

 Technology peripheralsAIOpen source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Technology peripheralsAIOpen source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!

0.この記事は何をするのですか?
提案された DepthFM: 多用途かつ高速な最先端の生成単眼深度推定モデル 。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。
この作品を一緒に読みましょう~
1. 論文情報
タイトル: DepthFM: フローマッチングによる高速単眼深度推定
著者: Ming Gui、Johannes S. Fischer、Ulrich Prestel、Pingchuan Ma、Dmytrokotovenko、Olga Grebenkova、Stefan Andreas Baumann、Vincent Tao Hu、Björn Ommer
機関: MCML
元のリンク: https://arxiv.org/abs/2403.13788
コードリンク: https://github.com/CompVis/ Depth-fm
公式ホームページ: https:// Depthfm.github .io/
2. 要約
は、下流の観光タスクやアプリケーションの多くにとって重要です。この問題に対する現在の識別方法は不鮮明なアーティファクトによって制限されていますが、最先端の生成方法は SDE の性質によりトレーニング サンプル速度が遅いという問題があります。ノイズから始めるのではなく、入力画像から深度画像への直接マッピングを求めます。解空間内の直線軌道が効率と高品質を提供するため、これはフロー マッチングによって効率的に構築できることがわかりました。私たちの研究は、事前トレーニングされた画像拡散モデルがフローマッチングの深いモデルのための十分な事前知識として使用できることを示しています。複雑な自然シーンのベンチマークでは、私たちの軽量アプローチは、少量の合成データのみでトレーニングされているにもかかわらず、有利な低計算コストで最先端のパフォーマンスを実証します。
3. 効果のデモ
DepthFM は、強力なゼロサンプル汎化機能を備えた高速推論フロー マッチング モデルで、強力な事前知識を利用でき、非常に使いやすいです。 . 未知の実像に簡単に一般化できます。合成データでトレーニングした後、モデルは未知の実際の画像に対して適切に一般化され、深度画像と正確に一致します。

他の最先端のモデルと比較して、DepthFM は 1 回の関数評価のみで非常に鮮明な画像を取得します。 Marigold の深度推定には DethFM の 2 倍の時間がかかりますが、同じ粒度で深度マップを生成することはできません。

4. 主な貢献
(1) 最先端の多機能高速単眼鏡DepthFMの提案深度推定モデル。従来の深度推定タスクに加えて、DepthFM は、深度修復や深度条件付き画像合成などの下流タスクでも最先端の機能を実証します。
(2) は、トレーニング データにほとんど依存せず、実世界の画像を必要とせずに、拡散モデルからフロー マッチング モデルへの強力な画像事前分布の転送が成功したことを示しています。
(3) は、フロー マッチング モデルが効率的であり、単一の推論ステップ内で深度マップを合成できることを示しています。
(4) DepthFM は合成データのみでトレーニングされているにもかかわらず、ベンチマーク データセットと自然画像で良好なパフォーマンスを発揮します。
(5) 表面法線損失を補助ターゲットとして使用して、より正確な深度推定を取得します。
(6) 深さの推定に加えて、その予測の信頼性も確実に予測できます。
5. 具体的な原則は何ですか?
トレーニング パイプライン。 トレーニングは、フロー マッチングと表面法線損失によって制限されます。フロー マッチングの場合、データ依存のフロー マッチングを使用して、グラウンド トゥルースの深さと対応する画像の間のベクトル フィールドを回帰します。さらに、表面法線の損失によって幾何学的なリアリズムが実現されます。

データ関連のフロー マッチング: DepthFM は、画像と深度のペアを利用して、画像分布と深度分布の間の直線ベクトル場を回帰します。このアプローチにより、パフォーマンスを犠牲にすることなく、効率的な複数ステップの推論が促進されます。
拡散事前分布からの微調整: 著者らは、強力な画像事前分布を基本画像合成拡散モデル (安定拡散 v2-1) からフロー マッチング モデルにほとんど変換せずに転送することに成功したことを実証します。依存関係トレーニング データを使用するため、現実世界の画像は必要ありません。
補助表面法線損失: DepthFM が合成データでのみトレーニングされていることを考慮すると、ほとんどの合成データ セットはグラウンド トゥルースの表面法線を提供し、表面法線損失は補助ターゲットとして使用されます。 DepthFM 深度推定の精度を向上させます。
6. Experimental results
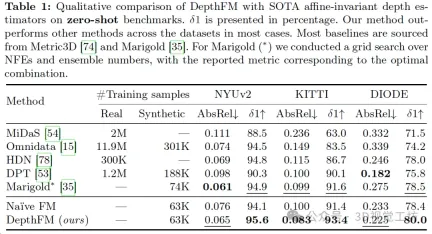
DepthFM demonstrates significant generalization ability by training only on 63k purely synthetic samples, and is able to perform zero-level training on indoor and outdoor data sets. - Shot depth estimation. Table 1 qualitatively shows the performance comparison of DepthFM with state-of-the-art corresponding models. While other models often rely on large datasets for training, DepthFM leverages the rich knowledge inherent in the underlying diffusion-based model. This method not only saves computing resources, but also emphasizes the adaptability and training efficiency of the model.
Comparison of diffusion-based Marigold depth estimation, Flow Matching (FM) benchmark and DepthFM model. Each method is evaluated using only one ensemble member and with varying numbers of function evaluations (NFE) on two common benchmark datasets. Compared with the FM baseline, DepthFM integrates normal loss and data-dependent coupling during training.
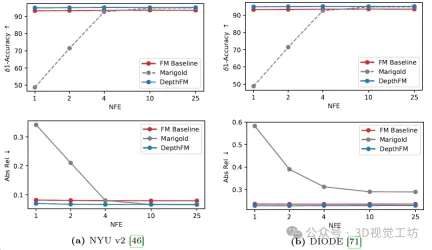
Qualitative results for Marigold and DepthFM models in different numbers of functional evaluations. It is worth noting that Marigold does not give any meaningful results through one-step inference, while the results of DepthFM already show the real depth map.

Perform deep completion on Hypersim. Left: Giving some depth. Medium: Depth estimated from the given partial depth. Right: True depth.

#7. Summary
DepthFM, a flow matching method for monocular depth estimation. By learning a direct mapping between the input image and depth, rather than denoising a normal distribution into a depth map, this approach is significantly more efficient than current diffusion-based solutions while still providing fine-grained depth maps without Common artifacts of the discriminative paradigm. DepthFM uses a pre-trained image diffusion model as a prior, effectively transferring it to a deep flow matching model. Therefore, DepthFM is only trained on synthetic data but still generalizes well to natural images during inference. Additionally, auxiliary surface normal loss has been shown to improve depth estimation. DepthFM's lightweight approach is competitive, fast, and provides reliable confidence estimates.
Readers who are interested in more experimental results and article details can read the original paper
The above is the detailed content of Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!. For more information, please follow other related articles on the PHP Chinese website!

 From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AM
From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AMThe legal tech revolution is gaining momentum, pushing legal professionals to actively embrace AI solutions. Passive resistance is no longer a viable option for those aiming to stay competitive. Why is Technology Adoption Crucial? Legal professional
 This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AM
This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AMMany assume interactions with AI are anonymous, a stark contrast to human communication. However, AI actively profiles users during every chat. Every prompt, every word, is analyzed and categorized. Let's explore this critical aspect of the AI revo
 7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AM
7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AMA successful artificial intelligence strategy cannot be separated from strong corporate culture support. As Peter Drucker said, business operations depend on people, and so does the success of artificial intelligence. For organizations that actively embrace artificial intelligence, building a corporate culture that adapts to AI is crucial, and it even determines the success or failure of AI strategies. West Monroe recently released a practical guide to building a thriving AI-friendly corporate culture, and here are some key points: 1. Clarify the success model of AI: First of all, we must have a clear vision of how AI can empower business. An ideal AI operation culture can achieve a natural integration of work processes between humans and AI systems. AI is good at certain tasks, while humans are good at creativity and judgment
 Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AMMeta upgrades AI assistant application, and the era of wearable AI is coming! The app, designed to compete with ChatGPT, offers standard AI features such as text, voice interaction, image generation and web search, but has now added geolocation capabilities for the first time. This means that Meta AI knows where you are and what you are viewing when answering your question. It uses your interests, location, profile and activity information to provide the latest situational information that was not possible before. The app also supports real-time translation, which completely changed the AI experience on Ray-Ban glasses and greatly improved its usefulness. The imposition of tariffs on foreign films is a naked exercise of power over the media and culture. If implemented, this will accelerate toward AI and virtual production
 Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AM
Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AMArtificial intelligence is revolutionizing the field of cybercrime, which forces us to learn new defensive skills. Cyber criminals are increasingly using powerful artificial intelligence technologies such as deep forgery and intelligent cyberattacks to fraud and destruction at an unprecedented scale. It is reported that 87% of global businesses have been targeted for AI cybercrime over the past year. So, how can we avoid becoming victims of this wave of smart crimes? Let’s explore how to identify risks and take protective measures at the individual and organizational level. How cybercriminals use artificial intelligence As technology advances, criminals are constantly looking for new ways to attack individuals, businesses and governments. The widespread use of artificial intelligence may be the latest aspect, but its potential harm is unprecedented. In particular, artificial intelligence
 A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AM
A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AMThe intricate relationship between artificial intelligence (AI) and human intelligence (NI) is best understood as a feedback loop. Humans create AI, training it on data generated by human activity to enhance or replicate human capabilities. This AI
 AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AM
AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AMAnthropic's recent statement, highlighting the lack of understanding surrounding cutting-edge AI models, has sparked a heated debate among experts. Is this opacity a genuine technological crisis, or simply a temporary hurdle on the path to more soph
 Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AM
Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AMIndia is a diverse country with a rich tapestry of languages, making seamless communication across regions a persistent challenge. However, Sarvam’s Bulbul-V2 is helping to bridge this gap with its advanced text-to-speech (TTS) t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

WebStorm Mac version
Useful JavaScript development tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Linux new version
SublimeText3 Linux latest version

Zend Studio 13.0.1
Powerful PHP integrated development environment

