

 Technology peripheralsAILLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
Technology peripheralsAILLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
Written before&The author’s personal understanding
This paper is dedicated to solving the key problems of current multi-modal large language models (MLLMs) in autonomous driving applications The challenge is to extend MLLMs from 2D understanding to the problem of 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment.
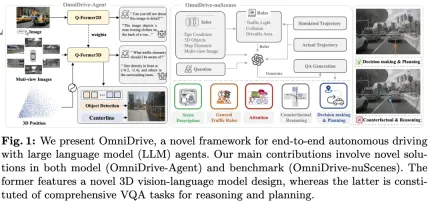
Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (for example) due to the visual encoder The resolution limit and the LLM sequence length limit. However, autonomous driving applications require high-resolution multi-view video input to ensure that vehicles can perceive the environment and make safe decisions over long distances. Furthermore, many existing 2D model architectures struggle to efficiently handle these inputs because they require extensive computing and storage resources. To address these issues, researchers are working to develop new model architectures and storage resources.
In this context, this article proposes a new 3D MLLM architecture, drawing on Q-Former style design. The architecture employs a cross-attention decoder to compress high-resolution visual information into sparse queries, making it easier to scale to high-resolution inputs. This architecture has similarities with families of perspective models such as DETR3D, PETR(v2), StreamPETR, and Far3D, as they all leverage sparse 3D query mechanisms. By appending 3D positional encoding to these queries and interacting with multi-view input, our architecture achieves 3D spatial understanding and thereby better leverages pre-trained knowledge in 2D images.
In addition to the innovation of model architecture, this article also proposes a more challenging benchmark-OmniDrive-nuScenes. The benchmark covers a range of complex tasks requiring 3D spatial understanding and long-range reasoning, and introduces a counterfactual reasoning benchmark to evaluate results by simulating solutions and trajectories. This benchmark effectively makes up for the problem of biasing towards a single expert trajectory in current open-ended evaluations, thus avoiding overfitting on expert trajectories.
This article introduces OmniDrive, a comprehensive end-to-end autonomous driving framework, which provides an effective 3D reasoning and planning model based on LLM-agent and builds a more challenging benchmark, promoting further development in the field of autonomous driving. The specific contributions are as follows:
- Proposed a 3D Q-Former architecture, which is suitable for various driving-related tasks, including target detection, lane detection, 3D visual positioning, and decision making and planning.
- Introducing the OmniDrive-nuScenes benchmark, the first QA benchmark designed to address planning-related challenges, covering accurate 3D spatial information.
- Achieved the best performance on planning tasks.
Detailed explanation of OmniDrive
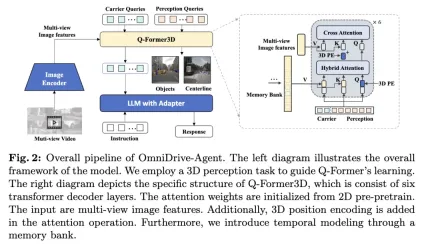
##Overall structure
The OmniDrive proposed in this article -Agent combines the advantages of Q-Former and query-based 3D perception models to efficiently obtain 3D spatial information from multi-view image features and solve 3D perception and planning tasks in autonomous driving. The overall architecture is shown in the figure.- Visual Encoder: First, a shared visual encoder is used to extract multi-view image features.
- Position encoding : Input the extracted image features and position encoding into Q-Former3D.
- Q-Former3D module: Among them, represents the splicing operation. For the sake of brevity, positional encoding is omitted from the formula. After this step, the query collection becomes the interactive . Among them, represents 3D position coding, and is a multi-view image feature.
- Multi-view image feature collection: Next, these queries collect information from multi-view images:
- Query initialization and automatic Attention: In Q-Former3D, initialize the detection query and carrier query, and perform self-attention operations to exchange information between them:
- Output processing :
- Perceptual task prediction : Predict the category and coordinates of foreground elements using perceptual queries.
- Carrier query alignment and text generation: The carrier query is aligned to the dimensions of the LLM token (such as the 4096 dimension in LLaMA) through a single-layer MLP, and is further used for text generation.
- The role of carrier query
Multi-task and Temporal Modeling
The author’s method benefits from multi-task learning and temporal modeling. In multi-task learning, the author can integrate specific Q-Former3D modules for each perception task and adopt a unified initialization strategy (see \cref{Training Strategy}). In different tasks, carrier queries can collect information about different traffic elements. The author's implementation covers tasks such as centerline construction and 3D object detection. During training and inference phases, these modules share the same 3D position encoding. Our method enriches tasks such as centerline construction and 3D object detection. During training and inference phases, these modules share the same 3D position encoding. Our method enriches tasks such as centerline construction and 3D object detection. During training and inference phases, these modules share the same 3D position encoding.
Regarding temporal modeling, the authors store perceptual queries with top-k classification scores in the memory bank and propagate them frame by frame. The propagated query interacts with the perceptual query and carrier query of the current frame through cross-attention, thereby extending the model's processing capabilities for video input.
Training Strategy
The training strategy of OmniDrive-Agent is divided into two stages: 2D pre-training and 3D fine-tuning. In the initial stage, the authors first pre-trained multi-modal large models (MLLMs) on 2D image tasks to initialize Q-Former and vector queries. After removing the detection query, the OmniDrive model can be regarded as a standard visual language model, capable of generating text based on images. Therefore, the author used the training strategy and data of LLaVA v1.5 to pre-train OmniDrive on 558K image and text pairs. During pre-training, all parameters remain frozen except Q-Former. Subsequently, the MLLMs were fine-tuned using the instruction tuning dataset of LLaVA v1.5. During fine-tuning, the image encoder remains frozen and other parameters can be trained.
In the 3D fine-tuning stage, the goal is to enhance the 3D positioning capabilities of the model while retaining its 2D semantic understanding capabilities as much as possible. To this end, the author added 3D position encoding and timing modules to the original Q-Former. At this stage, the author uses LoRA technology to fine-tune the visual encoder and large language model with a small learning rate, and train Q-Former3D with a relatively large learning rate. In these two stages, OmniDrive-Agent’s loss calculation only includes the text generation loss, without considering the contrastive learning and matching losses in BLIP-2.
OmniDrive-nuScenes

#To benchmark driving multi-modal large model agents, the authors proposed OmniDrive-nuScenes, This is a novel benchmark based on the nuScenes dataset, containing high-quality visual question answering (QA) pairs covering perception, reasoning and planning tasks in the 3D domain.
The highlight of OmniDrive-nuScenes is its fully automated QA generation process, which uses GPT-4 to generate questions and answers. Similar to LLaVA, our pipeline provides 3D-aware annotations as contextual information to GPT-4. On this basis, the author further uses traffic rules and planning simulation as additional input to help GPT-4 better understand the 3D environment. The author's benchmark not only tests the model's perception and reasoning capabilities, but also challenges the model's real spatial understanding and planning capabilities in 3D space through long-term problems involving attention, counterfactual reasoning, and open-loop planning, as these problems require Driving planning in the next few seconds is simulated to arrive at the correct answer.
In addition to the generation process for offline question and answer, the author also proposes a process for online generation of diverse positioning questions. This process can be seen as an implicit data enhancement method to improve the model's 3D spatial understanding and reasoning capabilities.
Offline Question-Answering
In the offline QA generation process, the author uses contextual information to generate QA pairs on nuScenes. First, the author uses GPT-4 to generate a scene description, and splices the three-perspective front view and the three-perspective rear view into two independent images and inputs them into GPT-4. Through prompt input, GPT-4 can describe information such as weather, time, scene type, etc., and identify the direction of each viewing angle. At the same time, it avoids description by viewing angle, but describes the content relative to the position of the own vehicle.
Next, in order for GPT-4V to better understand the relative spatial relationship between traffic elements, the author represents the relationship between objects and lane lines into a file tree-like structure, and based on the 3D bounding box of the object , convert its information into natural language description.
The author then generated trajectories by simulating different driving intentions, including lane keeping, left lane changing, and right lane changing, and used a depth-first search algorithm to connect the lane center lines to generate all possible driving path. In addition, the author clustered the self-vehicle trajectories in the nuScenes data set, selected representative driving paths, and used them as part of the simulated trajectory.
Ultimately, by combining different contextual information in the offline QA generation process, the authors are able to generate multiple types of QA pairs, including scene description, attention object recognition, counterfactual reasoning, and decision planning. GPT-4 can identify threat objects based on simulations and expert trajectories, and give reasonable driving suggestions by reasoning about the safety of the driving path.

Online Question-Answering
In order to make full use of the 3D perceptual annotation in the autonomous driving data set, the author uses online method to generate a large number of positioning tasks. These tasks are designed to enhance the model's 3D spatial understanding and reasoning capabilities, including:
- 2D to 3D localization: Given a 2D bounding box on a specific camera, the model needs to provide a corresponding 3D properties of objects, including category, position, size, orientation and speed.
- 3D distance: Based on randomly generated 3D coordinates, identify traffic elements near the target location and provide their 3D attributes.
- Lane to Object: Based on a randomly selected lane centerline, list all objects on that lane and their 3D properties.
Metrics
The OmniDrive-nuScenes dataset involves scene description, open-loop planning and counterfactual reasoning tasks. Each task focuses on different aspects, making it difficult to evaluate using a single metric. Therefore, the authors designed different evaluation criteria for different tasks.
For scene description related tasks (such as scene description and attention object selection), the author uses commonly used language evaluation indicators, including METEOR, ROUGE and CIDEr to evaluate sentence similarity. In the open-loop planning task, the authors used collision rates and road boundary crossing rates to evaluate the performance of the model. For the counterfactual reasoning task, the authors use GPT-3.5 to extract keywords in predictions and compare these keywords with the ground truth to calculate precision and recall for different accident categories.
Experimental results
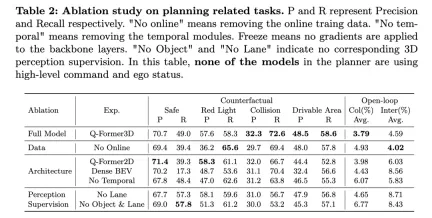
#The above table shows the results of ablation research on planning-related tasks, including counterfactual reasoning and open-loop planning performance evaluation.
The full model, Q-Former3D, performs well on both counterfactual reasoning and open-loop planning tasks. In the counterfactual reasoning task, the model demonstrated high precision and recall rates in both the "red light violation" and "accessible area violation" categories, which were 57.6%/58.3% and 48.5%/58.6% respectively. At the same time, the model achieved the highest recall rate (72.6%) in the "collision" category. In the open-loop planning task, Q-Former3D performed well in both the average collision rate and road boundary intersection rate, reaching 3.79% and 4.59% respectively.
After removing the online training data (No Online), the recall rate of the "red light violation" category in the counterfactual reasoning task increased (65.6%), but the overall performance decreased slightly. The precision rate and recall rate of collisions and passable area violations are slightly lower than those of the complete model, while the average collision rate of the open-loop planning task increased to 4.93%, and the average road boundary crossing rate dropped to 4.02%, which reflects the importance of online training data to The importance of improving the overall planning performance of the model.
In the architecture ablation experiment, the Q-Former2D version achieved the highest precision (58.3%) and high recall (61.1%) on the "red light violation" category, but the performance of other categories was not as good as the full model , especially the recall rates for the “collision” and “accessible area violation” categories dropped significantly. In the open-loop planning task, the average collision rate and road boundary intersection rate are higher than the full model, 3.98% and 6.03% respectively.
The model using Dense BEV architecture performs better on all categories of counterfactual reasoning tasks, but the overall recall rate is low. The average collision rate and road boundary intersection rate in the open-loop planning task reached 4.43% and 8.56% respectively.
When the temporal module is removed (No Temporal), the model's performance in the counterfactual reasoning task drops significantly, especially the average collision rate increases to 6.07% and the road boundary crossing rate reaches 5.83%.
In terms of perceptual supervision, after removing lane line supervision (No Lane), the recall rate of the model in the "collision" category dropped significantly, while the index performance of other categories of counterfactual reasoning tasks and open-loop planning tasks relatively stable. After completely removing the 3D perception supervision of objects and lane lines (No Object & Lane), the precision rate and recall rate of each category of the counterfactual reasoning task decreased, especially the recall rate of the "collision" category dropped to 53.2%. The average collision rate and road boundary intersection rate in the open-loop planning task increased to 6.77% and 8.43% respectively, which were significantly higher than the full model.
It can be seen from the above experimental results that the complete model performs well in counterfactual reasoning and open-loop planning tasks. Online training data, time modules, and 3D perception supervision of lane lines and objects play an important role in improving model performance. The complete model can effectively utilize multi-modal information for efficient planning and decision-making, and the results of the ablation experiment further verify the key role of these components in autonomous driving tasks.
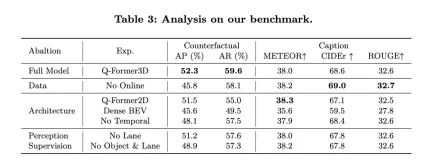
At the same time, let’s look at the performance of NuScenes-QA: it demonstrates the performance of OmniDrive in open-loop planning tasks and compares it with other existing methods. The results show that OmniDrive (full version) achieves the best performance in all indicators, especially in the average error of open-loop planning, collision rate and road boundary intersection rate, which is better than other methods.
Performance of OmniDrive: The OmniDrive model has L2 average errors of 0.14, 0.29 and 0.55 meters in the prediction time of 1 second, 2 seconds and 3 seconds respectively, and the final average error is only 0.33 rice. In addition, the average collision rate and average road boundary intersection rate of this model also reached 0.30% and 3.00% respectively, which are much lower than other methods. Especially in terms of collision rate, OmniDrive achieved zero collision rate in both the 1 second and 2 second prediction time periods, fully demonstrating its excellent planning and obstacle avoidance capabilities.
Comparison with other methods: Compared with other advanced benchmark models, such as UniAD, BEV-Planner and Ego-MLP, OmniDrive outperforms on all key metrics. UniAD's L2 average error is 0.46 meters when using high-level commands and self-vehicle status information, while OmniDrive's error is even lower at 0.33 meters under the same settings. At the same time, OmniDrive's collision rate and road boundary intersection rate are also significantly lower than UniAD, especially the collision rate which is reduced by nearly half.
Compared with BEV-Planner, OmniDrive’s L2 error in all prediction time periods is significantly reduced, especially in the 3-second prediction time period, the error is reduced from 0.57 meters to 0.55 meters. At the same time, OmniDrive is also better than BEV-Planner in terms of collision rate and road boundary crossing rate. The collision rate dropped from 0.34% to 0.30%, and the road boundary crossing rate dropped from 3.16% to 3.00%.
Ablation experiment: In order to further evaluate the impact of key modules in the OmniDrive architecture on performance, the author also compared the performance of different versions of the OmniDrive model. OmniDrive (which does not use high-level commands and self-vehicle status information) is significantly inferior to the complete model in terms of prediction error, collision rate and road boundary intersection rate, especially the L2 error in the 3-second prediction period reaching 2.84 meters, with an average The collision rate is as high as 3.79%.
When only using the OmniDrive model (without high-level commands and self-vehicle status information), the prediction error, collision rate and road boundary intersection rate have improved, but there is still a gap compared with the complete model. This shows that integrating high-level commands and self-vehicle status information has a significant effect on improving the overall planning performance of the model.
Overall, the experimental results clearly demonstrate the excellent performance of OmniDrive on open-loop planning tasks. By integrating multi-modal information, high-level commands and self-vehicle status information, OmniDrive achieves more accurate path prediction and lower collision rate and road boundary intersection rate in complex planning tasks, providing information for autonomous driving planning and decision-making. strong support.
Discussion

The OmniDrive agent and OmniDrive-nuScenes dataset proposed by the author introduce a new method in the field of multi-modal large models. A new paradigm capable of solving driving problems in 3D environments and providing a comprehensive benchmark for the evaluation of such models. However, each new method and data set has its strengths and weaknesses.
The OmniDrive agent proposes a two-stage training strategy: 2D pre-training and 3D fine-tuning. In the 2D pre-training stage, better alignment between image features and large language models is achieved by pre-training Q-Former and carrier queries using the image-text paired dataset of LLaVA v1.5. In the 3D fine-tuning stage, 3D position information encoding and time modules are introduced to enhance the 3D positioning capabilities of the model. By leveraging LoRA to fine-tune the visual encoder and language model, OmniDrive maintains understanding of 2D semantics while enhancing its mastery of 3D localization. This staged training strategy fully unleashes the potential of the multi-modal large model, giving it stronger perception, reasoning and planning capabilities in 3D driving scenarios. On the other hand, OmniDrive-nuScenes serves as a new benchmark specifically designed for evaluating the ability to drive large models. Its fully automated QA generation process generates high-quality question-answer pairs via GPT-4, covering different tasks from perception to planning. In addition, the online generated positioning task also provides implicit data enhancement for the model, helping it better understand the 3D environment. The advantage of this dataset is that it not only tests the model's perception and reasoning capabilities, but also evaluates the model's spatial understanding and planning capabilities through long-term problems. This comprehensive benchmark provides strong support for the development of future multi-modal large models.
However, the OmniDrive agent and the OmniDrive-nuScenes dataset also have some shortcomings. First, since the OmniDrive agent needs to fine-tune the entire model in the 3D fine-tuning phase, the training resource requirements are high, which significantly increases training time and hardware costs. In addition, the data generation of OmniDrive-nuScenes completely relies on GPT-4. Although it ensures the quality and diversity of questions, it also causes the generated questions to be more inclined to models with strong natural language capabilities, which may make the model more dependent on benchmark testing. based on language characteristics rather than actual driving ability. Although OmniDrive-nuScenes provides a comprehensive QA benchmark, its coverage of driving scenarios is still limited. The traffic rules and planning simulations involved in the dataset are only based on the nuScenes dataset, which makes it difficult for the generated problems to fully represent various driving scenarios in the real world. Additionally, due to the highly automated nature of the data generation process, generated questions are inevitably affected by data bias and prompt design.
Conclusion
The OmniDrive agent and OmniDrive-nuScenes dataset proposed by the author bring new perspectives and evaluations to multi-modal large model research in 3D driving scenes. benchmark. The OmniDrive agent's two-stage training strategy successfully combines 2D pre-training and 3D fine-tuning, resulting in models that excel in perception, reasoning, and planning. OmniDrive-nuScenes, as a new QA benchmark, provides comprehensive indicators for evaluating large driving models. However, further research is still needed to optimize the training resource requirements of the model, improve the data set generation process, and ensure that the generated questions more accurately represent the real-life driving environment. Overall, the author's method and data set are of great significance in advancing multi-modal large model research in the field of driving, laying a solid foundation for future work.
The above is the detailed content of LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest). For more information, please follow other related articles on the PHP Chinese website!

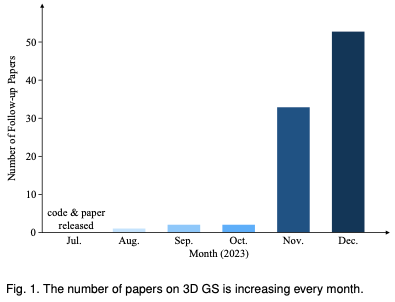 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
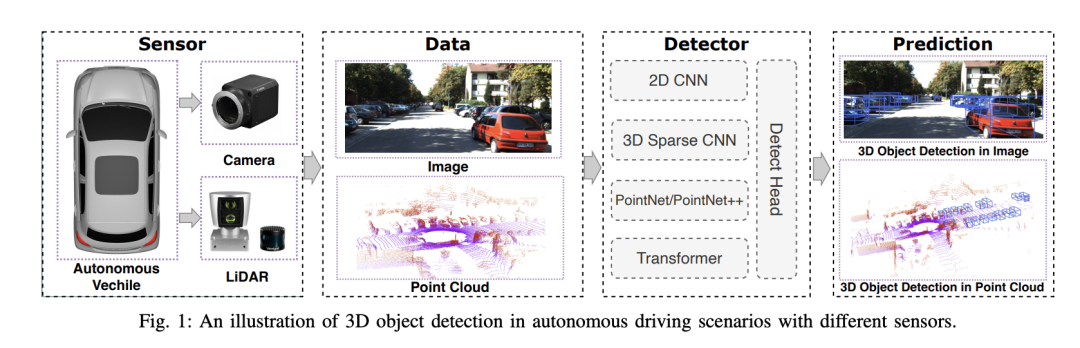 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PMChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
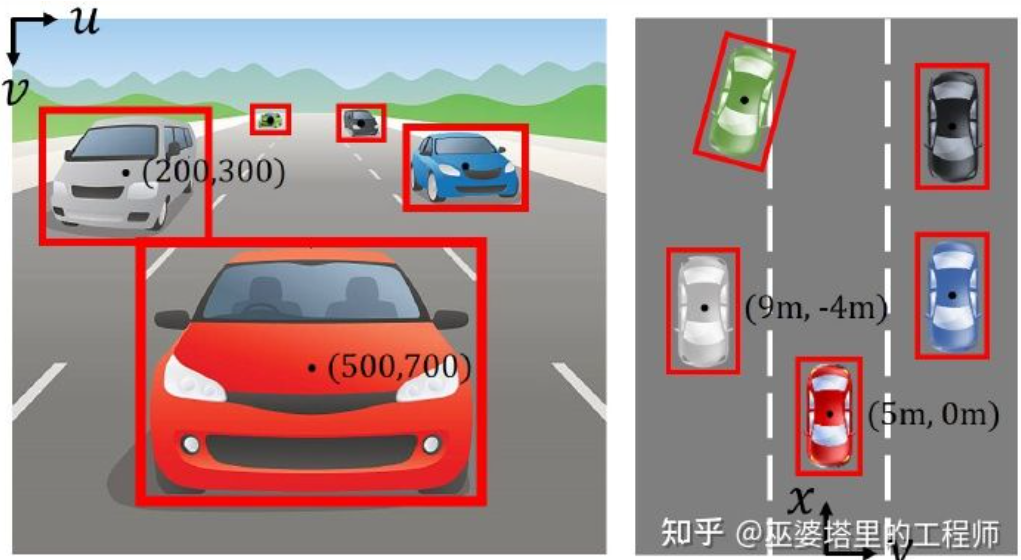 自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
 《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

