
 Technology peripheralsAIUnder the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.
Technology peripheralsAIUnder the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.
Recently, led by Professor Yan Shuicheng, the Kunlun Wanwei 2050 Global Research Institute, National University of Singapore, and Nanyang Technological University of Singapore teams jointly released and open sourced itVitron universal pixel-level visual multi-modal large language model.
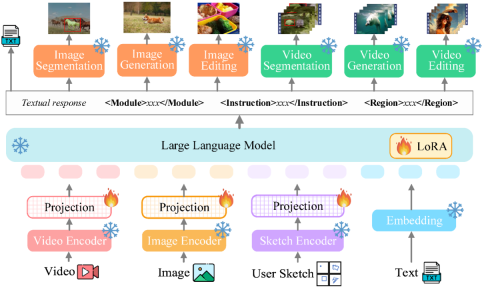
This is a heavy-duty general visual multi-modal model that supports a series of visual tasks from visual understanding to visual generation, from low level to high level, solving problems. The image / long-standing problem in the large language model industry provides a pixel-level pixel-level solution that comprehensively unifies the understanding, generation, segmentation, and editing of static images and dynamic video content. The general vision multi-modal large model lays the foundation for the ultimate form of the next generation general vision large model, and also marks the step towards general artificial intelligence(#AGI)Another big step.
Vitron, as a unified pixel-level visual multi-modal large language model, achieves comprehensive support for visual tasks from low-level to high-level ,Able to handle complex visual tasks, andunderstand and generate image and video content, providing powerful visual understanding and task execution capabilities. At the same time, Vitron supports continuous operations with users, enabling flexible human-computer interaction, demonstrating the great potential towards a more unified visual multi-modal universal model.
Vitron-related papers, codes and Demo have all been made public. They are comprehensive, technological innovation, The unique advantages and potential demonstrated in human-computer interaction and application potential not only promote the development of multi-modal large models, but also provide a new direction for future visual large model research.
Kunlun Wanwei2050 Global Research Institute has always been committed to building a excellent company for the future world Scientific research institutions, together with the scientific communitycross" singularity", Explore the unknown world,create a better future. Previously, Kunlun Wanwei2050 Global Research Institute has released and open sourced the digital agent research and development toolkitAgentStudio, In the future, the institute will continue to promote artificial intelligencetechnical breakthroughs, and contribute to China'sartificial intelligence ecological constructionContribute. The current development of visual large language models (LLMs) has made gratifying progress. The community increasingly believes that building more general and powerful multimodal large models (MLLMs) will be the only way to achieve general artificial intelligence (AGI). However, there are still some key challenges in the process of moving towards a multi-modal general model (Generalist). For example, a large part of the work does not achieve fine-grained pixel-level visual understanding, or lacks unified support for images and videos. Or the support for various visual tasks is insufficient, and it is far from a universal large model.
In order to fill this gap, recently, the Kunlun Worldwide 2050 Global Research Institute, the National University of Singapore, and the Nanyang Technological University of Singapore team jointly released the open source Vitron universal pixel-level visual multi-modal large language model. Vitron supports a series of visual tasks from visual understanding to visual generation, from low level to high level, including comprehensive understanding, generation, segmentation and editing of static images and dynamic video content.
Vitron comprehensively describes the functional support for four major vision-related tasks. and its key advantages. Vitron also supports continuous operation with users to achieve flexible human-machine interaction. This project demonstrates the great potential for a more unified vision multi-modal general model, laying the foundation for the ultimate form of the next generation of general vision large models. Vitron related papers, codes, and demos are now all public.
Vitron related papers, codes, and demos are now all public.
- Paper link: https://is.gd/aGu0VV
- Open source code: https://github.com/SkyworkAI/Vitron
0
. The ultimate unified multi-modal language model In recent years, large language models (LLMs) have demonstrated unprecedented powerful capabilities, and they have been gradually verified as the technical route to AGI. Multimodal large language models (MLLMs) are developing rapidly in many communities and are rapidly emerging. By introducing modules that can perform visual perception, pure language-based LLMs are extended to MLLMs. Many MLLMs that are powerful and excellent in image understanding have been developed. , such as BLIP-2, LLaVA, MiniGPT-4, etc. At the same time, MLLMs focusing on video understanding have also been launched, such as VideoChat, Video-LLaMA, Video-LLaVA, etc. Subsequently, researchers mainly tried to further expand the capabilities of MLLMs from two dimensions. On the one hand, researchers are trying to deepen MLLMs' understanding of vision, transitioning from rough instance-level understanding to pixel-level fine-grained understanding of images, so as to achieve visual region positioning (Regional Grounding) capabilities, such as GLaMM, PixelLM, NExT-Chat and MiniGPT-v2 etc. On the other hand, researchers try to expand the visual functions that MLLMs can support. Some research has begun to study how MLLMs not only understand input visual signals, but also support the generation of output visual content. For example, MLLMs such as GILL and Emu can flexibly generate image content, and GPT4Video and NExT-GPT realize video generation. At present, the artificial intelligence community has gradually reached a consensus that the future trend of visual MLLMs will inevitably develop in the direction of highly unified and stronger capabilities. However, despite the numerous MLLMs developed by the community, a clear gap still exists. The above table simply summarizes the capabilities of existing visual MLLM (only representatively includes some models, and the coverage is incomplete). To bridge these gaps, the team proposes Vitron, a general pixel-level visual MLLM. 02. Vitron system architecture: three key modules Vitron overall framework As shown below. Vitron adopts a similar architecture to existing related MLLMs, including three key parts: 1) front-end visual & language encoding module, 2) central LLM understanding and text generation module, and 3) back-end user response and module calls for visual control module. 03. VitronThree stages of model training Based on the above architecture, Vitron is trained and fine-tuned to give it powerful visual understanding and task execution capabilities. Model training mainly includes three different stages. 1) User response output , directly reply to the user's input. 2) Module name, indicating the function or task to be performed. 3) Call the command to trigger the meta-instruction of the task module. 4) Region (optional output) that specifies fine-grained visual features required for certain tasks, such as in video tracking or visual editing, where backend modules require this information. For regions, based on LLM's pixel-level understanding, a bounding box described by coordinates will be output. 04. Evaluation Experiment Researchers conducted extensive experimental evaluations on 22 common benchmark data sets and 12 image/video vision tasks based on Vitron. Vitron demonstrates strong capabilities in four major visual task groups (segmentation, understanding, content generation and editing), while at the same time it has flexible human-computer interaction capabilities. The following representatively shows some qualitative comparison results: Results of image referring image segmentation Results of image referring expression comprehension. Results on video QA. Image editing results For more detailed experimental content and details, please move here step thesis. 05. Future Directions Overall, this work demonstrates The huge potential of developing a unified visual multi-modal general large model has laid a new form for the research of the next generation of visual large models and taken the first step in this direction. Although the Vitron system proposed by the team shows strong general capabilities, it still has its own limitations. The following researchers list some directions that could be further explored in the future. The Vitron system still uses a semi-joint, semi-agent approach to call external tools. Although this call-based method facilitates the expansion and replacement of potential modules, it also means that the back-end modules of this pipeline structure do not participate in the joint learning of the front-end and LLM core modules. This limitation is not conducive to the overall learning of the system, which means that the performance upper limit of different vision tasks will be limited by the back-end modules. Future work should integrate various vision task modules into a unified unit. Achieving unified understanding and output of images and videos while supporting generation and editing capabilities through a single generative paradigm remains a challenge. Currently, a promising approach is to combine modularity-persistent tokenization to improve the unification of the system on different inputs and outputs and various tasks. Unlike previous models that focused on a single vision task (e.g., Stable Diffusion and SEEM), Vitron aims to facilitate The in-depth interaction between LLM and users is similar to OpenAI’s DALL-E series, Midjourney, etc. in the industry. Achieving optimal user interactivity is one of the core goals of this work. Vitron leverages existing language-based LLMs, combined with appropriate instruction adjustments, to achieve a certain level of interactivity. For example, the system can flexibly respond to any expected message input by the user and produce corresponding visual operation results without requiring the user input to exactly match the back-end module conditions. However, this work still has a lot of room for improvement in terms of enhancing interactivity. For example, drawing inspiration from the closed-source Midjourney system, no matter what decision LLM makes at each step, the system should actively provide feedback to users to ensure that its actions and decisions are consistent with user intentions. Modal capabilities Currently, Vitron integrates a 7B Vicuna model, which may have the ability to understand language, images and videos Certain restrictions will apply. Future exploration directions could be to develop a comprehensive end-to-end system, such as expanding the scale of the model to achieve a more thorough and comprehensive understanding of vision. Furthermore, efforts should be made to enable LLM to fully unify the understanding of image and video modalities.








The above is the detailed content of Under the leadership of Yan Shuicheng, Kunlun Wanwei 2050 Global Research Institute jointly released Vitron with NUS and NTU, establishing the ultimate form of general visual multi-modal large models.. For more information, please follow other related articles on the PHP Chinese website!

 From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AM
From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AMThe legal tech revolution is gaining momentum, pushing legal professionals to actively embrace AI solutions. Passive resistance is no longer a viable option for those aiming to stay competitive. Why is Technology Adoption Crucial? Legal professional
 This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AM
This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AMMany assume interactions with AI are anonymous, a stark contrast to human communication. However, AI actively profiles users during every chat. Every prompt, every word, is analyzed and categorized. Let's explore this critical aspect of the AI revo
 7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AM
7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AMA successful artificial intelligence strategy cannot be separated from strong corporate culture support. As Peter Drucker said, business operations depend on people, and so does the success of artificial intelligence. For organizations that actively embrace artificial intelligence, building a corporate culture that adapts to AI is crucial, and it even determines the success or failure of AI strategies. West Monroe recently released a practical guide to building a thriving AI-friendly corporate culture, and here are some key points: 1. Clarify the success model of AI: First of all, we must have a clear vision of how AI can empower business. An ideal AI operation culture can achieve a natural integration of work processes between humans and AI systems. AI is good at certain tasks, while humans are good at creativity and judgment
 Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AMMeta upgrades AI assistant application, and the era of wearable AI is coming! The app, designed to compete with ChatGPT, offers standard AI features such as text, voice interaction, image generation and web search, but has now added geolocation capabilities for the first time. This means that Meta AI knows where you are and what you are viewing when answering your question. It uses your interests, location, profile and activity information to provide the latest situational information that was not possible before. The app also supports real-time translation, which completely changed the AI experience on Ray-Ban glasses and greatly improved its usefulness. The imposition of tariffs on foreign films is a naked exercise of power over the media and culture. If implemented, this will accelerate toward AI and virtual production
 Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AM
Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AMArtificial intelligence is revolutionizing the field of cybercrime, which forces us to learn new defensive skills. Cyber criminals are increasingly using powerful artificial intelligence technologies such as deep forgery and intelligent cyberattacks to fraud and destruction at an unprecedented scale. It is reported that 87% of global businesses have been targeted for AI cybercrime over the past year. So, how can we avoid becoming victims of this wave of smart crimes? Let’s explore how to identify risks and take protective measures at the individual and organizational level. How cybercriminals use artificial intelligence As technology advances, criminals are constantly looking for new ways to attack individuals, businesses and governments. The widespread use of artificial intelligence may be the latest aspect, but its potential harm is unprecedented. In particular, artificial intelligence
 A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AM
A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AMThe intricate relationship between artificial intelligence (AI) and human intelligence (NI) is best understood as a feedback loop. Humans create AI, training it on data generated by human activity to enhance or replicate human capabilities. This AI
 AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AM
AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AMAnthropic's recent statement, highlighting the lack of understanding surrounding cutting-edge AI models, has sparked a heated debate among experts. Is this opacity a genuine technological crisis, or simply a temporary hurdle on the path to more soph
 Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AM
Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AMIndia is a diverse country with a rich tapestry of languages, making seamless communication across regions a persistent challenge. However, Sarvam’s Bulbul-V2 is helping to bridge this gap with its advanced text-to-speech (TTS) t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Atom editor mac version download
The most popular open source editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SublimeText3 Chinese version
Chinese version, very easy to use

