
Home >Backend Development >Python Tutorial >为什么scrapy没法爬中纪委网站?
为什么scrapy没法爬中纪委网站?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-06-06 16:11:091852browse
回复内容:
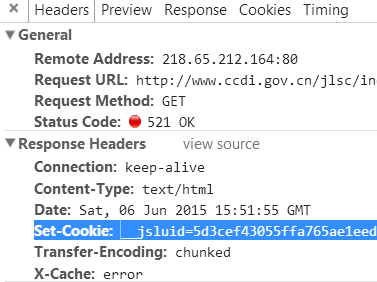
 无论是什么设备,第一次访问该站,都会弹出一个521的错误状态码,与此同时还会返回一个Cookie。
无论是什么设备,第一次访问该站,都会弹出一个521的错误状态码,与此同时还会返回一个Cookie。浏览器接受到状态码与Cookie,会再次进行一次请求,因为接收到了Set-Cookie,所以第二次的Request Headers会附上之前接收到的Cookie。
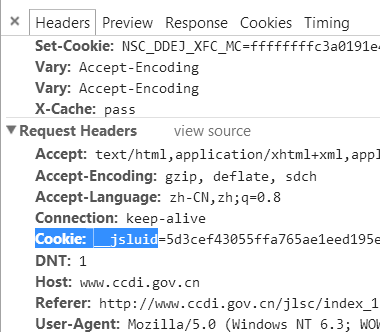 这样的请求才是成功的。
这样的请求才是成功的。这个防爬虫的方法非常基础,利用了普通爬虫与浏览器对于Status Code的处理方式不同。
你要爬取,只需要先请求一次,获得一个Cookie并保存,然后之后所有的请求都附上这个保存下来的Cookie,这样就行了。
爬虫的要诀在于:尽力模仿用户使用浏览器的行为。 想了一会儿要不要回答,因为题目被贴上了作死标签……╭(°A°`)╮
---------------------------------------------------------------
Chrome大法好,Python大法好。
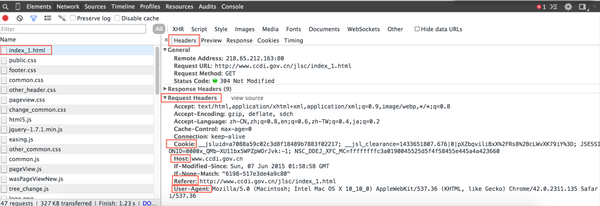
@林灿斌 说的方法没错,不过一般这种网站的Cookie生效时间都比较长,所以你直接复制你Request Headers中的Cookie值,放到你模拟post请求的包中就可以了。你自己在浏览器里打开该网址,然后查看Request Headers中的内容。针对各种反抓取机制,主要有以下几种:
1、Cookie:这个不用多说,你把你的Cookie记下来就好,还可以解决一串需要模拟登陆才能抓取的网站,比如微博之类的;
2、Host:这个不用多说,带上就好,不会变;
3、Referer:有些网站比较变态不仅会检查你是否带Referer信息还会检查你的Referer是否合法,这儿就不点名了,怕被查水表;
4、User-Agent:这里面就是你用户使用环境的一些信息,如浏览器和操作系统,尽可能带上。最好是自己有一个UA表,每次构造请求的时候,随机采用一条UA信息。
除此之外,最重要的就是在IP上下工夫。
1、伪造X-forwarded-for头:这是最容易伪造IP的一个方法,当然也最容易被识破;
2、使用TCP包注入:这个方法被Scrapy封装起来了,具体可以查相关文档,比如还可以借此实现伪造IP源进行SYN FLOOD拒绝服务攻击(好像走偏了……);
3、使用代理IP池:这是最靠谱的做法,缺点就是代理IP的质量常常参差不齐,所以还需要写一个脚本来维护这个代理IP池,比如要获取新的代理IP以及剔除库中无效的IP(我一般就挨个拿来尝试能否访问百度)。
如果你抓取的内容是通过AJAX获得的,那么你的任务就是找到那条JS发出去的请求,按以上套路模拟之即可。 祭出神器
http://jeanphix.me/Ghost.py/ 爬虫是蛀虫,害怕中纪委,不敢爬中纪委的网站。 这种页数不太多的建议自己写爬虫,比直接用scrapy灵活性强一些。这种内容并不是很多的页面用bs4/re+requests+gevent/threading已经可以随意抓了,我始终觉得爬虫难在爬下来的东西要怎么处理。
不知道页面是怎么跳的时候祭出神器Wireshark。
Statement:
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
Previous article:Python 有哪些入门学习方法和值得推荐的经典教材?Next article:我33岁半,立志做个厉害的黑客,有可能实现吗?