

 Technology peripheralsAIMultiple SOTAs! OV-Uni3DETR: Improving the generalizability of 3D detection across categories, scenes and modalities (Tsinghua & HKU)
Technology peripheralsAIMultiple SOTAs! OV-Uni3DETR: Improving the generalizability of 3D detection across categories, scenes and modalities (Tsinghua & HKU)
This paper discusses the field of 3D target detection, especially 3D target detection for Open-Vocabulary. In traditional 3D object detection tasks, systems need to predict the localization of 3D bounding boxes and semantic category labels for objects in real scenes, which usually relies on point clouds or RGB images. Although 2D object detection technology performs well due to its ubiquity and speed, relevant research shows that the development of 3D universal detection lags behind in comparison. Currently, most 3D object detection methods still rely on fully supervised learning and are limited by fully annotated data under specific input modes, and can only recognize categories that emerge during training, whether in indoor or outdoor scenes.
This paper points out that the challenges facing 3D universal object detection mainly include: existing 3D detectors can only work with closed vocabulary aggregation, and therefore can only detect categories that have already been seen. Open-Vocabulary's 3D object detection is urgently needed to identify and locate new class object instances not acquired during training. Existing 3D detection datasets are limited in size and category compared to 2D datasets, which limits the generalization ability in locating new objects. In addition, the lack of pre-trained image-text models in the 3D domain further exacerbates the challenges of Open-Vocabulary 3D detection. At the same time, there is a lack of a unified architecture for multi-modal 3D detection, and existing 3D detectors are mostly designed for specific input modalities (point clouds, RGB images, or both), which hinders the effective utilization of data from different modalities. and scene (indoor or outdoor), thus limiting the generalization ability to new targets.
In order to solve the above problems, the paper proposes a unified multi-modal 3D detector called OV-Uni3DETR. The detector is able to utilize multi-modal and multi-source data during training, including point clouds, point clouds with accurate 3D box annotations and point cloud-aligned 3D detection images, and 2D detection images containing only 2D box annotations. Through this multi-modal learning method, OV-Uni3DETR is able to process data of any modality during inference, achieve modal switching during testing, and perform well in detecting basic categories and new categories. The unified structure further enables OV-Uni3DETR to detect in indoor and outdoor scenes, with Open-Vocabulary capabilities, thereby significantly improving the universality of the 3D detector across categories, scenes and modalities.
In addition, aiming at the problem of how to generalize the detector to recognize new categories, and how to learn from a large number of 2D detection images without 3D box annotations, the paper proposes a method called periodic mode propagation approach - With this approach, knowledge is spread between 2D and 3D modalities to address both challenges. In this way, the rich semantic knowledge of the 2D detector can be propagated to the 3D domain to assist in discovering new boxes, and the geometric knowledge of the 3D detector can be used to localize objects in the 2D detection image and match the classification labels through matching .
The main contributions of the paper include proposing a unified Open-Vocabulary 3D detector OV-Uni3DETR that can detect any category of targets in different modalities and diverse scenes; proposing a unified Open-Vocabulary 3D detector for indoor and outdoor scenes. A multi-modal architecture; and the concept of a knowledge propagation cycle between 2D and 3D modalities is proposed. With these innovations, OV-Uni3DETR achieves state-of-the-art performance on multiple 3D detection tasks and significantly outperforms previous methods in the Open-Vocabulary setting. These results show that OV-Uni3DETR has taken an important step for the future development of 3D basic models.

Detailed explanation of OV-Uni3DETR method
Multi-Modal Learning

This article introduces a multi-modal learning framework specifically for 3D object detection tasks, which enhances detection performance by integrating cloud data and image data. This framework can handle certain sensor modalities that may be missing during inference, that is, it also has the ability to switch modes during testing. Features from two different modalities, including 3D point cloud features and 2D image features, are extracted and integrated through a specific network structure. After elemental processing and camera parameter mapping, these features are fused for subsequent target detection tasks.
Key technical points include using 3D convolution and batch normalization to normalize and integrate features of different modes to prevent inconsistencies at the feature level from causing a certain mode to be ignored. In addition, the training strategy of randomly switching modes ensures that the model can flexibly process data from only a single mode, thereby improving the robustness and adaptability of the model.
Ultimately, the architecture utilizes a composite loss function that combines losses from class prediction, 2D and 3D bounding box regression, and an uncertainty prediction for a weighted regression loss to optimize the entire detection process. This multi-modal learning method not only improves the detection performance of existing categories, but also enhances the generalization ability to new categories by fusing different types of data. The multi-modal architecture ultimately predicts class labels, 4D 2D boxes and 7D 3D boxes for 2D and 3D object detection. For 3D box regression, L1 loss and decoupled IoU loss are used; for 2D box regression, L1 loss and GIoU loss are used. In the Open-Vocabulary setting, there are new category samples, which increases the difficulty of training samples. Therefore, uncertainty prediction is introduced and used to weight the L1 regression loss. The loss of object detection learning is:
is introduced and used to weight the L1 regression loss. The loss of object detection learning is:
For some 3D scenes, there may be multi-view images instead of a single monocular image. For each of them, image features are extracted and projected into voxel space using the respective projection matrix. Multiple image features in voxel space are summed to obtain multimodal features. This approach improves the model's generalization ability to new categories and enhances adaptability under diverse input conditions by combining information from different modalities.
Knowledge Propagation: 2D—3D
Based on the multi-modal learning introduced, this article implements a method called "knowledge Propagation" for Open-Vocabulary's 3D detection. Propagation:  " method. The core problem of Open-Vocabulary learning is to identify new categories that have not been manually labeled during the training process. Due to the difficulty of obtaining point cloud data, pre-trained visual-language models have not yet been developed in the point cloud field. The modal differences between point cloud data and RGB images limit the performance of these models in 3D detection.
" method. The core problem of Open-Vocabulary learning is to identify new categories that have not been manually labeled during the training process. Due to the difficulty of obtaining point cloud data, pre-trained visual-language models have not yet been developed in the point cloud field. The modal differences between point cloud data and RGB images limit the performance of these models in 3D detection.

To solve this problem, we propose to utilize the semantic knowledge of pre-trained 2D Open-Vocabulary detectors and generate corresponding 3D bounding boxes for new categories. These generated 3D boxes will complement the limited 3D ground-truth labels available during training.
Specifically, a 2D bounding box or instance mask is first generated using the 2DOpen-Vocabulary detector. Considering that the data and annotations available in the 2D domain are richer, these generated 2D boxes can achieve higher positioning accuracy and cover a wider range of categories. Then, these 2D boxes are projected into 3D space by  to obtain the corresponding 3D boxes. The specific operation is to use
to obtain the corresponding 3D boxes. The specific operation is to use 
to project 3D points into 2D space, find the points in the 2D box, and then cluster these points in the 2D box to eliminate outliers, thereby obtaining the corresponding 3D frame. Due to the presence of pre-trained 2D detectors, new unlabeled objects can be discovered in the generated 3D box set. In this way, 3DOpen-Vocabulary detection is greatly facilitated by the rich semantic knowledge propagated from the 2D domain to the generated 3D boxes. For multi-view images, 3D boxes are generated separately and integrated together for final use.
During inference, when both point clouds and images are available, 3D boxes can be extracted in a similar manner. These generated 3D boxes can also be regarded as a form of 3DOpen-Vocabulary detection results. These 3D boxes are added to the predictions of the multimodal 3D transformer to supplement possible missing objects and filter overlapping bounding boxes via 3D non-maximum suppression (NMS). The confidence score assigned by the pretrained 2D detector is systematically divided by a predetermined constant and then reinterpreted as the confidence score of the corresponding 3D box.
experiment

The table shows the performance of OV-Uni3DETR for Open-Vocabulary3D object detection on SUN RGB-D and ScanNet datasets. The experimental settings are exactly the same as CoDA, and the data used comes from the officially released code of CoDA. Performance indicators include new category average accuracy , base class average accuracy
, base class average accuracy and all classes average accuracy
and all classes average accuracy . Input types include point clouds (P), images (I), and their combinations (PI).
. Input types include point clouds (P), images (I), and their combinations (PI).
Analyzing these results, we can observe the following points:
-
Advantages of multi-modal input: When using a combination of point clouds and images as input At that time, OV-Uni3DETR achieved the highest scores in all evaluation indicators of the two data sets, especially the most significant improvement in the average accuracy
 of the new category. This shows that combining point clouds and images can significantly improve the model's ability to detect unseen classes, as well as the overall detection performance.
of the new category. This shows that combining point clouds and images can significantly improve the model's ability to detect unseen classes, as well as the overall detection performance. - Comparison with other methods: Comparison with other point cloud-based methods (such as Det-PointCLIP, Det-PointCLIPv2, Det-CLIP, 3D-CLIP and CoDA ), OV-Uni3DETR shows excellent performance in all evaluation indicators. This demonstrates the effectiveness of OV-Uni3DETR in handling Open-Vocabulary3D object detection tasks, especially in leveraging multi-modal learning and knowledge dissemination strategies.
- Comparison of image and point cloud input: Although OV-Uni3DETR using only image (I) as input is lower in performance than using point cloud (P) as input, Still shows good detection capabilities. This proves the flexibility and adaptability of the OV-Uni3DETR architecture to single modal data, and also emphasizes the importance of fusing multiple modal data to improve detection performance.
-
Performance on new categories: The performance of OV-Uni3DETR on new category average accuracy is particularly worthy of attention, which is particularly critical for Open-Vocabulary detection. On the SUN RGB-D dataset, the achieved 12.96% when using point cloud and image input, and 15.21% on the ScanNet dataset, which is significantly higher than other methods, showing its improvement in the recognition training process. Powerful capabilities in a category never seen before.
 of the new category. This shows that combining point clouds and images can significantly improve the model's ability to detect unseen classes, as well as the overall detection performance.
of the new category. This shows that combining point clouds and images can significantly improve the model's ability to detect unseen classes, as well as the overall detection performance.  is particularly worthy of attention, which is particularly critical for Open-Vocabulary detection. On the SUN RGB-D dataset, the
is particularly worthy of attention, which is particularly critical for Open-Vocabulary detection. On the SUN RGB-D dataset, the  achieved 12.96% when using point cloud and image input, and 15.21% on the ScanNet dataset, which is significantly higher than other methods, showing its improvement in the recognition training process. Powerful capabilities in a category never seen before.
achieved 12.96% when using point cloud and image input, and 15.21% on the ScanNet dataset, which is significantly higher than other methods, showing its improvement in the recognition training process. Powerful capabilities in a category never seen before. Overall, OV-Uni3DETR shows excellent performance on Open-Vocabulary3D object detection tasks through its unified multi-modal learning architecture, especially when combining point cloud and image data At the same time, it can effectively improve the detection ability of new categories, proving the effectiveness and importance of multi-modal input and knowledge dissemination strategies.

This table shows the performance of OV-Uni3DETR for Open-Vocabulary3D object detection on the KITTI and nuScenes datasets, covering what has been seen during the training process (base) and Novel categories. For the KITTI dataset, the "car" and "cyclist" categories were seen during training, while the "pedestrian" category is novel. Performance is measured using the 
metric at medium difficulty, using 11 recall positions. For the nuScenes data set, "car, trailer, construction vehicle, motorcycle, bicycle" is a seen category, and the remaining five are unseen categories. In addition to AP indicators, NDS (NuScenes Detection Score) is also reported to comprehensively evaluate detection performance.
Analyzing these results, the following conclusions can be drawn:
- 多模态输入的显著优势:与仅使用点云(P)或图像(I)作为输入的情况相比,当同时使用点云和图像(P I)作为输入时,OV-Uni3DETR在所有评价指标上都获得了最高分。这一结果强调了多模态学习在提高对未见类别检测能力和整体检测性能方面的显著优势。
- Open-Vocabulary检测的有效性:OV-Uni3DETR在处理未见类别时展现出了出色的性能,尤其是在KITTI数据集的"pedestrian"类别和nuScenes数据集的"novel"类别上。这表明了模型对新颖类别具有很强的泛化能力,是一个有效的Open-Vocabulary检测解决方案。
- 与其他方法的对比:与其他基于点云的方法相比(如Det-PointCLIP、Det-PointCLIPv2和3D-CLIP),OV-Uni3DETR展现出了显著的性能提升,无论是在已见还是未见类别的检测上。这证明了其在处理Open-Vocabulary3D目标检测任务上的先进性。
- 图像输入与点云输入的对比:尽管使用图像输入的性能略低于使用点云输入,但图像输入仍然能够提供相对较高的检测精度,这表明了OV-Uni3DETR架构的适应性和灵活性。
- 综合评价指标:通过NDS评价指标的结果可以看出,OV-Uni3DETR不仅在识别准确性上表现出色,而且在整体检测质量上也取得了很高的分数,尤其是在结合点云和图像数据时。
OV-Uni3DETR在Open-Vocabulary3D目标检测上展示了卓越的性能,特别是在处理未见类别和多模态数据方面。这些结果验证了多模态输入和知识传播策略的有效性,以及OV-Uni3DETR在提升3D目标检测任务泛化能力方面的潜力。
讨论

这篇论文通过提出OV-Uni3DETR,一个统一的多模态3D检测器,为Open-Vocabulary的3D目标检测领域带来了显著的进步。该方法利用了多模态数据(点云和图像)来提升检测性能,并通过2D到3D的知识传播策略,有效地扩展了模型对未见类别的识别能力。在多个公开数据集上的实验结果证明了OV-Uni3DETR在新类别和基类上的出色性能,尤其是在结合点云和图像输入时,能够显著提高对新类别的检测能力,同时在整体检测性能上也达到了新的高度。
优点方面,OV-Uni3DETR首先展示了多模态学习在提升3D目标检测性能中的潜力。通过整合点云和图像数据,模型能够从每种模态中学习到互补的特征,从而在丰富的场景和多样的目标类别上实现更精确的检测。其次,通过引入2D到3D的知识传播机制,OV-Uni3DETR能够利用丰富的2D图像数据和预训练的2D检测模型来识别和定位训练过程中未见过的新类别,这大大提高了模型的泛化能力。此外,该方法在处理Open-Vocabulary检测时显示出的强大能力,为3D检测领域带来了新的研究方向和潜在应用。
缺点方面,虽然OV-Uni3DETR在多个方面展现了其优势,但也存在一些潜在的局限性。首先,多模态学习虽然能提高性能,但也增加了数据采集和处理的复杂性,尤其是在实际应用中,不同模态数据的同步和配准可能会带来挑战。其次,尽管知识传播策略能有效利用2D数据来辅助3D检测,但这种方法可能依赖于高质量的2D检测模型和准确的3D-2D对齐技术,这在一些复杂环境中可能难以保证。此外,对于一些极其罕见的类别,即使是Open-Vocabulary检测也可能面临识别准确性的挑战,这需要进一步的研究来解决。
OV-Uni3DETR通过其创新的多模态学习和知识传播策略,在Open-Vocabulary3D目标检测上取得了显著的进展。虽然存在一些潜在的局限性,但其优点表明了这一方法在推动3D检测技术发展和应用拓展方面的巨大潜力。未来的研究可以进一步探索如何克服这些局限性,以及如何将这些策略应用于更广泛的3D感知任务中。
结论
在本文中,我们主要提出了OV-Uni3DETR,一种统一的多模态开放词汇三维检测器。借助于多模态学习和循环模态知识传播,我们的OV-Uni3DETR很好地识别和定位了新类,实现了模态统一和场景统一。实验证明,它在开放词汇和封闭词汇环境中,无论是室内还是室外场景,以及任何模态数据输入中都有很强的能力。针对多模态环境下统一的开放词汇三维检测,我们相信我们的研究将推动后续研究沿着有希望但具有挑战性的通用三维计算机视觉方向发展。
The above is the detailed content of Multiple SOTAs! OV-Uni3DETR: Improving the generalizability of 3D detection across categories, scenes and modalities (Tsinghua & HKU). For more information, please follow other related articles on the PHP Chinese website!

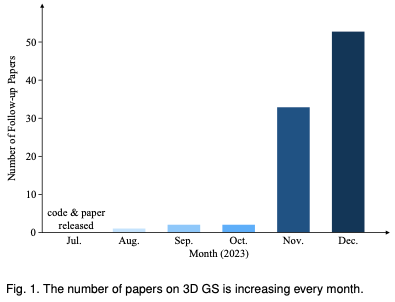 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
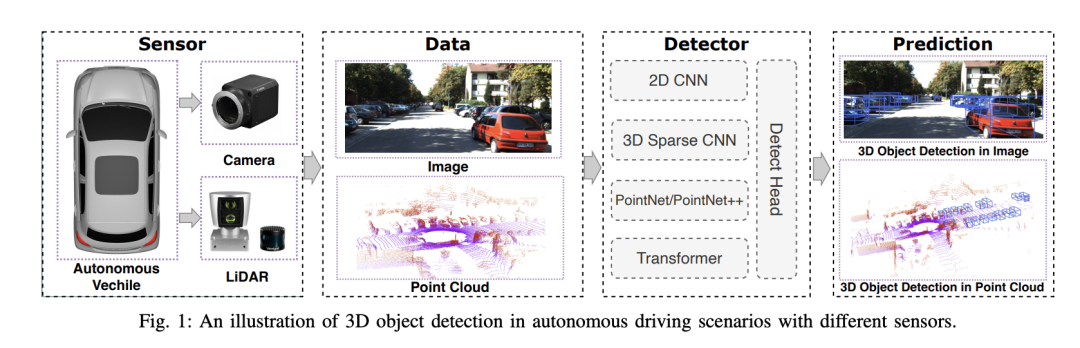 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PMChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
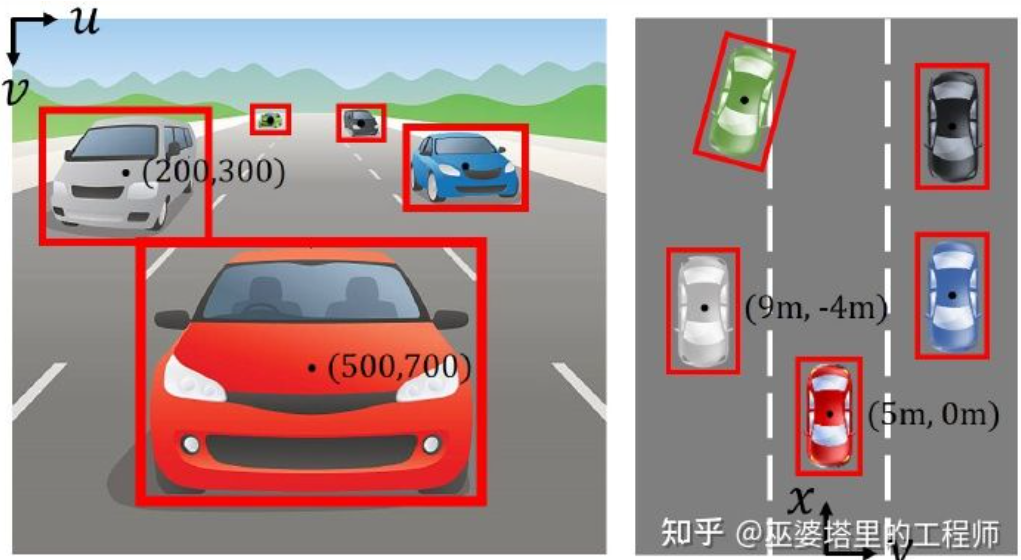 自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景
 《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Dreamweaver Mac version
Visual web development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Linux new version
SublimeText3 Linux latest version

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

