
Home >Technology peripherals >AI >Magically modified RNN challenges Transformer, RWKV is new: launching two new architecture models
Magically modified RNN challenges Transformer, RWKV is new: launching two new architecture models

- 王林forward
- 2024-04-15 09:10:061336browse
Instead of taking the usual path of Transformer, the new domestic architecture of RNN is modified RWKV, and there is new progress:
proposes two new RWKV architectures, namely Eagle (RWKV-5) and Finch (RWKV-6).
These two sequence models are based on the RWKV-4 architecture and then improved.
Design advancements in the new architecture include Multi-headed matrix-valued states(multi-headed matrix-valued states)and dynamic recursion mechanism (dynamic recurrence mechanism) , these improvements improve the expressive ability of the RWKV model while maintaining the inference efficiency characteristics of RNN.
At the same time, the new architecture introduces a new multilingual corpus containing 1.12 trillion tokens.
The team also developed a fast word segmenter based on greedy matching (greedy matching) to enhance the multilinguality of RWKV.
Currently, 4 Eagle models and 2 Finch models have been released on Huohuofian~
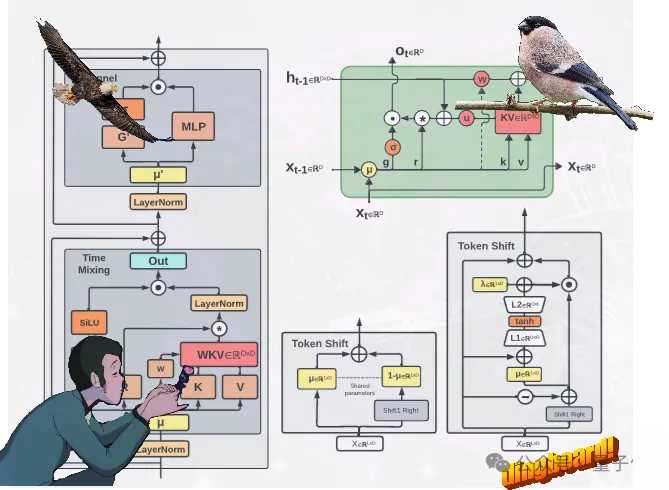
New models Eagle and Finch
This updated RWKV contains a total of 6 models, namely:
4 Eagle (RWKV-5) Model: 0.4B, 1.5B, 3B, 7B parameter sizes respectively;
2 Finch (RWKV-6) Model: respectively 1.6B, 3B parameter size.
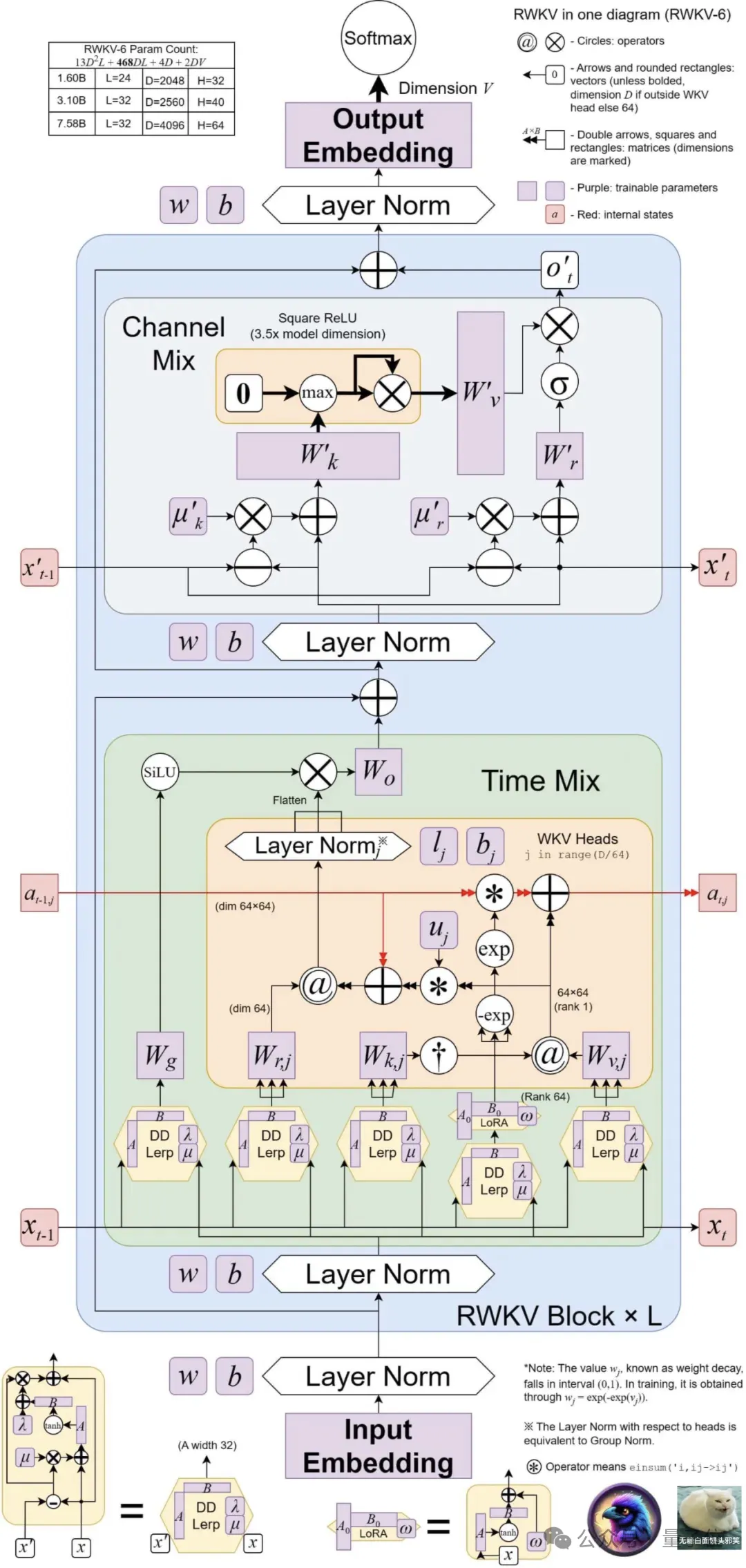
Eagle achieves this by using multiple matrix-valued states (instead of vector-valued states) , reconstructed accepting states, and additional Gating mechanism, improved architecture and learning decay progress learned from RWKV-4.
Finch further improves the performance capabilities and flexibility of the architecture by introducing new data-related functions for time mixing and token shift modules, including Parametric linear interpolation.
In addition, Finch proposes a new use of low-rank adaptive functions to enable trainable weight matrices to effectively enhance the learned data decay vectors in a context-sensitive manner.
Finally, RWKV’s new architecture introduces a new tokenizerRWKV World Tokenizer, and a new data setRWKV World v2, both used to improve the performance of RWKV models on multi-language and code data.
The new tokenizer RWKV World Tokenizer contains words from uncommon languages, and performs rapid word segmentation through Trie-based greedy matching (greedy matching) .
The new data set RWKV World v2 is a new multi-language 1.12T tokens data set, taken from various hand-selected publicly available data sources.
In its data composition, about 70% is English data, 15% is multi-language data, and 15% is code data.
What are the benchmark results?
Architectural innovation alone is not enough, the key lies in the actual performance of the model.
Let’s take a look at the results of the new model on the major authoritative evaluation lists——
MQAR test results
MQAR (Multiple Query Associative Recall) The task is a task used to evaluate language models and is designed to test the model's associative memory ability under multiple queries.
In this type of task, the model needs to retrieve relevant information given multiple queries.
The goal of the MQAR task is to measure the model's ability to retrieve information under multiple queries, as well as its adaptability and accuracy to different queries.
The following figure shows the MQAR task test results of RWKV-4, Eagle, Finch and other non-Transformer architectures.
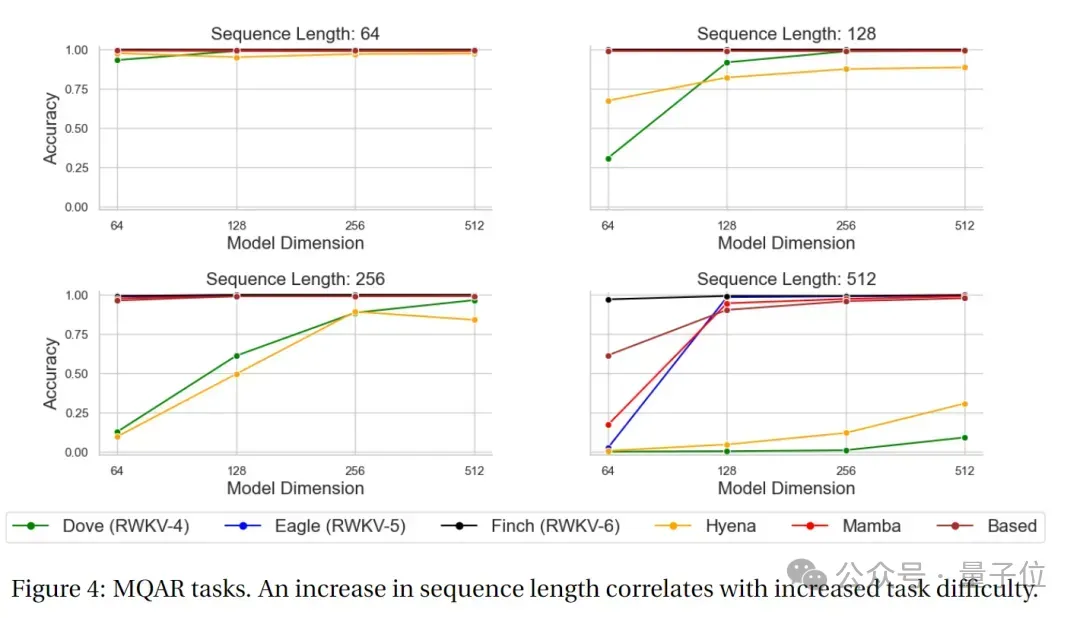
It can be seen that in the accuracy test of the MQAR task, Finch's accuracy performance in various sequence length tests is very stable. Compared with RWKV-4 and RWKV -5 and other non-Transformer architecture models have significant performance advantages.
Long context experiment
The loss and sequence position of RWKV-4, Eagle and Finch starting from 2048 tokens were tested on the PG19 test set.
(All models are pre-trained based on context length 4096) .
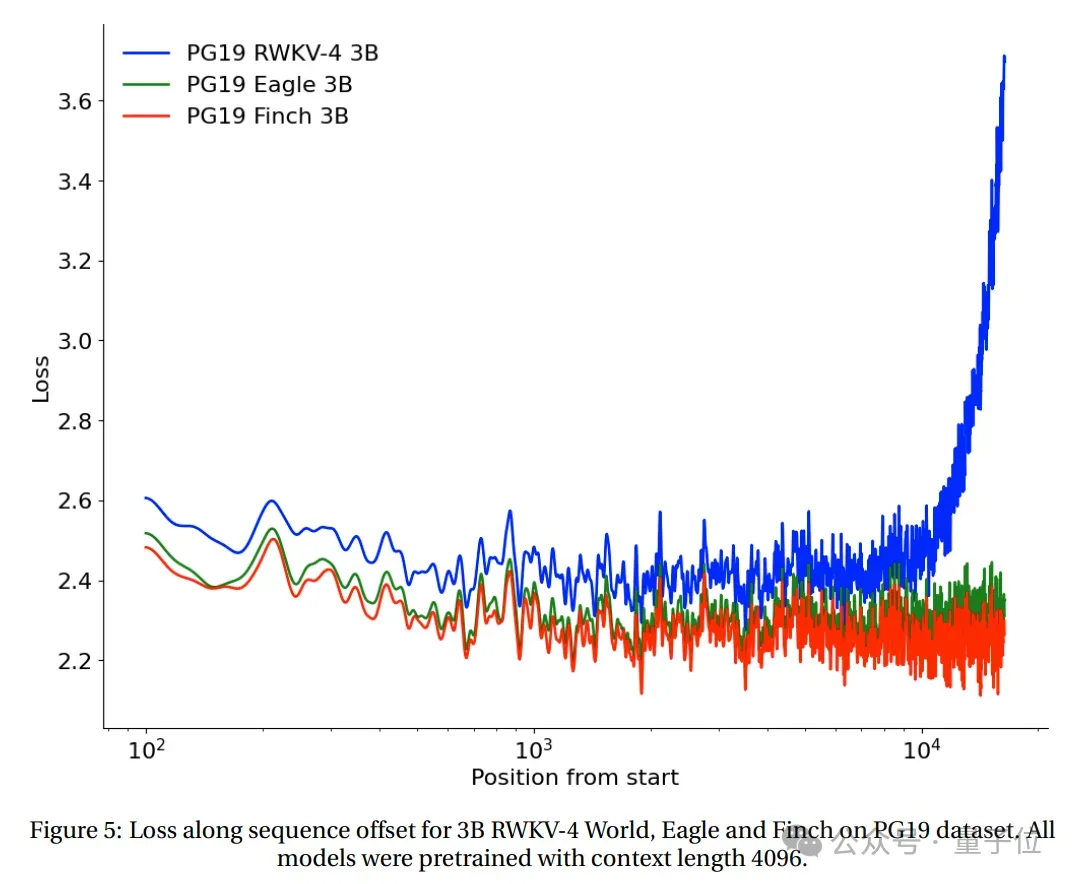
The test results show that Eagle has significant improvements over RWKV-4 on long sequence tasks, and Finch trained at context length 4096 performs better than Eagle, Can automatically adapt well to context lengths above 20,000.
Speed and memory benchmark test
In the speed and memory benchmark test, the team compared the speed and memory utilization of Finch, Mamba and Flash Attention's Attention-like cores.
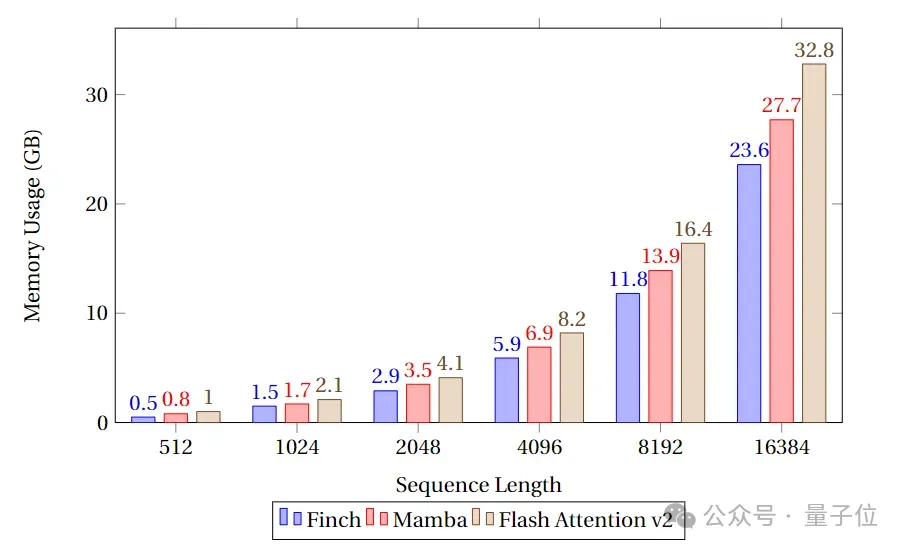
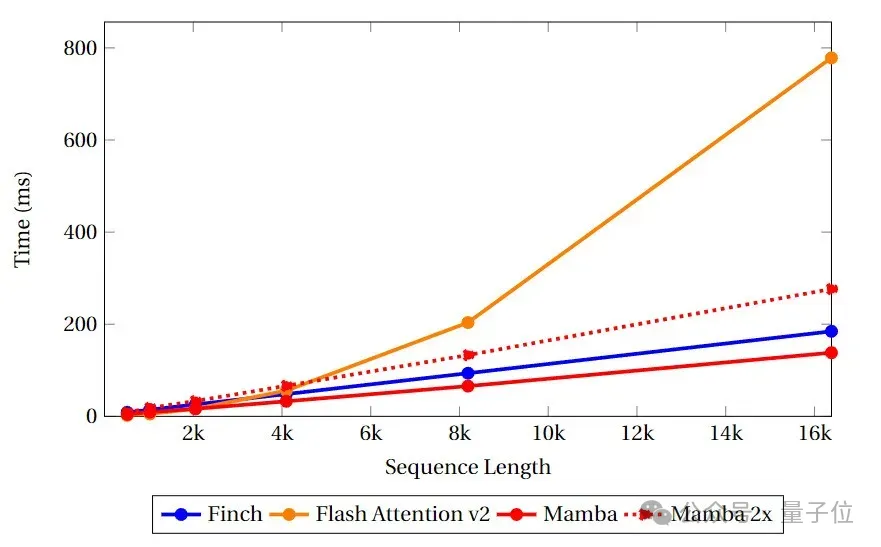
It can be seen that Finch is always better than Mamba and Flash Attention in terms of memory usage, and the memory usage is 40% and 17% less than Flash Attention and Mamba respectively. %.
Multi-language task performance
Japanese

Spanish

Arabic Language

Japanese-English

Next step work
The above research content comes from RWKV Foundation The latest paper released"Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence".
The paper was jointly completed by RWKV founder Bo PENG (Bloomberg) and members of the RWKV open source community.

Co-authored by Bloomberg, graduated from Hong Kong University Department of Physics, has 20 years of programming experience, and worked at Ortus Capital, one of the world's largest foreign exchange hedge funds , responsible for high-frequency quantitative trading.
also published a book about deep convolutional networks "Deep Convolutional Networks·Principles and Practice".
His main focus and interest are in software and hardware development. In previous public interviews, he has made it clear that AIGC is his interest, especially novel generation.
Currently, Bloomberg has 2.1k followers on Github.
But his most important public identity is the co-founder of a lighting company, Linlin Technology, which mainly makes sun lamps, ceiling lamps, portable desk lamps and so on.
And he should be a senior cat lover. There is an orange cat on Github, Zhihu, and WeChat avatars, as well as on the lighting company’s official website homepage and Weibo.

Qubit learned that RWKV’s current multi-modal work includes RWKV Music (music direction) and VisualRWKV (image direction) .
Next, RWKV will focus on the following directions:
- Expand the training corpus, make it more diverse (This is a key thing to improve model performance) ;
- Train and release larger version of Finch, such as 7B and 14B parameters, and reduces inference and training costs through MoE to further expand its performance.
- Further optimize Finch’s CUDA implementation (including algorithm improvements), Bringing speed improvements and greater parallelism.
Paper link:
https://arxiv.org/pdf/2404.05892.pdf
The above is the detailed content of Magically modified RNN challenges Transformer, RWKV is new: launching two new architecture models. For more information, please follow other related articles on the PHP Chinese website!