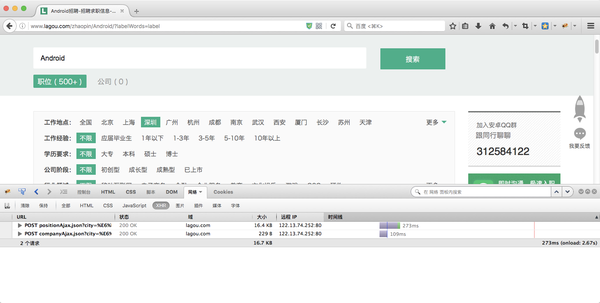

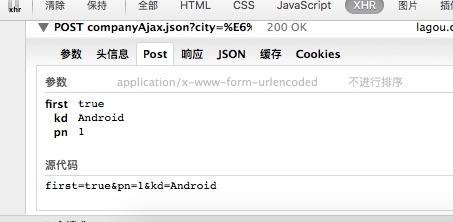
点击了Android之后 我们从浏览器上传了几个参数到拉勾的服务器
一个是 first =true, 一个是kd = android, (关键字) 一个是pn =1 (page number 页码)
所以我们就可以模仿这一个步骤来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这是一个很久以前的问题,题主似乎也已经解决的这个问题。但是看到好多答案的办法有点太重了,这里分享一个效率更优、资源占用更低的方法。由于题主并没有指明需要什么,这里的示例取首页所有帖子的链接和标题。首先请一定记住,浏览器环境对内存和CPU的消耗都非常严重,模拟浏览器环境的爬虫代码要尽可能避免。请记住,对于一些前端渲染的网页,虽然在HTML源码中看不到我们需要的数据,但是更大的可能是它会通过另一个请求拿到纯数据(很大可能以JSON格式存在),我们不但不需要模拟浏览器,反而可以省去解析HTML的消耗。
然后,打开北邮人论坛的首页,发现它的首页HTML源码中确实没有页面所显示文章的内容,那么,很可能这是通过JS异步加载到页面的。通过浏览器开发工具(Chrome浏览器在OS X下通过command+option+i或Win/Linux下通过F12)分析在加载首页的时候请求,容易发现,如下截图中的请求:
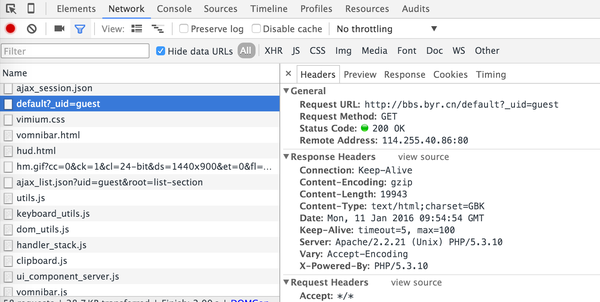 截图中选中的请求得到的response即是首页的文章链接,在preview选项中可以看到渲染后的预览图:
截图中选中的请求得到的response即是首页的文章链接,在preview选项中可以看到渲染后的预览图: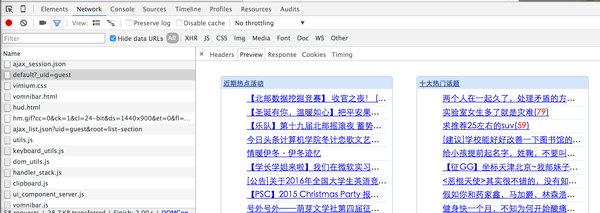 至此,我们确定这个链接可以拿到首页的文章及链接。
至此,我们确定这个链接可以拿到首页的文章及链接。在headers选项中,有这次请求的请求头及请求参数,我们通过Python模拟这次请求,即可拿到相同的响应。再配合BeautifulSoup等库解析HTML,即可得到相应的内容了。
对于如何模拟请求和如何解析HTML,请移步我的专栏,有详细的介绍,这里便不再赘述。
通过这样的方式可以不用模拟浏览器环境来抓取数据,对内存和CPU消耗、抓取速度都有很大的提升。在编写爬虫的时候,请务必记得,如非必要,不要模拟浏览器环境。 如果是在windows下,可以尝试调用windows系统中的webbrowser控件。另外ie本身也提供了接口。不过这两种方式都要渲染页面,性能上多少有点浪费,为了加快速度可以把ie的图片下载显示关闭掉,然后通过click等方法来模拟真实行为。 Google Phantom JS

 Python and Time: Making the Most of Your Study TimeApr 14, 2025 am 12:02 AM
Python and Time: Making the Most of Your Study TimeApr 14, 2025 am 12:02 AMTo maximize the efficiency of learning Python in a limited time, you can use Python's datetime, time, and schedule modules. 1. The datetime module is used to record and plan learning time. 2. The time module helps to set study and rest time. 3. The schedule module automatically arranges weekly learning tasks.
 Python: Games, GUIs, and MoreApr 13, 2025 am 12:14 AM
Python: Games, GUIs, and MoreApr 13, 2025 am 12:14 AMPython excels in gaming and GUI development. 1) Game development uses Pygame, providing drawing, audio and other functions, which are suitable for creating 2D games. 2) GUI development can choose Tkinter or PyQt. Tkinter is simple and easy to use, PyQt has rich functions and is suitable for professional development.
 Python vs. C : Applications and Use Cases ComparedApr 12, 2025 am 12:01 AM
Python vs. C : Applications and Use Cases ComparedApr 12, 2025 am 12:01 AMPython is suitable for data science, web development and automation tasks, while C is suitable for system programming, game development and embedded systems. Python is known for its simplicity and powerful ecosystem, while C is known for its high performance and underlying control capabilities.
 The 2-Hour Python Plan: A Realistic ApproachApr 11, 2025 am 12:04 AM
The 2-Hour Python Plan: A Realistic ApproachApr 11, 2025 am 12:04 AMYou can learn basic programming concepts and skills of Python within 2 hours. 1. Learn variables and data types, 2. Master control flow (conditional statements and loops), 3. Understand the definition and use of functions, 4. Quickly get started with Python programming through simple examples and code snippets.
 Python: Exploring Its Primary ApplicationsApr 10, 2025 am 09:41 AM
Python: Exploring Its Primary ApplicationsApr 10, 2025 am 09:41 AMPython is widely used in the fields of web development, data science, machine learning, automation and scripting. 1) In web development, Django and Flask frameworks simplify the development process. 2) In the fields of data science and machine learning, NumPy, Pandas, Scikit-learn and TensorFlow libraries provide strong support. 3) In terms of automation and scripting, Python is suitable for tasks such as automated testing and system management.
 How Much Python Can You Learn in 2 Hours?Apr 09, 2025 pm 04:33 PM
How Much Python Can You Learn in 2 Hours?Apr 09, 2025 pm 04:33 PMYou can learn the basics of Python within two hours. 1. Learn variables and data types, 2. Master control structures such as if statements and loops, 3. Understand the definition and use of functions. These will help you start writing simple Python programs.
 How to teach computer novice programming basics in project and problem-driven methods within 10 hours?Apr 02, 2025 am 07:18 AM
How to teach computer novice programming basics in project and problem-driven methods within 10 hours?Apr 02, 2025 am 07:18 AMHow to teach computer novice programming basics within 10 hours? If you only have 10 hours to teach computer novice some programming knowledge, what would you choose to teach...
 How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?Apr 02, 2025 am 07:15 AM
How to avoid being detected by the browser when using Fiddler Everywhere for man-in-the-middle reading?Apr 02, 2025 am 07:15 AMHow to avoid being detected when using FiddlerEverywhere for man-in-the-middle readings When you use FiddlerEverywhere...


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

