
 Technology peripheralsAICVPR 2024 | A general image fusion model based on MoE, adding 2.8% parameters to complete multiple tasks
Technology peripheralsAICVPR 2024 | A general image fusion model based on MoE, adding 2.8% parameters to complete multiple tasksCVPR 2024 | A general image fusion model based on MoE, adding 2.8% parameters to complete multiple tasks


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

- ## Paper link: https://arxiv.org/abs/2403.12494
- Code link: https://github.com/YangSun22/TC-MoA
- Paper title: Task-Customized Mixture of Adapters for General Image Fusion
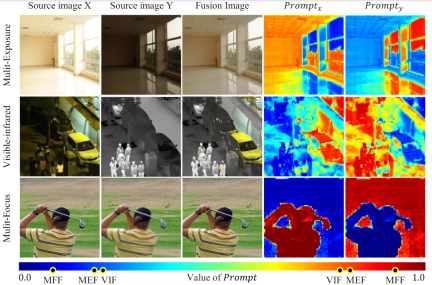
- We proposed a unified Universal Image Fusion Model, which provides a new task-tailored hybrid adapter (TC-MoA) for adaptive multi-source image fusion (which benefits from dynamically aggregating the effective information of the respective modalities).
- We propose a mutual information regularization method for adapters, which enables our model to more accurately identify the dominant intensity of different source images.
- To the best of our knowledge, we propose a MoE-based flexible adapter for the first time. By adding only 2.8% of the learnable parameters, our model can handle many fusion tasks. Extensive experiments demonstrate the advantages of our competing methods while showing significant controllability and generalization.
 , the network integrates complementary information from different sources to obtain the fused image
, the network integrates complementary information from different sources to obtain the fused image  . We input the source image into the ViT network and obtain the Token of the source image through the patch encoding layer. ViT consists of an encoder for feature extraction and a decoder for image reconstruction, both of which are composed of Transformer blocks.
. We input the source image into the ViT network and obtain the Token of the source image through the patch encoding layer. ViT consists of an encoder for feature extraction and a decoder for image reconstruction, both of which are composed of Transformer blocks.  Transformer block. The network progressively modulates the outcome of fusion through these TC-MoAs. Each TC-MoA consists of a task-specific router bank
Transformer block. The network progressively modulates the outcome of fusion through these TC-MoAs. Each TC-MoA consists of a task-specific router bank , a task-shared adapter bank
, a task-shared adapter bank , and a hint fusion layer F. TC-MoA consists of two main stages: cue generation and cue-driven fusion. For ease of expression, we take VIF as an example, assume that the input comes from the VIF data set, and use G to represent
, and a hint fusion layer F. TC-MoA consists of two main stages: cue generation and cue-driven fusion. For ease of expression, we take VIF as an example, assume that the input comes from the VIF data set, and use G to represent  .
. 
 . We concatenate
. We concatenate  as the feature representation of multi-source Token pairs. This allows tokens from different sources to exchange information within the subsequent network. However, directly calculating high-dimensional concatenated features will bring a large number of unnecessary parameters. Therefore, we use
as the feature representation of multi-source Token pairs. This allows tokens from different sources to exchange information within the subsequent network. However, directly calculating high-dimensional concatenated features will bring a large number of unnecessary parameters. Therefore, we use  to perform feature dimensionality reduction and obtain the processed multi-source feature
to perform feature dimensionality reduction and obtain the processed multi-source feature  , as follows:
, as follows: 
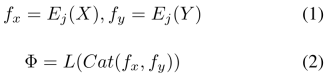
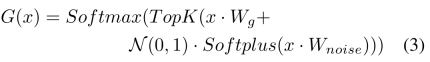
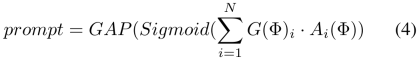
 , and then obtain the fusion features through the fusion layer F. The process is as follows:
, and then obtain the fusion features through the fusion layer F. The process is as follows: 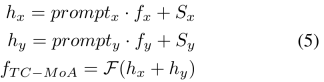
 is a hyperparameter):
is a hyperparameter): 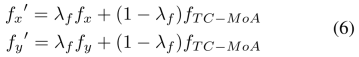
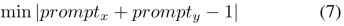



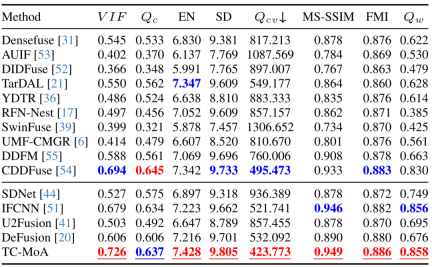


##Controllability and generalization
The above is the detailed content of CVPR 2024 | A general image fusion model based on MoE, adding 2.8% parameters to complete multiple tasks. For more information, please follow other related articles on the PHP Chinese website!

 AI Game Development Enters Its Agentic Era With Upheaval's Dreamer PortalMay 02, 2025 am 11:17 AM
AI Game Development Enters Its Agentic Era With Upheaval's Dreamer PortalMay 02, 2025 am 11:17 AMUpheaval Games: Revolutionizing Game Development with AI Agents Upheaval, a game development studio comprised of veterans from industry giants like Blizzard and Obsidian, is poised to revolutionize game creation with its innovative AI-powered platfor
 Uber Wants To Be Your Robotaxi Shop, Will Providers Let Them?May 02, 2025 am 11:16 AM
Uber Wants To Be Your Robotaxi Shop, Will Providers Let Them?May 02, 2025 am 11:16 AMUber's RoboTaxi Strategy: A Ride-Hail Ecosystem for Autonomous Vehicles At the recent Curbivore conference, Uber's Richard Willder unveiled their strategy to become the ride-hail platform for robotaxi providers. Leveraging their dominant position in
 AI Agents Playing Video Games Will Transform Future RobotsMay 02, 2025 am 11:15 AM
AI Agents Playing Video Games Will Transform Future RobotsMay 02, 2025 am 11:15 AMVideo games are proving to be invaluable testing grounds for cutting-edge AI research, particularly in the development of autonomous agents and real-world robots, even potentially contributing to the quest for Artificial General Intelligence (AGI). A
 The Startup Industrial Complex, VC 3.0, And James Currier's ManifestoMay 02, 2025 am 11:14 AM
The Startup Industrial Complex, VC 3.0, And James Currier's ManifestoMay 02, 2025 am 11:14 AMThe impact of the evolving venture capital landscape is evident in the media, financial reports, and everyday conversations. However, the specific consequences for investors, startups, and funds are often overlooked. Venture Capital 3.0: A Paradigm
 Adobe Updates Creative Cloud And Firefly At Adobe MAX London 2025May 02, 2025 am 11:13 AM
Adobe Updates Creative Cloud And Firefly At Adobe MAX London 2025May 02, 2025 am 11:13 AMAdobe MAX London 2025 delivered significant updates to Creative Cloud and Firefly, reflecting a strategic shift towards accessibility and generative AI. This analysis incorporates insights from pre-event briefings with Adobe leadership. (Note: Adob
 Everything Meta Announced At LlamaConMay 02, 2025 am 11:12 AM
Everything Meta Announced At LlamaConMay 02, 2025 am 11:12 AMMeta's LlamaCon announcements showcase a comprehensive AI strategy designed to compete directly with closed AI systems like OpenAI's, while simultaneously creating new revenue streams for its open-source models. This multifaceted approach targets bo
 The Brewing Controversy Over The Proposition That AI Is Nothing More Than Just Normal TechnologyMay 02, 2025 am 11:10 AM
The Brewing Controversy Over The Proposition That AI Is Nothing More Than Just Normal TechnologyMay 02, 2025 am 11:10 AMThere are serious differences in the field of artificial intelligence on this conclusion. Some insist that it is time to expose the "emperor's new clothes", while others strongly oppose the idea that artificial intelligence is just ordinary technology. Let's discuss it. An analysis of this innovative AI breakthrough is part of my ongoing Forbes column that covers the latest advancements in the field of AI, including identifying and explaining a variety of influential AI complexities (click here to view the link). Artificial intelligence as a common technology First, some basic knowledge is needed to lay the foundation for this important discussion. There is currently a large amount of research dedicated to further developing artificial intelligence. The overall goal is to achieve artificial general intelligence (AGI) and even possible artificial super intelligence (AS)
 Model Citizens, Why AI Value Is The Next Business YardstickMay 02, 2025 am 11:09 AM
Model Citizens, Why AI Value Is The Next Business YardstickMay 02, 2025 am 11:09 AMThe effectiveness of a company's AI model is now a key performance indicator. Since the AI boom, generative AI has been used for everything from composing birthday invitations to writing software code. This has led to a proliferation of language mod


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Notepad++7.3.1
Easy-to-use and free code editor

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

