

 Technology peripheralsAIBeyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)
Technology peripheralsAIBeyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA)
Written in front&The author’s personal understanding
Currently, as autonomous driving technology becomes more mature and the demand for autonomous driving perception tasks increases, the industrial and academic circles The industry very much hopes for an ideal perception algorithm model that can simultaneously complete three-dimensional target detection and semantic segmentation tasks based on BEV space. For a vehicle capable of autonomous driving, it is usually equipped with surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect data in different modalities. This makes full use of the complementary advantages between different modal data, making the data complementary advantages between different modalities. For example, 3D point cloud data can provide information for 3D target detection tasks, while color image data can provide more information for semantic segmentation tasks. accurate information. In view of the complementary advantages between different modal data, by converting the effective information of different modal data into the same coordinate system, subsequent joint processing and decision-making are facilitated. For example, 3D point cloud data can be converted into point cloud data based on BEV space, and image data from surround-view cameras can be projected into 3D space through the calibration of internal and external parameters of the camera, thereby achieving unified processing of different modal data. By taking advantage of different modal data, more accurate perception results can be obtained than single modal data. Now, we can already deploy the multi-modal perception algorithm model on the car to output more robust and accurate spatial perception results. Through accurate spatial perception results, we can provide more reliable and safe guarantee for the realization of autonomous driving functions.
Although many 3D perception algorithms for multi-sensory and multi-modal data fusion based on the Transformer network framework have recently been proposed in academia and industry, they all use the cross-attention mechanism in Transformer to achieve multi-sensory and multi-modal data fusion. Fusion between modal data to achieve ideal 3D target detection results. However, this type of multi-modal feature fusion method is not completely suitable for semantic segmentation tasks based on BEV space. In addition, in addition to using the cross-attention mechanism to complete information fusion between different modalities, many algorithms use forward vector conversion in LSA to construct fused features, but there are also some problems as follows: (Limitations word count, detailed description follows).
- Due to the currently proposed 3D sensing algorithm related to multi-modal fusion, the design of the fusion method of different modal data features is not sufficient, resulting in the perception algorithm model being unable to accurately capture the relationship between sensor data complex connection relationships, thereby affecting the final perceptual performance of the model.
- In the process of collecting data from different sensors, irrelevant noise information will inevitably be introduced. This inherent noise between different modalities will also cause noise to be mixed into the process of fusion of different modal features, resulting in multiple Inaccurate modal feature fusion affects subsequent perception tasks.
In view of the many problems mentioned above in the multi-modal fusion process that may affect the perception ability of the final model, and taking into account the powerful performance recently demonstrated by the generative model, we have The model is explored for multi-modal fusion and denoising tasks between multiple sensors. Based on this, we propose a generative model perception algorithm DifFUSER based on conditional diffusion to implement multi-modal perception tasks. As can be seen from the figure below, the DifFUSER multi-modal data fusion algorithm we proposed can achieve a more effective multi-modal fusion process.  The DifFUSER multimodal data fusion algorithm can achieve a more effective multimodal fusion process. The method mainly includes two stages. First, we use generative models to denoise and enhance the input data, generating clean and rich multimodal data. Then, the data generated by the generative model is used for multi-modal fusion to achieve better perception effects. The experimental results of the DifFUSER algorithm show that the multi-modal data fusion algorithm we proposed can achieve a more effective multi-modal fusion process. When implementing multi-modal perception tasks, this algorithm can achieve a more effective multi-modal fusion process and improve the model's perception capabilities. In addition, the algorithm's multi-modal data fusion algorithm can achieve a more efficient multi-modal fusion process. In summary
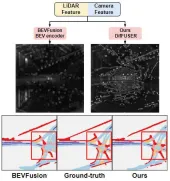
Visual comparison chart of the results of the proposed algorithm model and other algorithm models
Paper link: https://arxiv.org/pdf/2404.04629. pdf
Overall architecture & details of the network model
"Module details of the DifFUSER algorithm, a multi-task perception algorithm based on the conditional diffusion model" is a method used to solve Algorithms for task-aware problems. The figure below shows the overall network structure of our proposed DifFUSER algorithm. In this module, we propose a multi-task perception algorithm based on the conditional diffusion model to solve the task perception problem. The goal of this algorithm is to improve the performance of multi-task learning by spreading and aggregating task-specific information in the network. The integer of DifFUSER algorithm
 Proposed DifFUSER perception algorithm model network structure diagram
Proposed DifFUSER perception algorithm model network structure diagram
As can be seen from the above figure, the DifFUSER network structure we proposed mainly includes three sub-networks, namely the backbone network part and DifFUSER's multi-mode The state data fusion part and the final BEV semantic segmentation task head part. Head part of the 3D object detection perception task. In the backbone network part, we use existing deep learning network architectures, such as ResNet or VGG, to extract high-level features of the input data. The multi-modal data fusion part of DifFUSER uses multiple parallel branches, each branch is used to process different sensor data types (such as images, lidar and radar, etc.). Each branch has its own backbone network part
- : This part mainly extracts features from the 2D image data input to the network model and the 3D lidar point cloud data for output. Corresponding BEV semantic features. For the backbone network that extracts image features, it mainly includes a 2D image backbone network and a perspective conversion module. For the backbone network that extracts 3D lidar point cloud features, it mainly includes the 3D point cloud backbone network and the feature Flatten module.
- DifFUSER multi-modal data fusion part: The DifFUSER modules we proposed are linked together in the form of a hierarchical bidirectional feature pyramid network. We call this structure cMini-BiFPN. This structure provides an alternative structure to potential diffusion and can better handle the multi-scale and width-height detailed feature information from different sensor data.
- BEV semantic segmentation, 3D target detection perception task header part: Since our algorithm model can simultaneously output 3D target detection results and semantic segmentation results in BEV space, the 3D perception task header includes 3D detection head and semantic segmentation head. In addition, the losses involved in the algorithm model we proposed include diffusion loss, detection loss and semantic segmentation loss. By summing all losses, the parameters of the network model are updated through backpropagation.
Fusion architecture design (Conditional-Mini-BiFPN, cMini-BiFPN)
For the perception tasks in the autonomous driving system, the algorithm model can analyze the current external Real-time perception of the environment is crucial, so ensuring the performance and efficiency of the diffusion module is very important. Therefore, we are inspired by the bidirectional feature pyramid network and introduce a BiFPN diffusion architecture with similar conditions, which we call Conditional-Mini-BiFPN. Its specific network structure is shown in the figure above.

Progressive Sensor Dropout Training (PSDT)
For an autonomous car In other words, the performance of the autonomous driving acquisition sensors is very important. During the daily driving of autonomous vehicles, it is very likely that the camera sensor or lidar sensor will be blocked or malfunctioned, thus affecting the safety of the final autonomous driving system. performance and operational efficiency. Based on this consideration, we proposed a progressive sensor dropout training paradigm to enhance the robustness and adaptability of the proposed algorithm model in situations where the sensor may be blocked. Through the progressive sensor dropout training paradigm we proposed, the algorithm model can reconstruct the missing features by using the distribution of two modal data collected by the camera sensor and the lidar sensor, thereby achieving the best performance in harsh conditions. Excellent adaptability and robustness. Specifically, we exploit features from image data and lidar point cloud data in three different ways, as training targets, noise input to the diffusion module, and to simulate conditions in which a sensor is lost or malfunctioned. To simulate sensor Loss or failure conditions, we gradually increase the loss rate of camera sensor or lidar sensor input from 0 to a predefined maximum value a = 25 during training. The entire process can be expressed by the following formula: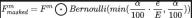
Among them, represents the number of training rounds in which the current model is in, and defines the probability of dropout to represent the probability that each feature in the feature is dropped. Through this progressive training process, the model is not only trained to effectively denoise and generate more expressive features, but also minimizes its dependence on any single sensor, thereby enhancing its handling of incomplete sensors with greater resilience. Data capabilities.
Gated Self-Conditioned Modulation Diffusion Module (GSM Diffusion Module)

Specifically, Gated Self-Conditioned Modulation Diffusion Module The network structure is shown in the figure below

Schematic diagram of the network structure of the gated self-conditional modulation diffusion module

Experimental results & evaluation indicators
Quantitative analysis part
In order to verify the perceptual results of our proposed algorithm model DifFUSER on multi-tasks, we mainly used nuScenes data 3D target detection and semantic segmentation experiments based on BEV space were conducted on the set.
First, we compared the performance of the proposed algorithm model DifFUSER with other multi-modal fusion algorithms on semantic segmentation tasks. The specific experimental results are shown in the following table:
 Comparison of experimental results of different algorithm models on the BEV space-based semantic segmentation task on the nuScenes dataset
Comparison of experimental results of different algorithm models on the BEV space-based semantic segmentation task on the nuScenes dataset
It can be seen from the experimental results that the algorithm model we proposed has better performance than the baseline model. There has been a significant improvement. Specifically, the mIoU value of the BEVFusion model is only 62.7%, while the algorithm model we proposed has reached 69.1%, with an improvement of 6.4% points, which shows that the algorithm we proposed has more advantages in different categories. In addition, the figure below also more intuitively illustrates the advantages of the algorithm model we proposed. Specifically, the BEVFusion algorithm will output poor segmentation results, especially in long-distance scenarios, where sensor misalignment is more obvious. In comparison, our algorithm model has more accurate segmentation results, with more obvious details and less noise.

Comparison of segmentation visualization results between the proposed algorithm model and the baseline model
In addition, we will also compare the proposed algorithm model with other 3D target detection algorithm models For comparison, the specific experimental results are shown in the table below


Qualitative analysis part
The following figure shows the visualization of the 3D target detection and semantic segmentation results of the BEV space of our proposed DifFUSER algorithm model. It can be seen from the visualization results that we The proposed algorithm model has good detection and segmentation effects.

Conclusion
This paper proposes a multi-modal perception algorithm model DifFUSER based on the diffusion model, by improving the fusion of network models architecture and utilize the denoising properties of the diffusion model to improve the fusion quality of the network model. The experimental results on the Nuscenes data set show that the algorithm model we proposed achieves SOTA segmentation performance in the semantic segmentation task of BEV space, and can achieve detection performance similar to the current SOTA algorithm model in the 3D target detection task.
The above is the detailed content of Beyond BEVFusion! DifFUSER: Diffusion model enters autonomous driving multi-task (BEV segmentation + detection dual SOTA). For more information, please follow other related articles on the PHP Chinese website!

 在 CARLA自动驾驶模拟器中添加真实智体行为Apr 08, 2023 pm 02:11 PM
在 CARLA自动驾驶模拟器中添加真实智体行为Apr 08, 2023 pm 02:11 PMarXiv论文“Insertion of real agents behaviors in CARLA autonomous driving simulator“,22年6月,西班牙。由于需要快速prototyping和广泛测试,仿真在自动驾驶中的作用变得越来越重要。基于物理的模拟具有多种优势和益处,成本合理,同时消除了prototyping、驾驶员和弱势道路使用者(VRU)的风险。然而,主要有两个局限性。首先,众所周知的现实差距是指现实和模拟之间的差异,阻碍模拟自主驾驶体验去实现有效的现实世界
 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 一文通览自动驾驶三大主流芯片架构Apr 12, 2023 pm 12:07 PM
一文通览自动驾驶三大主流芯片架构Apr 12, 2023 pm 12:07 PM当前主流的AI芯片主要分为三类,GPU、FPGA、ASIC。GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。ASIC属于为AI特定场景定制的芯片。行业内已经确认CPU不适用于AI计算,但是在AI应用领域也是必不可少。 GPU方案GPU与CPU的架构对比CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算
 自动驾驶汽车激光雷达如何做到与GPS时间同步?Mar 31, 2023 pm 10:40 PM
自动驾驶汽车激光雷达如何做到与GPS时间同步?Mar 31, 2023 pm 10:40 PMgPTP定义的五条报文中,Sync和Follow_UP为一组报文,周期发送,主要用来测量时钟偏差。 01 同步方案激光雷达与GPS时间同步主要有三种方案,即PPS+GPRMC、PTP、gPTPPPS+GPRMCGNSS输出两条信息,一条是时间周期为1s的同步脉冲信号PPS,脉冲宽度5ms~100ms;一条是通过标准串口输出GPRMC标准的时间同步报文。同步脉冲前沿时刻与GPRMC报文的发送在同一时刻,误差为ns级别,误差可以忽略。GPRMC是一条包含UTC时间(精确到秒),经纬度定位数据的标准格
 特斯拉自动驾驶硬件 4.0 实物拆解:增加雷达,提供更多摄像头Apr 08, 2023 pm 12:11 PM
特斯拉自动驾驶硬件 4.0 实物拆解:增加雷达,提供更多摄像头Apr 08, 2023 pm 12:11 PM2 月 16 日消息,特斯拉的新自动驾驶计算机,即硬件 4.0(HW4)已经泄露,该公司似乎已经在制造一些带有新系统的汽车。我们已经知道,特斯拉准备升级其自动驾驶硬件已有一段时间了。特斯拉此前向联邦通信委员会申请在其车辆上增加一个新的雷达,并称计划在 1 月份开始销售,新的雷达将意味着特斯拉计划更新其 Autopilot 和 FSD 的传感器套件。硬件变化对特斯拉车主来说是一种压力,因为该汽车制造商一直承诺,其自 2016 年以来制造的所有车辆都具备通过软件更新实现自动驾驶所需的所有硬件。事实证
 端到端自动驾驶中轨迹引导的控制预测:一个简单有力的基线方法TCPApr 10, 2023 am 09:01 AM
端到端自动驾驶中轨迹引导的控制预测:一个简单有力的基线方法TCPApr 10, 2023 am 09:01 AMarXiv论文“Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline“, 2022年6月,上海AI实验室和上海交大。当前的端到端自主驾驶方法要么基于规划轨迹运行控制器,要么直接执行控制预测,这跨越了两个研究领域。鉴于二者之间潜在的互利,本文主动探索两个的结合,称为TCP (Trajectory-guided Control Prediction)。具
 一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM
一文聊聊SLAM技术在自动驾驶的应用Apr 09, 2023 pm 01:11 PM定位在自动驾驶中占据着不可替代的地位,而且未来有着可期的发展。目前自动驾驶中的定位都是依赖RTK配合高精地图,这给自动驾驶的落地增加了不少成本与难度。试想一下人类开车,并非需要知道自己的全局高精定位及周围的详细环境,有一条全局导航路径并配合车辆在该路径上的位置,也就足够了,而这里牵涉到的,便是SLAM领域的关键技术。什么是SLAMSLAM (Simultaneous Localization and Mapping),也称为CML (Concurrent Mapping and Localiza
 一文聊聊自动驾驶中交通标志识别系统Apr 12, 2023 pm 12:34 PM
一文聊聊自动驾驶中交通标志识别系统Apr 12, 2023 pm 12:34 PM什么是交通标志识别系统?汽车安全系统的交通标志识别系统,英文翻译为:Traffic Sign Recognition,简称TSR,是利用前置摄像头结合模式,可以识别常见的交通标志 《 限速、停车、掉头等)。这一功能会提醒驾驶员注意前面的交通标志,以便驾驶员遵守这些标志。TSR 功能降低了驾驶员不遵守停车标志等交通法规的可能,避免了违法左转或者无意的其他交通违法行为,从而提高了安全性。这些系统需要灵活的软件平台来增强探测算法,根据不同地区的交通标志来进行调整。交通标志识别原理交通标志识别又称为TS


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SublimeText3 English version
Recommended: Win version, supports code prompts!

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SublimeText3 Linux new version
SublimeText3 Linux latest version

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

