
Home >Technology peripherals >AI >Quantification, pruning, distillation, what exactly do these big model slangs say?
Quantification, pruning, distillation, what exactly do these big model slangs say?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-04-26 09:28:181019browse
Quantification, pruning, distillation, if you often pay attention to large language models, you will definitely see these words. Just look at these words, it is difficult for us to look at these words alone. Understand what they do, but these words are particularly important for the development of large language models at this stage. This article will help you get to know them and understand their principles.
Model Compression
Quantification, pruning, and distillation are actually general neural network model compression technologies, not exclusive to large language models .
The significance of model compression
After compression, the model file will become smaller, and the hard disk space it uses will also become smaller, and it will be loaded into the memory. Or the cache space used during display will also become smaller, and the running speed of the model may also be improved.
Through compression, using the model will consume less computing resources, which can greatly expand the application scenarios of the model, especially where model size and computational efficiency are of greater concern, such as Mobile phones, embedded devices, etc.
What is compressed?
What is compressed is the parameters of the model. What are the parameters of the model?
You may have heard that current machine learning uses neural network models. The neural network model simulates the neural network in the human brain.
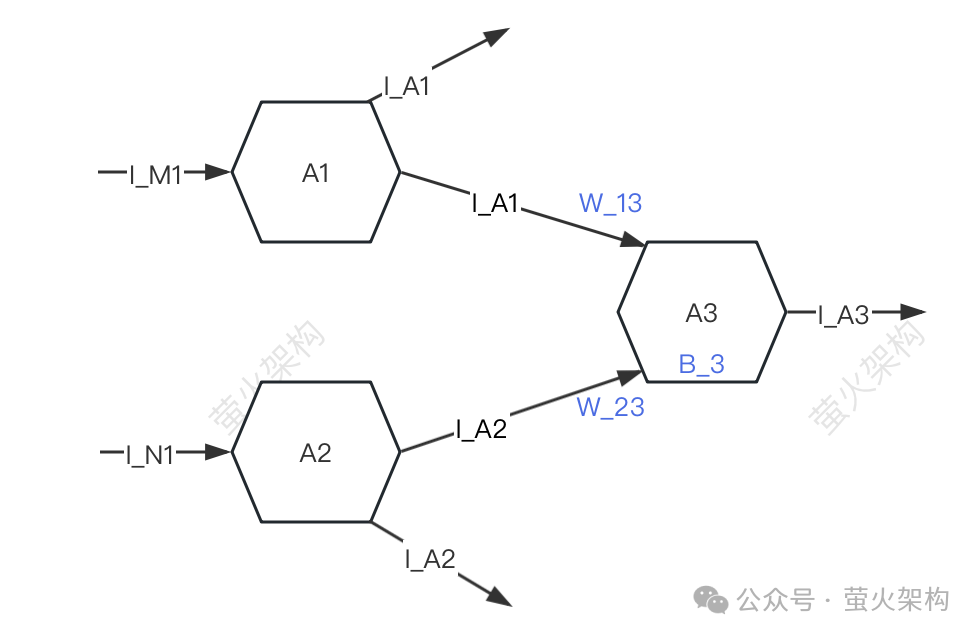
Here I drew a simple schematic diagram for everyone to take a look at.
 Picture
Picture
For simplicity, only three neurons are described: A1, A2, and A3. Each neuron receives signals from other neurons and transmits signals to other neurons.
A3 will receive the signals I_A1 and I_A2 from A1 and A2, but the intensity of the signals received by A3 from A1 and A2 is different (this intensity is called "weight"), assuming The strengths here are W_13 and W_23 respectively, and A3 will process the received signal data.
- First perform a weighted sum of the signals, that is, I_A1*W_13 I_A2*W_23,
- Then add A3 itself A parameter B_3 (called "bias"),
- Finally convert this data sum into a specific form, and send the converted signal to the next neuron .
In the process of processing this signal data, the weights (W_13, W_23) and bias (B_3) used are the parameters of the model. Of course, the model has other parameters. Parameters, but weights and biases are generally the bulk of all parameters. If divided by the 80/20 principle, they should both be above 80%.
When using a large language model to generate text, these parameters have been pre-trained and we cannot modify them. It is like the coefficients of polynomials in mathematics. We can only Pass in the unknown xyz and get an output result.
Model compression is to compress these parameters of the model. The first thing to consider is the weight and bias. The specific methods used are quantization, pruning and distillation, which are the focus of this article. .
Quantization
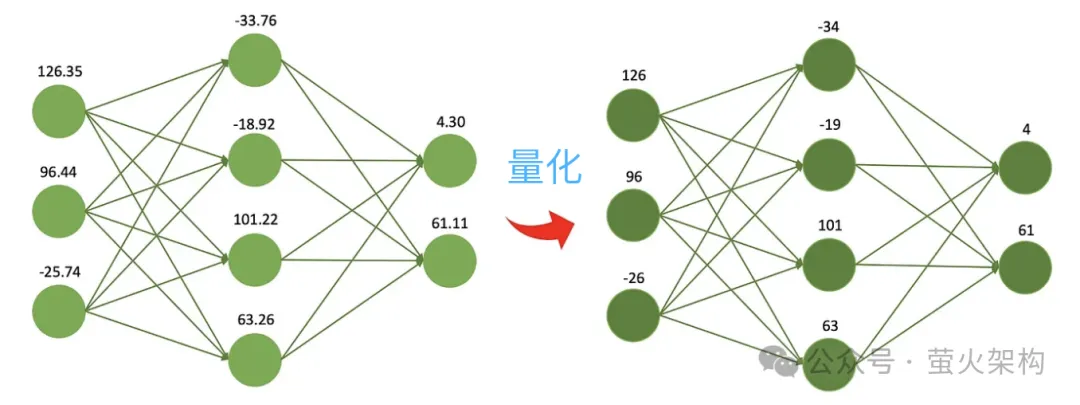
Quantization is to reduce the numerical accuracy of model parameters. For example, the initially trained weights are 32-bit floating point numbers, but in actual It is found that there is almost no loss in using 16-bit representation, but the model file size is reduced by half, the video memory usage is reduced by half, and the communication bandwidth requirements between the processor and memory are also reduced, which means lower costs and higher income.
It's like following a recipe, you need to determine the weight of each ingredient. You can use a very accurate electronic scale that is accurate to 0.01 grams, which is great because you can know the weight of each ingredient very accurately. However, if you are just making a potluck meal and don't actually need such high accuracy, you can use a simple and cheap scale with a minimum scale of 1 gram, which is not as accurate but is enough to make a delicious meal. dinner.
 Picture
Picture
Another advantage of quantification is that it can be calculated faster. Modern processors usually contain a lot of low-precision vector calculation units. The model can make full use of these hardware features to perform more parallel operations; at the same time, low-precision operations are usually faster than high-precision operations, and the consumption of a single multiplication and addition is time is shorter. These benefits also allow the model to run on lower-configuration machines, such as ordinary office or home computers, mobile phones and other mobile terminals without high-performance GPUs.
Along this line of thinking, people continue to compress 8-bit, 4-bit, and 2-bit models, which are smaller in size and use less computing resources. However, as the accuracy of the weights decreases, the values of different weights will become closer or even equal, which will reduce the accuracy and precision of the model output, and the performance of the model will decline to varying degrees.
Quantization technology has many different strategies and technical details, such as dynamic quantization, static quantization, symmetric quantization, asymmetric quantization, etc. For large language models, static quantization strategies are usually used. , after the model training is completed, we quantize the parameters once, and the model no longer needs to perform quantitative calculations when running, so that it can be easily distributed and deployed.
Pruning
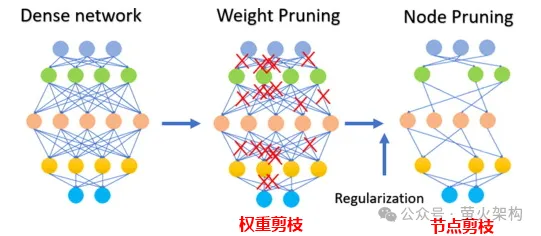
Pruning is to remove unimportant or rarely used weights in the model. The values of these weights are generally Close to 0. For some models, pruning can produce a higher compression ratio, making the model more compact and efficient. This is particularly useful for deploying models on resource-constrained devices or when memory and storage are limited.
Pruning also enhances the interpretability of the model. By removing unnecessary components, pruning makes the underlying structure of the model more transparent and easier to analyze. This is important for understanding the decision-making process of complex models such as neural networks.
Pruning involves not only pruning weight parameters, but also pruning certain neuron nodes, as shown in the following figure:
 Picture
Picture
Note that pruning is not suitable for all models. For some sparse models (most parameters are 0 or close to 0), pruning may have no effect; for some parameters For relatively few small models, pruning may lead to a significant decrease in model performance; for some high-precision tasks or applications, it is not suitable to prune the model, such as medical diagnosis, which is a matter of life and death.
When actually applying pruning technology, it is usually necessary to comprehensively consider the improvement of model running speed and the negative impact of pruning on model performance, and adopt some strategies, such as giving each element in the model Score a parameter, that is, evaluate the contribution of the parameter to the model performance. Those with high scores are important parameters that must not be cut off; those with low scores are parameters that may not be so important and can be considered for cutting. This score can be calculated through various methods, such as looking at the size of the parameter (the larger absolute value is usually more important), or determined through some more complex statistical analysis methods.
Distillation
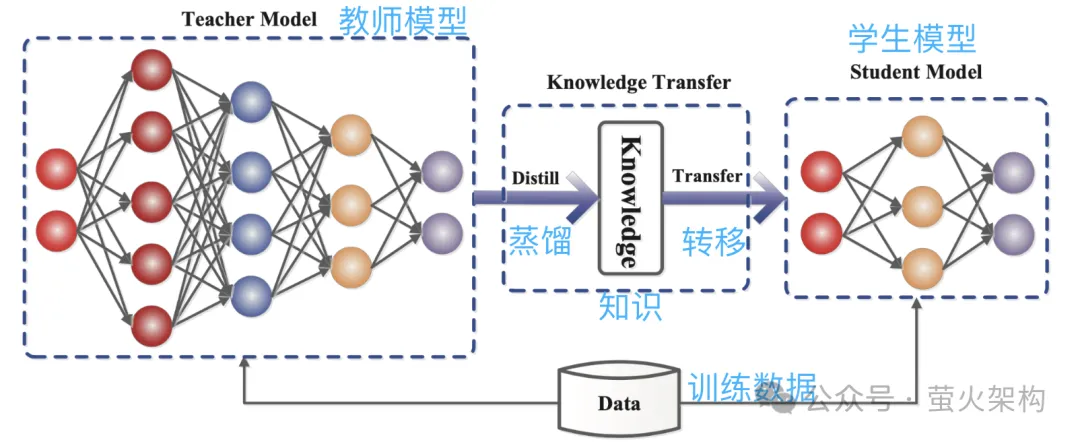
Distillation is to directly copy the probability distribution learned by the large model into a small model. The copied model is called the teacher model, which is generally an excellent model with a large number of parameters and strong performance. The new model is called a student model, which is generally a small model with relatively few parameters.
During distillation, the teacher model will generate multiple probability distributions of possible outputs based on the input, and then the student model will learn the probability distribution of this input and output. After extensive training, the student model can imitate the behavior of the teacher model, or learn the knowledge of the teacher model.
For example, in an image classification task, given a picture, the teacher model may output a probability distribution similar to the following:
- Cat: 0.7
- Dog: 0.4
- Car: 0.1
Then Submit this picture and the output probability distribution information to the student model for imitation learning.
 Picture
Picture
Because distillation compresses the knowledge of the teacher model into a smaller and simpler student model, the new The model may lose some information; in addition, the student model may rely too much on the teacher model, resulting in poor generalization ability of the model.
In order to make the learning effect of the student model better, we can use some methods and strategies.
Introducing the temperature parameter: Suppose there is a teacher who teaches very fast and the information density is very high, it may be a little difficult for students to keep up. At this time, if the teacher slows down and simplifies the information, it will be easier for the students to understand. In model distillation, the temperature parameter plays a role similar to "adjusting the lecture speed" to help the student model (small model) better understand and learn the knowledge of the teacher model (large model). Professionally speaking, it is to make the model output a smoother probability distribution, making it easier for the student model to capture and learn the output details of the teacher model.
Adjust the structure of the teacher model and the student model: It may be difficult for a student to learn something from an expert because the knowledge gap between them is too large to learn directly You may not understand. At this time, you can add a teacher in the middle, who can not only understand the words of experts, but also convert them into language that students can understand. The teacher added in the middle may be some intermediate layers or auxiliary neural networks, or the teacher can make some adjustments to the student model so that it can better match the output of the teacher model.
We have introduced three main model compression technologies above. In fact, there are still a lot of details here, but it is almost enough to understand the principles. There are also other model compression technologies. , such as low-rank decomposition, parameter sharing, sparse connection, etc. Interested students can check more related content.
In addition, after the model is compressed, its performance may decline significantly. At this time, we can make some fine-tuning of the model, especially for tasks that require higher model accuracy, such as In medical diagnosis, financial risk control, autonomous driving, etc., fine-tuning can restore the performance of the model to a certain extent and stabilize its accuracy and precision in certain aspects.
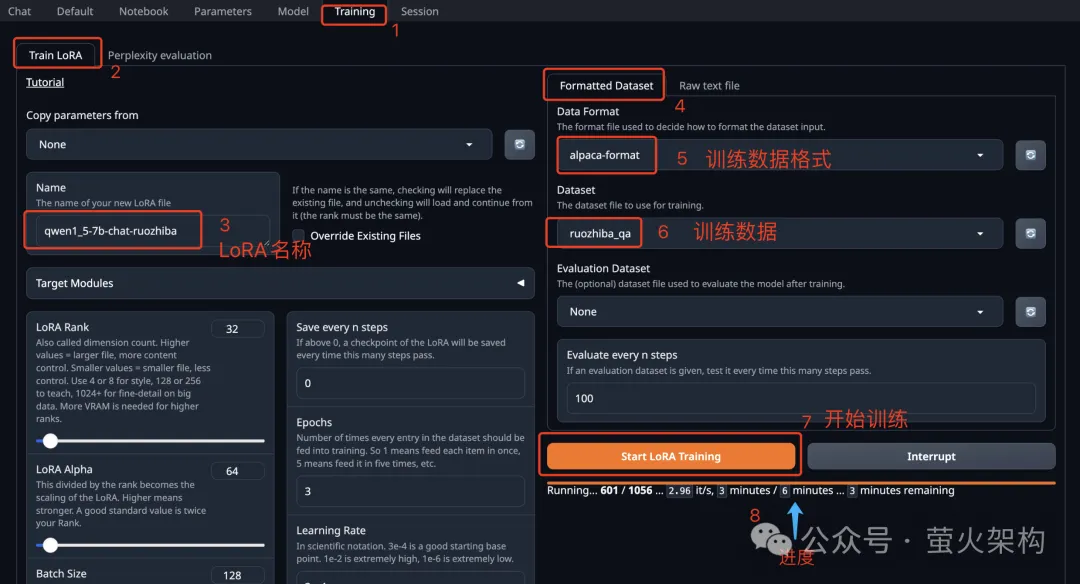
Talking about model fine-tuning, I recently shared an image of Text Generation WebUI on AutoDL. Text Generation WebUI is a Web program written using Gradio, which can easily adjust large language models. Perform inference and fine-tuning, and support multiple types of large language models, including Transformers, llama.cpp (GGUF), GPTQ, AWQ, EXL2 and other models in various formats. In the latest image, I have built-in Meta’s recently open source Llama3 large model, interested students can try it out. For how to use it, see: Learn to fine-tune a large language model in ten minutes
 Picture
Picture
Reference article:
##https://www.php.cn/link/d7852cd2408d9d3205dc75b59a6ce22e
https://www.php.cn/link/f204aab71691a8e18c3f6f00872db63b
https://www.php.cn/link/ b31f0c758bb498b5d56b5fea80f313a7
##https://www.php.cn/link/129ccfc1c1a82b0b23d4473a72373a0a
The above is the detailed content of Quantification, pruning, distillation, what exactly do these big model slangs say?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- What does the ieee802 standard divide the local area network hierarchical model into
- Definition of interaction methods: interaction between model quantification and edge artificial intelligence
- Digital Currency Quantitative Trading Software Ranking Top Ten Quantitative Trading Platform Apps in the Currency Circle
- ICLR 2024 Spotlight | Large language model weight, activation, all-round low-bit micronization, has been integrated into commercial APP