


2024 will see a technological leap forward in large language models (LLMs) as researchers and engineers continue to push the boundaries of natural language processing. These parameter-rich LLMs are revolutionizing how we interact with machines, enabling more natural conversations, code generation, and complex reasoning. However, building these behemoths is no easy task, involving the complexity of data preparation, advanced training techniques, and scalable inference. This review delves into the technical details required to build LLMs, covering recent advances from data sourcing to training innovations and alignment strategies.

2024 promises to be a landmark era for large language models (LLMs) as researchers and engineers push the boundaries of what is possible in natural language processing. These large-scale neural networks with billions or even trillions of parameters will revolutionize the way we interact with machines, enabling more natural and open-ended conversations, code generation, and multimodal reasoning.
However, establishing such a large LL.M. is not a simple matter. It requires a carefully curated pipeline, from data sourcing and preparation to advanced training techniques and scalable inference. In this post, we’ll take a deep dive into the technical complexities involved in building these cutting-edge language models, exploring the latest innovations and challenges across the stack.
Data preparation
1. Data source
The foundation of any Master of Laws is the data it is trained on, and Modern models ingest staggering amounts of text (often over a trillion tokens) from web crawlers, code repositories, books, and more. Common data sources include:
Generally crawled web corpora
Code repositories such as GitHub and Software Heritage
Wikipedia and curated datasets such as books (public domain and Copyrighted)
Synthetically generated data
2. Data filtering
Simply getting all available data is usually not optimal because It may introduce noise and bias. Therefore, careful data filtering techniques are employed:
Quality filtering
Heuristic filtering based on document properties such as length and language
Conducted using examples of good and bad data Classifier-based filtering
Perplexity threshold for language model
Domain-specific filtering
Check the impact on domain-specific subsets
Develop custom rules and threshold
Selection strategy
Deterministic hard threshold
Probabilistic random sampling
3. Deduplication
Large web corpora contain significant overlap, and redundant documents may cause the model to effectively "memorize" too many regions. Utilize efficient near-duplicate detection algorithms such as MinHash to reduce this redundancy bias.
4. Tokenization
Once we have a high-quality, deduplicated text corpus, we need to tokenize it - convert it into a neural network for training Tag sequences that can be ingested during. Ubiquitous byte-level BPE encoding is preferred and handles code, mathematical notation, and other contexts elegantly. Careful sampling of the entire data set is required to avoid overfitting the tokenizer itself.
5. Data Quality Assessment
Assessing data quality is a challenging but crucial task, especially at such a large scale. Techniques employed include:
Monitoring of high-signal benchmarks such as Commonsense QA, HellaSwag and OpenBook QA during subset training
Manual inspection of domains/URLs and inspection of retained/dropped examples
Data Clustering and Visualization Tools
Train auxiliary taggers to analyze tags
Training
1. Model Parallelism
The sheer scale of modern LLMs (often too large to fit on a single GPU or even a single machine) requires advanced parallelization schemes to split the model across multiple devices and machines in various ways:
Data Parallelism: Spread batches across multiple devices
Tensor Parallelism: Split model weights and activations across devices
Pipeline Parallelism: Treat the model as a series of stages and Pipelining across devices
Sequence parallelism: splitting individual input sequences to further scale
Combining these 4D parallel strategies can scale to models with trillions of parameters.
2. Efficient attention
The main computational bottleneck lies in the self-attention operation at the core of the Transformer architecture. Methods such as Flash Attention and Factorized Kernels provide highly optimized attention implementations that avoid unnecessarily implementing the full attention matrix.
3. Stable training
Achieving stable convergence at such an extreme scale is a major challenge. Innovations in this area include:
Improved initialization schemes
Hyperparameter transfer methods such as MuTransfer
Optimized learning rate plans such as cosine annealing
4. Architectural Innovation
Recent breakthroughs in model architecture have greatly improved the capabilities of the LL.M.:
Mixture-of-Experts (MoE): Only active per example A subset of model parameters, enabled by routing networks
Mamba: an efficient implementation of hash-based expert mixing layers
alignment
While competency is crucial, we also need LLMs that are safe, authentic, and aligned with human values and guidance. This is the goal of this emerging field of artificial intelligence alignment:
Reinforcement Learning from Human Feedback (RLHF): Use reward signals derived from human preferences for model outputs to fine-tune models; PPO, DPO, etc. Methods are being actively explored.
Constitutional AI: Constitutional AI encodes rules and instructions into the model during the training process, instilling desired behaviors from the ground up.
Inference
Once our LLM is trained, we need to optimize it for efficient inference - providing model output to the user with minimal latency:
Quantization: Compress large model weights into a low-precision format such as int8 for cheaper computation and memory footprint; commonly used technologies include GPTQ, GGML and NF4.
Speculative decoding: Accelerate inference by using a small model to launch a larger model, such as the Medusa method
System optimizations: Just-in-time compilation, kernel fusion, and CUDA graphics optimization can further increase speed.
Conclusion
Building large-scale language models in 2024 requires careful architecture and innovation across the entire stack—from data sourcing and cleansing to scalable training systems and Efficient inference deployment. We've only covered a few highlights, but the field is evolving at an incredible pace, with new technologies and discoveries emerging all the time. Challenges surrounding data quality assessment, large-scale stable convergence, consistency with human values, and robust real-world deployment remain open areas. But the potential for an LL.M. is huge – stay tuned as we push the boundaries of what’s possible with linguistic AI in 2024 and beyond!
The above is the detailed content of The journey to building large-scale language models in 2024. For more information, please follow other related articles on the PHP Chinese website!

 一文搞懂Tokenization!Apr 12, 2024 pm 02:31 PM
一文搞懂Tokenization!Apr 12, 2024 pm 02:31 PM语言模型是对文本进行推理的,文本通常是字符串形式,但模型的输入只能是数字,因此需要将文本转换成数字形式。Tokenization是自然语言处理的基本任务,根据特定需求能够把一段连续的文本序列(如句子、段落等)切分为一个字符序列(如单词、短语、字符、标点等多个单元),其中的单元称为token或词语。根据下图所示的具体流程,首先将文本句子切分成一个个单元,然后将单元素数值化(映射为向量),再将这些向量输入到模型进行编码,最后输出到下游任务进一步得到最终的结果。文本切分按照文本切分的粒度可以将Toke
 git分支能改名字吗Jun 16, 2022 pm 05:55 PM
git分支能改名字吗Jun 16, 2022 pm 05:55 PMgit分支能改名字。改名方法:1、利用git中的branch命令修改本地分支的名称,语法为“git branch -m 旧名字 新名字”;2、利用“git push origin 新名字”命令,在删除远程分支之后将改名后的本地分支推送到远程;3、利用IDEA直接操作修改分支名称即可。
 为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架Jul 25, 2024 am 06:42 AM
为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架Jul 25, 2024 am 06:42 AM编辑|ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choicequestions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答
 云端部署大模型的三个秘密Apr 24, 2024 pm 03:00 PM
云端部署大模型的三个秘密Apr 24, 2024 pm 03:00 PM编译|星璇出品|51CTO技术栈(微信号:blog51cto)在过去的两年里,我更多地参与了使用大型语言模型(LLMs)的生成AI项目,而非传统的系统。我开始怀念无服务器云计算。它们的应用范围广泛,从增强对话AI到为各行各业提供复杂的分析解决方案,以及其他许多功能。许多企业将这些模型部署在云平台上,因为公共云提供商已经提供了现成的生态系统,而且这是阻力最小的路径。然而,这并不便宜。云还提供了其他好处,如可扩展性、效率和高级计算能力(按需提供GPU)。在公共云平台上部署LLM的过程有一些鲜为人知的
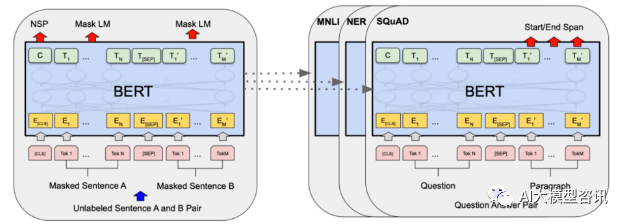 大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列Oct 07, 2023 pm 12:13 PM
大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列Oct 07, 2023 pm 12:13 PM2018年谷歌发布了BERT,一经面世便一举击败11个NLP任务的State-of-the-art(Sota)结果,成为了NLP界新的里程碑;BERT的结构如下图所示,左边是BERT模型预训练过程,右边是对于具体任务的微调过程。其中,微调阶段是后续用于一些下游任务的时候进行微调,例如:文本分类,词性标注,问答系统等,BERT无需调整结构就可以在不同的任务上进行微调。通过”预训练语言模型+下游任务微调”的任务设计,带来了强大的模型效果。从此,“预训练语言模型+下游任务微调”便成为了NLP领域主流训
 顺手训了一个史上超大ViT?Google升级视觉语言模型PaLI:支持100+种语言Apr 12, 2023 am 09:31 AM
顺手训了一个史上超大ViT?Google升级视觉语言模型PaLI:支持100+种语言Apr 12, 2023 am 09:31 AM近几年自然语言处理的进展很大程度上都来自于大规模语言模型,每次发布的新模型都将参数量、训练数据量推向新高,同时也会对现有基准排行进行一次屠榜!比如今年4月,Google发布5400亿参数的语言模型PaLM(Pathways Language Model)在语言和推理类的一系列测评中成功超越人类,尤其是在few-shot小样本学习场景下的优异性能,也让PaLM被认为是下一代语言模型的发展方向。同理,视觉语言模型其实也是大力出奇迹,可以通过提升模型的规模来提升性能。当然了,如果只是多任务的视觉语言模
 RoSA: 一种高效微调大模型参数的新方法Jan 18, 2024 pm 05:27 PM
RoSA: 一种高效微调大模型参数的新方法Jan 18, 2024 pm 05:27 PM随着语言模型扩展到前所未有的规模,对下游任务进行全面微调变得十分昂贵。为了解决这个问题,研究人员开始关注并采用PEFT方法。PEFT方法的主要思想是将微调的范围限制在一小部分参数上,以降低计算成本,同时仍能实现自然语言理解任务的最先进性能。通过这种方式,研究人员能够在保持高性能的同时,节省计算资源,为自然语言处理领域带来新的研究热点。RoSA是一种新的PEFT技术,通过在一组基准测试的实验中,发现在使用相同参数预算的情况下,RoSA表现出优于先前的低秩自适应(LoRA)和纯稀疏微调方法。本文将深
 Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM
Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型Apr 14, 2023 pm 06:58 PM2月25日消息,Meta在当地时间周五宣布,它将推出一种针对研究社区的基于人工智能(AI)的新型大型语言模型,与微软、谷歌等一众受到ChatGPT刺激的公司一同加入人工智能竞赛。Meta的LLaMA是“大型语言模型MetaAI”(LargeLanguageModelMetaAI)的缩写,它可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。该公司将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。Meta表示,该模型对算力的要

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver Mac version
Visual web development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

