
Home >Technology peripherals >AI >Yuanxiang's first multi-modal large model XVERSE-V is open source, refreshing the list of authoritative large models, and supports any aspect ratio input
Yuanxiang's first multi-modal large model XVERSE-V is open source, refreshing the list of authoritative large models, and supports any aspect ratio input

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-04-28 16:43:08815browse
83% of the information humans obtain comes from vision. Large multi-modal models of graphics and text can perceive richer and more accurate real-world information and build more comprehensive cognitive intelligence, thus taking a greater step towards AGI (General Artificial Intelligence). pace.
Yuanxiang today released the multi-modal large model XVERSE-V, which supports image input with any aspect ratio and leads in mainstream evaluations. This model is fully open source and unconditionally free for commercial use , and continues to promote the research and development and application innovation of a large number of small and medium-sized enterprises, researchers and developers.  In MMBench, it surpassed well-known closed source models such as Google GeminiProVision, Ali Qwen-VL-Plus and Claude-3V Sonnet.
In MMBench, it surpassed well-known closed source models such as Google GeminiProVision, Ali Qwen-VL-Plus and Claude-3V Sonnet. 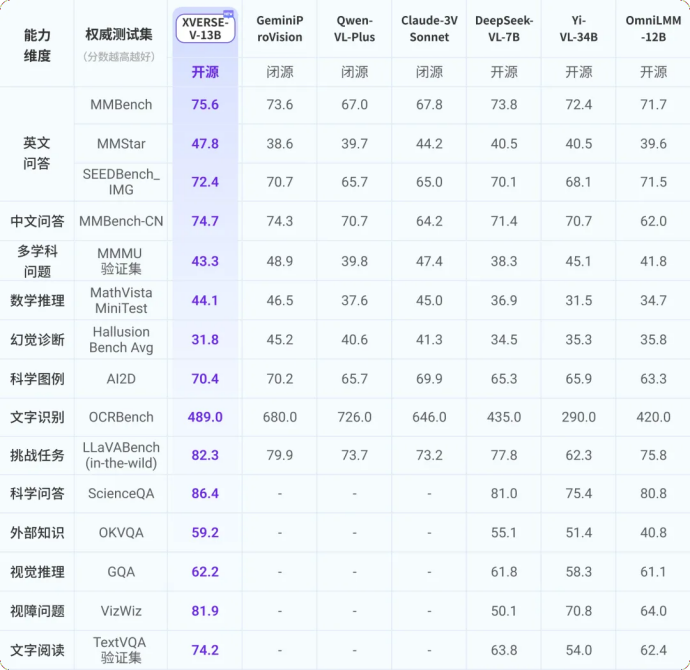 Figure. Comprehensive evaluation of multi-modal large models
Figure. Comprehensive evaluation of multi-modal large models
Fusion of global and local high-definition image representation
The image representation of traditional multi-modal models is only the whole, XVERSE-V innovatively adopts a strategy of fusing the whole and the part, supporting the input of images with any aspect ratio. Taking into account both global overview information and local detailed information, it can identify and analyze subtle features in images, see more clearly, and understand more accurately. 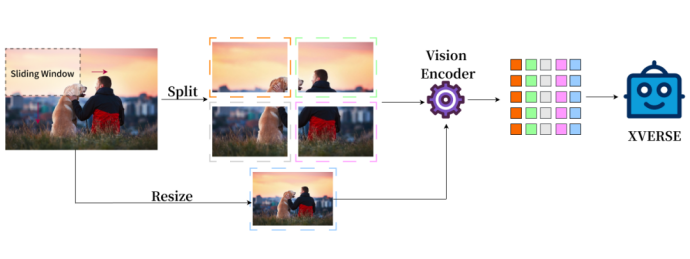
 Note: Concate* means concatenation by column
Note: Concate* means concatenation by column
This processing method allows the model to be applied to a wide range of fields, including panoramic image recognition, satellite images, and ancient cultural relics. Scan analysis, etc.
Example-HD panorama recognition, picture detail text recognition

Free download of large model
•Hugging Face: https ://huggingface.co/xverse/XVERSE-V-13B
•ModelScope: https://modelscope.cn/models/xverse/XVERSE-V-13B
•Github : https://github.com/xverse-ai/XVERSE-V-13B
•For inquiries, please send: opensource@xverse.cn
Yuanxiang continues to build a domestic open source benchmark, in The earliest open source in China with maximum parameters of 65B , The world’s earliest open source with the longest context 256K and International cutting-edge MoE model , and leads the country in SuperCLUE evaluation . The launch of the MoE model this time fills the gap in domestic open source and pushes it to the international leading level.
In terms of commercial application, the Yuanxiang large model is one of the earliest models in Guangdong to obtain national registration , and can provide services to the whole society. Yuanxiang Large Model has been conducting in-depth cooperation and application exploration with a number of Tencent products since last year, including QQ Music , Huya Live, National Karaoke, Tencent Cloud, etc., providing services for the fields of culture, entertainment, tourism, and finance. Create an innovative and leading user experience. 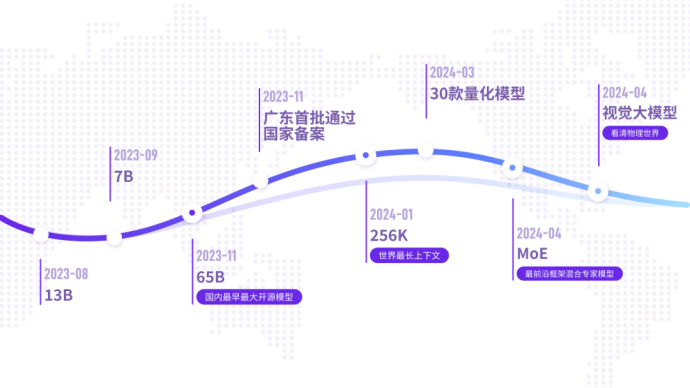
Outstanding performance in multi-directional practical applications
The model not only performs well in basic capabilities, but also performs well in actual application scenarios. Have the ability to understand in different scenarios and be able to handle different needs such as information graphics, documents, real-life scenarios, mathematical questions, scientific documents, code conversion, etc.
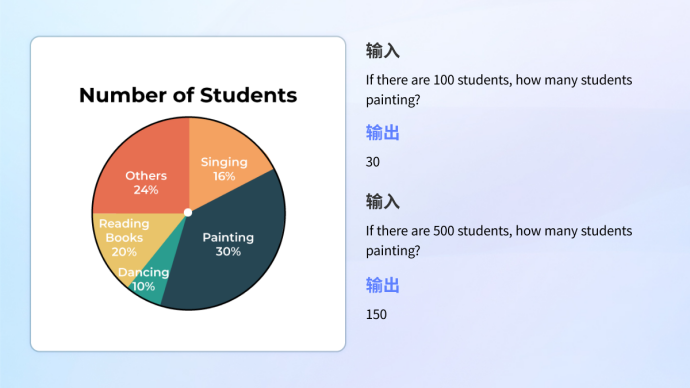
•Chart understanding
Whether it is the understanding of information graphics that combines complex graphics and text, or the analysis and calculation of a single chart, the model can handle it with ease. 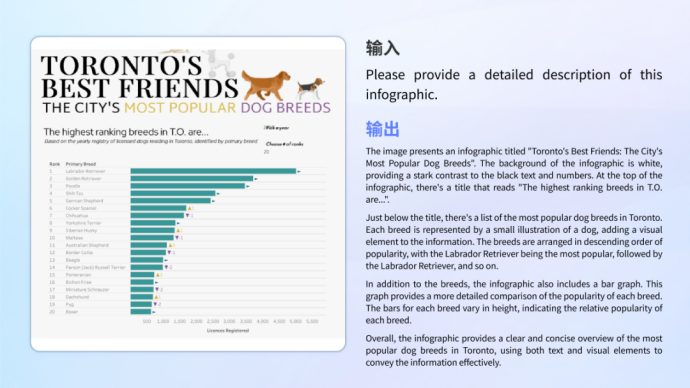
•Visually Impaired Real Scenario
In the real visually impaired scene test set VizWiz, XVERSE-V performed well and surpassed InternVL-Chat -V1.5, DeepSeek-VL-7B and other almost all mainstream open source multi-modal large models. This test set contains more than 31,000 visual questions and answers from real visually impaired users, which can accurately reflect the real needs and trivial problems of users, and help the visually impaired people overcome their daily real visual challenges. 
# Vizwiz test example
# • 内容 内容
# XVVERSE-V At the same time, it maintains strong text generation capabilities and is well qualified for the task of creative text generation after understanding images. 
•Education Problem Solving
The model has a wide range of knowledge reserves and logical reasoning capabilities, and can identify images to answer questions in different disciplines. 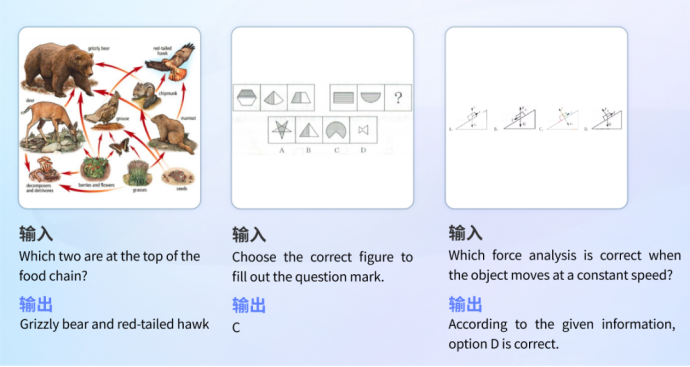
•Encyclopedia Answers
The model stores knowledge on various topics such as history, culture, technology, and security. 
•Code writing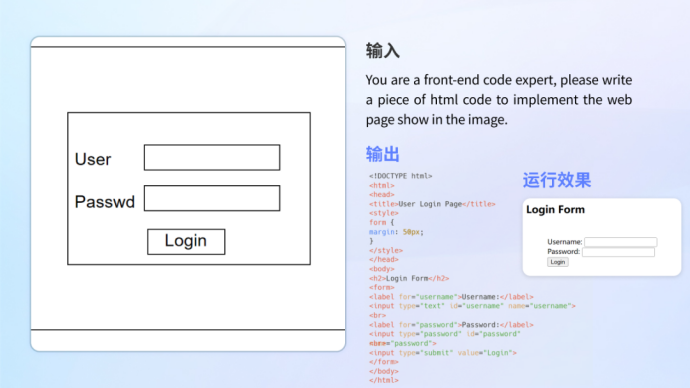
•Autopilot
•Emotion Understanding and Recognition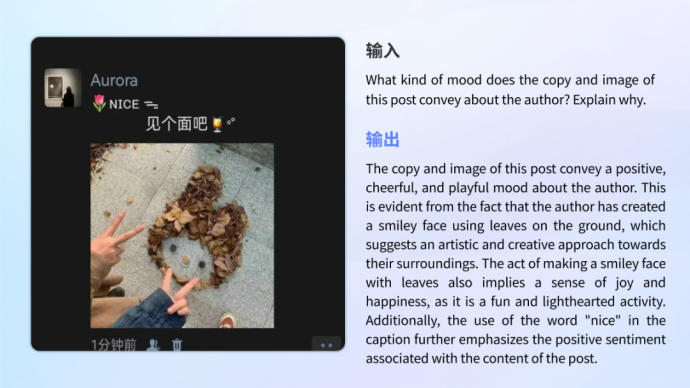
The above is the detailed content of Yuanxiang's first multi-modal large model XVERSE-V is open source, refreshing the list of authoritative large models, and supports any aspect ratio input. For more information, please follow other related articles on the PHP Chinese website!