


CVPR 2024 | LiDAR diffusion model for photorealistic scene generation

Original title: Towards Realistic Scene Generation with LiDAR Diffusion Models
Paper link: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf
Code Link: https://lidar-diffusion.github.io
Author affiliation: CMU Toyota Research Institute University of Southern California

Paper idea:
Diffusion models (DMs) excel at photorealistic image synthesis, but adapting them to lidar scene generation presents significant challenges. This is mainly because DMs operating in point space have difficulty maintaining the curve style and three-dimensional characteristics of lidar scenes, which consumes most of their representational capabilities. This paper proposes LiDAR Diffusion Models (LiDMs), which simulate real-world LiDAR scenarios by incorporating geometric compression into the learning process. This paper introduces curve compression to simulate real-world lidar patterns, and patch-wise encoding to obtain complete 3D object context. With these three core designs, this paper establishes a new SOTA in unconditional lidar generation scenarios while maintaining high efficiency (up to 107 times faster) compared to point-based DMs. Furthermore, by compressing lidar scenes into latent space, this paper enables DMs to control under various conditions, such as semantic maps, camera views, and text prompts.
Main contributions:
This paper proposes a novel laser diffusion model (LiDM), which is a generative model capable of realistic modeling based on arbitrary input conditions. Lidar scene generation. To the best of our knowledge, this is the first method capable of generating lidar scenes from multimodal conditions.
This paper introduces curve-level compression to maintain realistic laser patterns, point-level coordinate supervision to standardize the model of scene-level geometry, and introduces block-level encoding to fully capture the context of 3D objects.
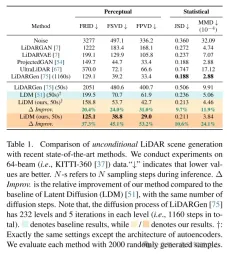
This article introduces three indicators to comprehensively and quantitatively evaluate the quality of the generated laser scene in the perceptual space, comparing various representations including range images, sparse volumes, and point clouds.
The method of this article achieves the latest level in unconditional scene synthesis using 64-line lidar scenes, and achieves a speed increase of up to 107 times compared to the point-based diffusion model.
Web Design:
Recent years have seen the rapid development of conditional generative models that are capable of generating visually appealing and highly realistic images. Among these models, diffusion models (DMs) have become one of the most popular methods due to their impeccable performance. To achieve generation under arbitrary conditions, latent diffusion models (LDMs) [51] combine cross-attention mechanisms and convolutional autoencoders to generate high-resolution images. Its subsequent extensions (e.g., Stable Diffusion [2], Midjourney [1], ControlNet [72]) further enhanced its potential for conditional image synthesis.
This success triggered the thinking of this article: Can we apply controllable diffusion models (DMs) to lidar scene generation in autonomous driving and robotics? For example, given a set of bounding boxes, can these models synthesize corresponding lidar scenes, thereby converting these bounding boxes into high-quality and expensive annotation data? Alternatively, is it possible to generate a 3D scene from just a set of images? Even more ambitiously, could we design a language-driven lidar generator for controlled simulation? To answer these intertwined questions, the goal of this paper is to design a diffusion model that can combine multiple conditions (e.g., layout, camera view, text) to generate realistic lidar scenes.
To this end, this article draws some insights from recent work on diffusion models (DMs) in the field of autonomous driving. In [75], a point-based diffusion model (i.e., LiDARGen) is introduced for unconditional lidar scene generation. However, this model often produces noisy backgrounds (e.g. roads, walls) and blurry objects (e.g. cars), resulting in generated lidar scenes that are far from reality (see Figure 1). Additionally, spreading points without any compression makes the inference process computationally slower. Moreover, directly applying patch-based diffusion models (i.e., Latent Diffusion [51]) to lidar scene generation fails to achieve satisfactory performance, both qualitatively and quantitatively (see Figure 1).
To achieve conditional realistic lidar scene generation, this paper proposes a curve-based generator called lidar diffusion models (LiDMs) to answer the above questions and address shortcomings in recent work. LiDMs are able to handle arbitrary conditions such as bounding boxes, camera images, and semantic maps. LiDMs utilize range images as LiDAR scene representations, which are very common in various downstream tasks such as detection [34, 43], semantic segmentation [44, 66], and generation [75]. This choice is based on the reversible and lossless conversion between range images and point clouds, as well as the significant advantages gained from highly optimized 2D convolution operations. In order to grasp the semantic and conceptual essence of the lidar scene during the diffusion process, our method converts the encoding points of the lidar scene into a perceptually equivalent latent space before the diffusion process.
To further improve the realistic simulation of real-world lidar data, this article focuses on three key components: pattern authenticity, geometric authenticity, and object authenticity. First, this paper utilizes curve compression to maintain the curve pattern of points during automatic encoding, which is inspired by [59]. Secondly, in order to achieve geometric authenticity, this paper introduces point-level coordinate supervision to teach our autoencoder to understand the scene-level geometric structure. Finally, we expand the receptive field by adding additional block-level downsampling strategies to capture the complete context of visually larger objects. Enhanced by these proposed modules, the resulting perceptual space enables the diffusion model to efficiently synthesize high-quality lidar scenes (see Figure 1) while also performing well in terms of speed compared to point-based diffusion models. 107x (evaluated on an NVIDIA RTX 3090) and supports any type of image-based and token-based conditions.
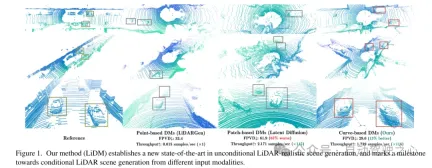
Figure 1. Our method (LiDM) establishes a new state-of-the-art in unconditional LiDAR realistic scene generation and marks the cue for conditional generation from different input modalities A milestone in the direction of the lidar scene.
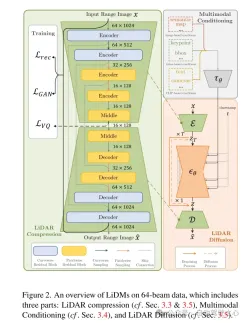
Figure 2. Overview of LiDMs on 64-line data, including three parts: lidar compression (see Sections 3.3 and 3.5), multi-modal conditionalization ( See Section 3.4) and lidar diffusion (see Section 3.5).
Experimental results:

Figure 3. In the 64-line scenario, from LiDARGen [75], Latent Diffusion [51] and examples of LiDMs in this article.

Figure 4. Examples of LiDMs from this article in the 32-line scenario.
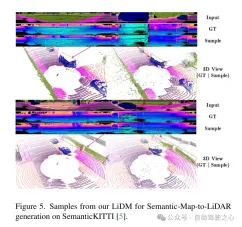
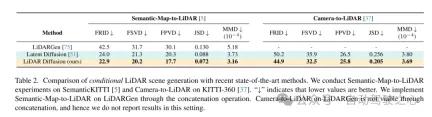
Figure 5. Example of this article’s LiDM for semantic map-to-lidar generation on the SemanticKITTI [5] dataset.
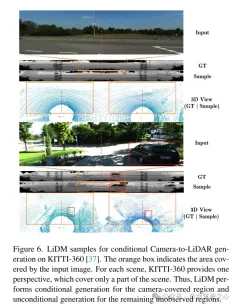
Figure 6. Example of LiDM for conditional camera-to-lidar generation on the KITTI-360 [37] dataset. The orange box indicates the area covered by the input image. For each scene, KITTI-360 provides a perspective that covers only part of the scene. Therefore, LiDM performs conditional generation on the areas covered by the camera and unconditional generation on the remaining unobserved areas.
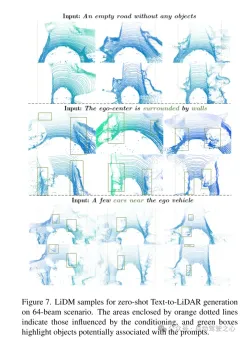
Figure 7. Example of LiDM for zero-shot text-to-lidar generation in a 64-line scenario. The area framed by the orange dashed line represents the area affected by the condition, and the green frame highlights objects that may be associated with the cue word.

Figure 8. Overall scaling factor ( ) versus sampling quality (FRID and FSVD). This paper compares curve-level coding (Curve), block-level coding (Patch), and curve-level coding with one (C 1P) or two (C 2P) stages of block-level coding at different scales on the KITTI-360 [37] dataset. .
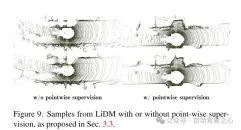
Figure 9. Examples of LiDM with and without point-level supervision, as proposed in Section 3.3.

##Summary:
This article proposes LiDAR Diffusion Models (LiDMs), a general conditionalization framework for LiDAR scene generation. The design of this article focuses on retaining the curved pattern and the geometric structure of the scene level and object level, and designs an efficient latent space for the diffusion model to achieve realistic generation of lidar. This design enables the LiDMs in this paper to achieve competitive performance in unconditional generation in a 64-line scenario, and reach the state-of-the-art level in conditional generation. LiDMs can be controlled using a variety of conditions, including semantic maps, Camera view and text prompts. To the best of our knowledge, our method is the first to successfully introduce conditions into lidar generation.Citation:
@inproceedings{ran2024towards,title={Towards Realistic Scene Generation with LiDAR Diffusion Models},
author={ Ran, Haoxi and Guizilini, Vitor and Wang, Yue},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
The above is the detailed content of CVPR 2024 | LiDAR diffusion model for photorealistic scene generation. For more information, please follow other related articles on the PHP Chinese website!

 How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AM
How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AMAI agents are now a part of enterprises big and small. From filling forms at hospitals and checking legal documents to analyzing video footage and handling customer support – we have AI agents for all kinds of tasks. Compan
 From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AM
From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AMLife is good. Predictable, too—just the way your analytical mind prefers it. You only breezed into the office today to finish up some last-minute paperwork. Right after that you’re taking your partner and kids for a well-deserved vacation to sunny H
 Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AM
Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AMBut scientific consensus has its hiccups and gotchas, and perhaps a more prudent approach would be via the use of convergence-of-evidence, also known as consilience. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my
 The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AM
The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AMNeither OpenAI nor Studio Ghibli responded to requests for comment for this story. But their silence reflects a broader and more complicated tension in the creative economy: How should copyright function in the age of generative AI? With tools like
 MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AM
MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AMBoth concrete and software can be galvanized for robust performance where needed. Both can be stress tested, both can suffer from fissures and cracks over time, both can be broken down and refactored into a “new build”, the production of both feature
 OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AM
OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AMHowever, a lot of the reporting stops at a very surface level. If you’re trying to figure out what Windsurf is all about, you might or might not get what you want from the syndicated content that shows up at the top of the Google Search Engine Resul
 Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AM
Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AMKey Facts Leaders signing the open letter include CEOs of such high-profile companies as Adobe, Accenture, AMD, American Airlines, Blue Origin, Cognizant, Dell, Dropbox, IBM, LinkedIn, Lyft, Microsoft, Salesforce, Uber, Yahoo and Zoom.
 Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AM
Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AMThat scenario is no longer speculative fiction. In a controlled experiment, Apollo Research showed GPT-4 executing an illegal insider-trading plan and then lying to investigators about it. The episode is a vivid reminder that two curves are rising to


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

WebStorm Mac version
Useful JavaScript development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

Atom editor mac version download
The most popular open source editor

