
Home >Technology peripherals >AI >Llama3 comes suddenly! The open source community is boiling again: the era of free access to GPT4-level models has arrived
Llama3 comes suddenly! The open source community is boiling again: the era of free access to GPT4-level models has arrived

- PHPzforward
- 2024-04-19 12:43:011264browse
Llama 3 is coming!
Just now, Meta’s official website was updated, officially announcing the Llama 3 8 billion and 70 billion parameter versions.

And the launch is open source SOTA:
Meta official data shows that the Llama 3 8B and 70B versions surpass all opponents in their respective parameter scales.
8B model outperforms Gemma 7B and Mistral 7B Instruct on many benchmarks such as MMLU, GPQA, and HumanEval.
The 70B model has surpassed the popular closed-source Claude 3 Sonnet, and has gone back and forth with Google's Gemini Pro 1.5.

As soon as the Huggingface link came out, the open source community became excited again.
The sharp-eyed blind students also immediately discovered Huadian:
Meta even hid a version of Llama 3 with 400 billion parameters, which is no less than the Claude 3 super large Opus!

The CEO of HyperWriteAI, an AI writing assistant startup, couldn’t help but sigh when he saw this:
We are entering a new world, a GPT -A world where level 4 models are open source and freely accessible.

NVIDIA scientist Jim Fan believes that Llama 3 400B, which is still in training, will become a watershed for open source large models and change the development of many academic research and start-up companies. Way.

Full SOTA, but 8k window
More technical details, Meta is given in the blog post.
At the architectural level, Llama 3 chose the classic decoder-only Transformer architecture, using a word segmenter containing a 128K token vocabulary.
Looking at the training data, the training data scale of Llama 3 has reached 15T tokens, all of which come from public information, of which 5% is non-English data, covering more than 30 languages.
Llama 3 has 7 times more training data than Llama 2, and has 4 times more code than Llama 2.
In addition, in order to improve the reasoning efficiency of the Llama 3 model, Meta AI also adopts the Group Query Attention (GQA) mechanism to train the model on a sequence of 8192 tokens, and uses a mask to ensure that self-attention is not Will cross document boundaries.

As a result, whether it is the 8B or 70B version, Llama 3 has made a major leap forward compared to the previous generation Llama 2 of similar size.
Among the 8B and 70B parameter scale models so far, Llama 3 has become a new SOTA model.
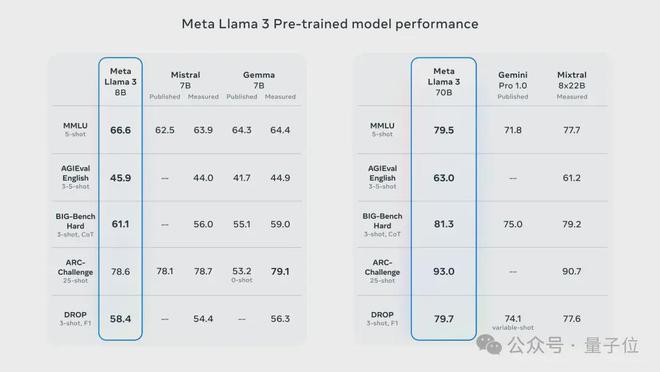
In terms of language (MMLU), knowledge (GPQA), programming (HumanEval), mathematics (GSM-8K, MATH) and other capabilities, Llama 3 is almost completely ahead of other models of the same scale.

In addition to these conventional data sets, Meta AI also evaluated the performance of Llama 3 in real-life scenarios and developed a high-quality test data set for this purpose.
This test set contains 1,800 pieces of data, covering 12 key use cases such as coding, reasoning, writing, and summary, and is confidential to the development team.
As a result, Llama 3 not only significantly surpassed Llama 2, but also defeated well-known models such as Claude 3 Sonnet, Mistral Medium and GPT-3.5.

The performance of Llama 3 is also remarkable on higher-order and more difficult data sets such as AGIEval, BIG-Bench, and ARC-Challenge.
The 8B version surpassed Mistral and Gemma in these tasks, while the 70B version defeated Gemini Pro and Mixtral with MoE architecture, winning SOTAs of corresponding sizes respectively.
However, the only drawback is that the context window of Llama 3 is only 8k. Compared with the current large models with dozens or millions of windows, it seems that it is still stuck in the previous generation. (Manual dog head).

But don’t worry too much. Matt Shumer is optimistic about this. He expressed his belief that with the efforts of the open source community, the window length will soon be expanded.

Llama welcomes the official web version
Currently, the basic and Instruct versions of both parameters of Llama 3 are available on Hugging Face for download.
In addition, cloud service platforms such as Microsoft Azure, Google Cloud, Amazon AWS, and NVIDIA NIM will also launch Llama 3 one after another.
At the same time, Meta also said that Llama 3 will be supported by hardware platforms provided by Intel, Nvidia, AMD, Qualcomm and other manufacturers.

It is worth mentioning that this time, together with the basic model, there is an official Web version based on Llama 3, called Meta AI.

Currently, the platform has two major functions: dialogue and painting. If you only use dialogue, you don’t need to register and log in, and it can be used immediately. To use the painting function, you need to log in to your account first.

However, the platform currently does not support Chinese, and functions such as text uploading have not yet been launched.

In terms of code, the platform can also run some simple Python programs, but it seems that it can only output text, and tasks involving drawing cannot be run.

# Overall, this web version is still relatively rudimentary, but you might as well look forward to a wave of subsequent updates.
One More Thing
A small incident is that in fact, a few hours before Meta’s official announcement, Microsoft’s Azure market had already stolen the news of the Llama 3 8B Instruct version.

The Llama 3 price list on the open source model machine learning online platform Replicate was also immediately pulled out by netizens.
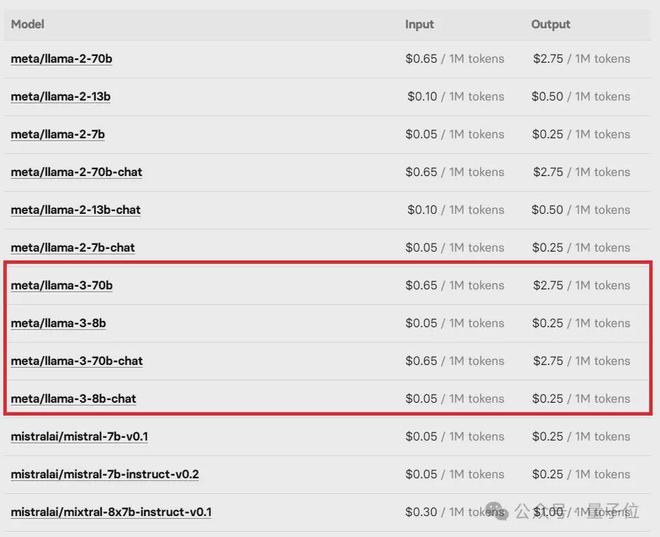
#But soon, these "little tidbits" were all 404'ed.
Fortunately, the mistake is over, and the official is not delaying it. Friends who care about open source large models can start to doge.

参考链接:
[1]https://ai.meta.com/blog/meta-llama-3/。
[2]https://about.fb.com/news/2024/04/meta-ai-assistant-built-with-llama-3/。
[3]https://huggingface.co/meta-llama/Meta-Llama-3-70B。
The above is the detailed content of Llama3 comes suddenly! The open source community is boiling again: the era of free access to GPT4-level models has arrived. For more information, please follow other related articles on the PHP Chinese website!