

 Technology peripheralsAIEfficiency increased by 16 times! VRSO: 3D annotation of purely visual static objects, opening up the data closed loop!
Technology peripheralsAIEfficiency increased by 16 times! VRSO: 3D annotation of purely visual static objects, opening up the data closed loop!Efficiency increased by 16 times! VRSO: 3D annotation of purely visual static objects, opening up the data closed loop!

The Sorrow of Annotation
Static object detection (SOD), including traffic lights, guide signs and traffic cones, most algorithms are data-driven deep neural networks and require a large amount of training data. Current practice typically involves manual annotation of large numbers of training samples on LiDAR-scanned point cloud data to fix long-tail cases.

Manual annotation is difficult to capture the variability and complexity of real scenes, and often fails to take into account occlusions, different lighting conditions and diverse viewing angles (yellow arrow in Figure 1) . The whole process has long links, is extremely time-consuming, error-prone, and costly (Figure 2). So currently companies are looking for automatic labeling solutions, especially based on pure vision. After all, not every car has lidar.

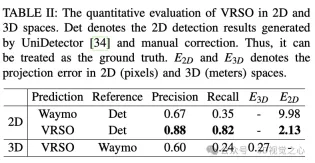
VRSO is a vision-based annotation system for static object annotation. It mainly uses information from SFM, 2D object detection and instance segmentation results. Overall effect: The average projection error of
- annotations is only 2.6 pixels, which is about a quarter of Waymo annotations (10.6 pixels)
- Compared with manual annotation, the speed is improved About 16 times
For static objects, VRSO solves the challenge of integrating and deduplicating static objects from different viewing angles through instance segmentation and contour extraction of key points, as well as the difficulty of insufficient observation due to occlusion issues , thus improving the accuracy of labeling. From Figure 1, compared with the manual annotation results of the Waymo Open dataset, VRSO demonstrates higher robustness and geometric accuracy.
(You’ve all seen this, why not slide your thumb up and click on the top card to follow me. The whole operation will only take you 1.328 seconds, and then take away all the useful information in the future. What if it works~)
How to break the situation
The VRSO system is mainly divided into two parts: Scene reconstruction and Static objects are marked .
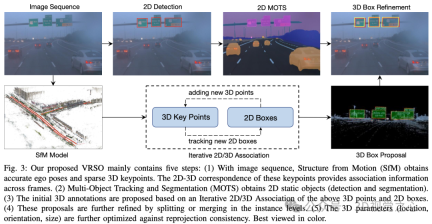
#The reconstruction part is not the focus, it is based on the SFM algorithm to restore the image pose and sparse 3D key points.
Static object annotation algorithm, combined with pseudo code, the general process is (the following will be detailed step by step):
- Use ready-made 2D object detection and segmentation algorithms to generate candidates
- Use the 3D-2D keypoint correspondence in the SFM model to track 2D instances across frames
- Introduce reprojection consistency to optimize the 3D annotation parameters of static objects

1. Tracking association
- #step 1: Extract 3D points within the 3D bounding box based on the key points of the SFM model.
- step 2: Calculate the coordinates of each 3D point on the 2D map based on the 2D-3D matching relationship.
- step 3: Determine the corresponding instance of the 3D point on the current 2D map based on the 2D map coordinates and instance segmentation corner points.
- step 4: Determine the correspondence between 2D observations and 3D bounding boxes for each 2D image.
2.proposal generation
Initialize the 3D frame parameters (position, direction, size) of the static object for the entire video clip. Each key point of SFM has an accurate 3D position and corresponding 2D image. For each 2D instance, feature points within the 2D instance mask are extracted. Then, a set of corresponding 3D keypoints can be considered as candidates for 3D bounding boxes.
Street signs are represented as rectangles with directions in space, which have 6 degrees of freedom, including translation (,,), direction (θ) and size (width and height). Given its depth, a traffic light has 7 degrees of freedom. Traffic cones are represented similarly to traffic lights.
3.proposal refine
- step 1: Extract the outline of each static object from 2D instance segmentation.
- step 2: Fit the minimum oriented bounding box (OBB) for the contour outline.
- step 3: Extract the vertices of the minimum bounding box.
- step 4: Calculate the direction based on the vertices and center points, and determine the vertex order.
- step 5: The segmentation and merging process is performed based on the 2D detection and instance segmentation results.
- step 6: Detect and reject observations containing occlusions. Extracting vertices from the 2D instance segmentation mask requires that all four corners of each sign are visible. If there are occlusions, axis-aligned bounding boxes (AABBs) are extracted from the instance segmentation and the area ratio between AABBs and 2D detection boxes is calculated. If there are no occlusions, these two area calculation methods should be close.
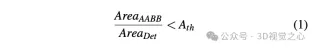
4. Triangulation
Obtain the initial vertex value of the static object under 3D conditions through triangulation.
By checking the number of keypoints in the 3D bounding boxes obtained by SFM and instance segmentation during scene reconstruction, only instances with the number of keypoints exceeding the threshold are considered stable and valid observations. For these instances, the corresponding 2D bounding box is considered a valid observation. Through 2D observation of multiple images, the vertices of the 2D bounding box are triangulated to obtain the coordinates of the bounding box.
For circular signs that do not distinguish the "lower left, upper left, upper right, upper right, and lower right" vertices on the mask, these circular signs need to be identified. 2D detection results are used as observations of circular objects, and 2D instance segmentation masks are used for contour extraction. The center point and radius are calculated through a least squares fitting algorithm. The parameters of the circular sign include the center point (,,), direction (θ) and radius ().
5.tracking refine
Tracking feature point matching based on SFM. Determine whether to merge these separated instances based on the Euclidean distance of the 3D bounding box vertices and the 2D bounding box projection IoU. Once merging is complete, 3D feature points within an instance can be clustered to associate more 2D feature points. Iterative 2D-3D association is performed until no 2D feature points can be added.
6. Final parameter optimization
Taking the rectangular sign as an example, the parameters that can be optimized include position (,,) and direction (θ) and size (,), for a total of six degrees of freedom. The main steps include:
- Convert six degrees of freedom into four 3D points and calculate the rotation matrix.
- Project the converted four 3D points onto the 2D image.
- Calculate the residual between the projection result and the corner point result obtained by instance segmentation.
- Use Huber to optimize and update bounding box parameters
Labeling effect


There are also some challenging long-tail cases, such as extremely low resolution and insufficient lighting.

To summarize
The VRSO framework achieves high-precision and consistent 3D annotation of static objects, tightly integrating detection, segmentation and The SFM algorithm eliminates manual intervention in intelligent driving annotation and provides results comparable to LiDAR-based manual annotation. Qualitative and quantitative evaluations were conducted with the widely recognized Waymo Open Dataset: compared with manual annotation, the speed is increased by about 16 times, while maintaining the best consistency and accuracy.
The above is the detailed content of Efficiency increased by 16 times! VRSO: 3D annotation of purely visual static objects, opening up the data closed loop!. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

SublimeText3 Linux new version
SublimeText3 Linux latest version

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SublimeText3 English version
Recommended: Win version, supports code prompts!

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

