

 Technology peripheralsAIMy leader Musk: Hates meetings, doesn't want non-technical middle managers, and advocates layoffs
Technology peripheralsAIMy leader Musk: Hates meetings, doesn't want non-technical middle managers, and advocates layoffs
Musk is already famous for being a "devil boss".
Now, his old subordinate Karpathy (Andrej Karpathy) "hammered" him again (doge) in the latest interview:
I have to Begging him to allow me to recruit people.
He(Musk) always defaults to laying off employees.

In addition to layoffs, Kapasi also revealed more details about Musk’s management company at the AI Ascent event organized by Sequoia:
Hates meetings, refuses to lie down, prefers to talk about work directly with engineers than with VPs...
In addition, he also talked about many big model topics that everyone cares about, including:
- LLM OS
- Does size matter?
- How can young startups compete with OpenAI?
For more details, the text version is shared below~
(Claude 3 also contributed)
Large language model is new Times CPU
Q: Andre, thank you so much for joining us today. OpenAI's original offices were across the street from our San Francisco offices, and many of you were crowded together.
Besides working upstairs in a chocolate factory and living Willy Wonka’s dream, what are some of your most memorable moments working here?
KAPASI: Yes, OpenAI’s original office was there, if you don’t count Greg’s apartment.
We stayed there for about two years. There was a chocolate factory downstairs and the smell was always delicious. At that time, the team had about 10-20 people.
We had a really fun time there. Lao Huang mentioned at the GTC conference that he sent the first DGX supercomputer to OpenAI, which happened there.

Q: Andre actually needs no introduction, but I still want to mention his background. He studied under Geoffrey Hinton and Li Feifei, and first became famous for his deep learning courses at Stanford University.
In 2015, he co-founded OpenAI. In 2017, he was poached by Musk.
You may not remember the situation at that time: Tesla has experienced 6 Autopilot leaders, each of whom only worked for 6 months. I remember when Andre took over the position, I wished him good luck.
It didn’t take long for him to return to OpenAI. But now he has complete freedom and can do whatever he wants. So we're looking forward to hearing the insights he shares today.
What I admire most about Andre is that he is a fascinating futuristic thinker, a staunch optimist, and at the same time a very pragmatic builder. Today he will share some insights on these aspects with us.
First of all, even 7 years ago, AGI seemed like an almost impossible goal to achieve in our lifetime. And now it seems to be in sight. What do you see in the next 10 years?
Kapasi: You are right. A few years ago, the path of AGI was still very unclear and was still in a very academic discussion stage. But now it's clear, and everyone is working hard to fill the void.
Optimization work is in full swing. Roughly speaking, everyone is trying to build "Large Model Operating System (LLM OS)".
I like to compare it to an operating system. You need to prepare various peripherals and connect them to a new CPU. These peripheral devices include various modalities such as text, images, and audio. The CPU is the language model itself. It also connects to all the Software 1.0 infrastructure we've built.
I think everyone is trying to build something like this and then customize it into a product that works in every sector of the economy.
In general, the development direction is that we can adjust these relatively independent agents, assign them high-level tasks, and let them specialize in various tasks. This will be very interesting and exciting. And there is not just one agent, there will be many agents. Imagine what that would be like?

Q: If the future is really what you said, how should we adjust our lifestyle now?
Kapasi: I don’t know. I think we have to work hard to build it, to influence it, to make sure it's positive. In short, try to make the results as good as possible.
Q: Since you are now a free man, I would like to raise an obvious issue, that is, OpenAI is dominating the entire ecosystem.
Most of the people here today are entrepreneurs trying to carve out some niche and praying that OpenAI doesn’t knock them out of business overnight.
Do you think there is still a chance? In what areas will OpenAI continue to dominate?
Kapasi: My overall impression is that OpenAI is working hard to build an LLM operating system. As we heard earlier today, OpenAI is trying to develop a platform. On this basis, you can build different companies in different verticals.
The operating system analogy is actually very interesting, because operating systems like Windows also come with some default applications, such as browsers.
So I think OpenAI or other companies may also launch some default applications, but that doesn’t mean you can’t run different browsers on them, you can run different browsers on top of them agent.
There will be some default apps, but there will also likely be a vibrant ecosystem with a variety of apps fine-tuned for specific scenarios.
I like the analogy of early iPhone apps. These apps all start out as a bit of a joke and take time to develop. I think we're going through the same thing right now. People are trying to figure out what is this thing good at? What are you not good at? How do I use it? How to program? How to debug? How to make it perform actual tasks? What kind of supervision is required? Because it is quite autonomous, but not completely autonomous. So what should supervision look like? What should the assessment look like? There is a lot to think about and understand. I think it will take some time to figure out how to work with this new infrastructure. So I think we'll see that in the next few years.
Q: The competition for large language models is now in full swing, including OpenAI, Anthropic, Mistral, Llama, Gemini, the entire open source model ecosystem, and a large number of small models. How do you foresee the future development of the ecosystem?
KAPASI: Yeah, so again, the operating system analogy is interesting. We have closed source systems such as Windows and macOS, as well as open source Linux. I think the big model might have the same pattern. We must also be careful when calling these models. Many of the models you listed, such as Llama, Mistral, etc., I do not think they are truly open source. It's like throwing out an operating system binary that you can use, but isn't entirely useful. There are indeed some language models that I consider to be completely open source, and they fully release all the infrastructure required to compile the "operating system", from data collection to model training. This is definitely better than just getting the model weights because you can fine-tune the model.
But I think there is a subtle problem, which is that you can't completely fine-tune the model, because the more you fine-tune it, the worse it will perform on every other task.
So if you want to add a certain ability without affecting other abilities, you may actually need to mix the previous data set distribution and the new data set distribution for training. If you are only given model weights, you can't actually do this. You need training loops, you need data sets, etc. So you're really limited in what you can do with these models.
They are certainly helpful, but we may need better terms to describe them. Open weight model, open source model, and proprietary model, the ecosystem may look like this. And it's likely to be very similar to the ecosystem we have today.
 Scale is the main determining factor
Scale is the main determining factor
: Another question I want to ask is scale. Simply put, size seems to be most important. Data scale and computing power scale. So the big research labs, the big tech giants have a huge advantage today. What do you think about this? Is size everything? If not, what else matters?
Kapasi: I think scale is definitely the first. There are some details that really need to be taken care of. I think the preparation of the data set is also very important, making the data very good and very clean, which can make the calculation more efficient.
But I think scale will be the main determining factor, the first principal ingredient, and of course you need to get a lot of other things right.
If you don’t have scale, you fundamentally can’t train these large models. If you're just doing things like fine-tuning, you probably don't need that scale, but we haven't really seen that fully realized yet.
Q: Can you elaborate on what other factors you think are important besides scale, maybe with lower priority?
Kappasi: First of all, you can't just train these models. If you just provide funding and scale, it's still very difficult to actually train these models. Part of the reason is that the infrastructure is too new, still under development, and not yet complete. But training a model at this scale is extremely difficult and is a very complex distributed optimization problem. Talents in this area are currently quite scarce. It's basically a crazy thing where the model is run on thousands of GPUs, failing randomly at different points in time. Monitoring this process and making it work is actually an extremely difficult challenge. Until recently, GPUs were not as capable as expected of handling 10,000 GPU workloads. So I think a lot of infrastructure is creaking under this pressure and we need to address that. Now, if you just gave someone a bunch of money or a bunch of GPUs, I'm not sure they could produce large models directly, which is why it's not just a matter of scale. You actually need a lot of expertise, including infrastructure, algorithms, and data, and you have to be very careful. Q: The ecosystem is growing so fast, and some of the challenges we thought existed a year ago are increasingly being addressed. Illusions, contextual windows, multi-modal capabilities, inference is getting faster and cheaper. What other language model research challenges are keeping you up at night right now? What problems do you think are urgent enough but also solvable? Kapasi: I think in terms of algorithms, one issue that I think about a lot is the clear difference between diffusion models and autoregressive models. They are all ways of representing probability distributions. It turns out that different modalities clearly lend themselves to one or the other. I think there might be some room to unify them, or connect them in some way. Another thing I want to point out is the inherent efficiency of the infrastructure for running large models. My brain consumes about 20 watts. Huang just talked about the large-scale supercomputer they want to build at GTC, and the numbers are all in the megawatt range. So maybe you don't need that much energy to run a brain. I don't know exactly how much it will take, but I think it's safe to say that we can get anywhere from 1,000x to 1,000,000x more efficient in running these models. I think part of the problem is that current computers are simply not suitable for this workload. Nvidia's GPUs are a good step in this direction, because you need extremely high parallelism. We don't really care about sequential computations that rely on the data in some way. We just need to perform the same algorithm on many different array elements. So I think number one is adapting computer architecture to accommodate new data workflows, and number two is pushing some of the things that we're currently seeing improvements to. The first one may be precision. We've seen the accuracy drop from the original 64-bit double to now 4, 5, 6 bits, or even 1.5 to 8 bits depending on which paper you read. So I think accuracy is a big lever in controlling this problem. The second one is of course sparsity. In fact, many parameters in large models are zero, or close to zero. So it would be great if you could exploit this in some way, say by making sparse matrix multiplication more efficient. There is some promising research in this area. Also there are some interesting ideas like singular value decomposition (SVD) to see if you can break it down into smaller matrices and then reassemble it. For example, only forward propagation is calculated without back propagation, and a smaller model is trained to predict the output of a larger model. So I think, fundamentally, there are two problems to solve: One is to build more suitable hardware. Another is to find better algorithms that increase efficiency while maintaining performance. I think there is still a lot of room for exploration in both aspects. From an energy efficiency perspective, if we could close the gap with the brain, that would be a huge improvement. This could mean that each of us can afford a model, or run a model on our devices without needing to be connected to the cloud. Q: Okay, let’s change the topic. You've worked alongside many of the greats of this era, Sam, Greg and other team members at OpenAI, as well as Musk. How many of you here have heard the joke about the U.S. rowing team and the Japanese rowing team? This is an interesting story. Musk has shared this joke, and I think it reflects a lot of his philosophy on building culture and teams. There are two teams in the story, the Japanese team has 4 rowers and 1 coxswain, and the American team has 4 coxswains and 1 coxswain. Can anyone guess what Team USA will do when they lose? Speak up. Exactly, they're going to fire that oarsman. When Musk shared this example, I think he was explaining his views on hiring the right talent and building the right team. What have you learned from working closely with these incredible leaders? KAPASI: I would say that Musk’s way of managing the company is very unique. I feel like people don’t really realize how special it is. Even if you listen to others talk about it, it is difficult for you to fully understand it. I find it difficult to describe in words. I don't even know where to begin. But it’s a really unique and different way to do it. In my words, He is managing the largest startup company in the world. I feel like it’s hard for me to describe it clearly right now, and it may take longer to think and summarize. But first of all, he likes to form a company by a small team with strong strength and high technical content. In other companies, the team size often becomes larger during the development process. Musk, on the other hand, has always been against overexpansion of the team. I had to work hard to recruit employees. I had to beg him to allow me to recruit people. Also, it is often difficult for large companies to get rid of underperforming employees. Musk, on the other hand, is more willing to take the initiative to lay off employees. In fact, I had to fight hard to keep some employees because he always defaulted to laying them off. So the first point is to maintain a small team with strong strength and excellent technology. Absolutely no non-technical middle management. This is the most important point. The second point is how he creates a working atmosphere and the feeling he gives when he walks into the office. He wants the work environment to be vibrant. People move around, think about things, focus on exciting things. They are either writing and drawing on the whiteboard, or typing code in front of the computer. He doesn't like a pool of stagnant water, and he doesn't like the lack of life in the office. He also doesn’t like long meetings and always encourages people to leave decisively when the meeting is pointless. You could really see that if you had nothing to contribute and gain from the meeting, you could just walk out, and he was very supportive of that. I think this is difficult to see in other companies. So I thinkCreating a positive working atmosphere is the second important concept that he instilled. Perhaps this also includes the tendency for companies to over-protect their employees as they get larger. That won't be the case in his company. The company's culture is that you have to show 100% of your professional abilities, and the work pace and intensity are very high. I think the last thing that's probably the most unique, interesting and unusual is that he's so connected to the team. Usually the CEO of a company is an unreachable person who manages five levels of subordinates and only communicates with the vice president. The vice president communicates with their subordinate supervisors, and the supervisor communicates with the managers. You only Able to speak with immediate supervisor. But Musk runs the company entirely differently. He would come to the office and talk directly to the engineers. When we have meetings, there are often 50 people in the conference room face to face with Musk, and he talks directly to the engineers. He didn't want to just talk to VPs and executives. Usually a CEO will spend 99% of his time communicating with the vice president, and he may spend 50% of his time communicating with engineers. So if the team is small and efficient, engineers and code are the most trusted sources of information. They have firsthand knowledge of the truth. Musk wants to communicate directly with engineers to understand the actual situation and discuss how to improve it. So I would say the fact that he's connected to the team and not distant is very unique. Also, the way he wields power within the company is unusual. For example, if he talks to engineers and learns about some problems that are hindering the progress of the project. For example, if an engineer says, "I don't have enough GPUs to run the program," he will take it to heart. If he hears a similar complaint twice, he'll say, "Okay, here's a problem. So what's the timetable now? When will it be resolved?" If he doesn't get a satisfactory answer, He'll say, "I'm going to talk to the person in charge of the GPU cluster," and someone will call that person and he'll literally say, "Double the cluster capacity now. Talk to me every day starting tomorrow. Report the progress until the cluster size doubles." The other party may shirk it by saying that it still needs to go through the procurement process, which will take 6 months. At this time Musk will frown and say: "Okay, I want to talk to Huang Renxun." Then he will directly remove the project obstacles. So I think people don't really realize how deeply involved he is in various tasks, clearing obstacles and exerting influence. Honestly, if you leave such an environment and go to an ordinary company, you will really miss these unique places. Musk “is running the world’s largest startup”

The above is the detailed content of My leader Musk: Hates meetings, doesn't want non-technical middle managers, and advocates layoffs. For more information, please follow other related articles on the PHP Chinese website!

 人体试验要泡汤?马斯克Neuralink面临联邦调查,实验动物死亡频发Apr 12, 2023 pm 05:37 PM
人体试验要泡汤?马斯克Neuralink面临联邦调查,实验动物死亡频发Apr 12, 2023 pm 05:37 PM上周,马斯克举办了 Neuralink 的 Show & Tell 演示活动,向世人展示了脑机接口的最新进展。会上,马斯克表示,从原型到生产非常困难,面临诸多挑战。Neuralink 一直在努力启动人体试验,并且已向 FDA 提交了开始人体试验所需的所有文件。马斯克估计,第一个 Neuralink 设备可能会在 5-6 个月内进入人脑。会上马斯克强调, Neuralink 尊重动物受试者,并且脑机接口设备植入动物体内之前已经进行了广泛的基准测试。两只猴子 Pager 和
 马斯克反讽人工智能AI炒作:“机器学习”本质就是统计Jun 13, 2023 pm 12:13 PM
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计Jun 13, 2023 pm 12:13 PM驱动中国2023年6月12日消息,近日,特斯拉CEO埃隆·马斯克周六在推特上发布了一张图片,疑似讽刺当前关于“人工智能”的炒作现象。图文显示,一位戴着“MachineLearning”面罩的路人,将其面罩摘下是一张写着“Statistics(统计)”的面孔。寓意当前大火的人工智能AI本质就是数据统计的结果。值得注意的是,持此类意见的科技领袖恐不在少数,之前马斯克曾与苹果联合创始人史蒂夫沃兹尼亚克以及上千名AI研究人员联署公开信,呼吁暂停研究更先进的AI技术。然而,此信遭到许多专家甚至签名者的质疑
 X 网站出现无法屏蔽的广告,会诱导用户点击Oct 10, 2023 pm 04:37 PM
X 网站出现无法屏蔽的广告,会诱导用户点击Oct 10, 2023 pm 04:37 PM根据Mashable的报道,据称在X网站(原名Twitter)的移动应用程序中,用户在他们的ForYou信息流中发现了一些没有标注的广告。当用户点击这些广告时,会跳转到其他网站,而且没有办法屏蔽或举报这些广告这些新出现的广告与普通广告有所不同。普通广告只是来自X网站账号的帖子,并且带有一个“Ad”的标签。而这些新广告没有与之相关联的账号,仅由书面文本、照片和虚假头像组成,使其看起来像正常的推文。它们旨在诱导用户点击。以下是它们的样子:如果用户只是随意地滑动屏幕,嵌入的图片和吸引眼球的文本可能会让
 马斯克,脑机接口,第一刀Jun 04, 2023 am 09:49 AM
马斯克,脑机接口,第一刀Jun 04, 2023 am 09:49 AM从“硅谷钢铁侠”到“现实钢铁侠”,马斯克成为“人类托尼・史塔克”,正在逐渐成为现实。就在几天前,马斯克脑机接口公司Neuralink宣布迎来重大进展——已经获得美国食品和药物管理局(FDA)的批准,将启动其首个人体临床研究,这意味着,他们的设备将植入人类的大脑中。据悉他们会专注于两个应用:恢复人类视力,帮助无法移动肌肉的人控制智能手机等设备。在去年11月,马斯克曾放出豪言,称Neuralink距离首次人体试验还有大约6个月的时间。可是后来,由于安全风险大、违反动物权益、涉嫌非法运输危险病原体..
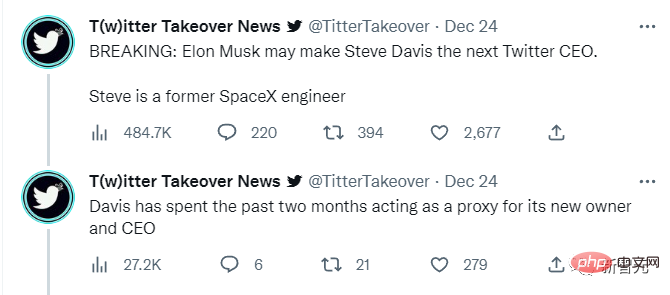 新推特CEO曾为马斯克工作20年,带全家居住在办公室!May 06, 2023 pm 08:43 PM
新推特CEO曾为马斯克工作20年,带全家居住在办公室!May 06, 2023 pm 08:43 PM自从马斯克在推特上搞的关于「自己要不要辞职CEO」的投票结果出炉以来,从媒体到公众都在关心一个问题:谁来接班?据外媒theinformation报道,接班人可能是一位马斯克的忠实拥护者,马斯克的隧道挖掘公司TheBoringCompany的CEO,宇航工程师SteveDavis。据TheInformation报道,今年43岁SteveDavis是和马斯克一样,也是一位「拼命三郎」。此前,他已经在Twitter总部的办公室里睡了两个月。而且还是和他刚刚分娩的妻子,和他们刚刚出生的孩子一起搬过来
 马斯克计划与扎克伯格对决,但后者未在家且不会与其对打Aug 17, 2023 pm 09:29 PM
马斯克计划与扎克伯格对决,但后者未在家且不会与其对打Aug 17, 2023 pm 09:29 PM据报道,马斯克对于扎克伯格不认真对待他们之间的争斗后,决定放弃笼斗计划。然而,马斯克却表示他将会突然出现在Meta首席执行官马克·扎克伯格的家门口,并进行一场拳击对决马斯克今天在X上发帖表示:“今晚我将在帕洛阿尔托进行特斯拉FSD试驾,计划将车开到@finkd的家。”Finkd是扎克伯格在X上的用户名。“如果我们有幸而扎克伯格真的开门,那么战斗就开始了!”马斯克还表示他将在X上直播这次“冒险”扎克伯格对此并不感冒,他的发言人伊斯卡・萨里克(IskaSaric)告诉《TheVerge》,“马克现在
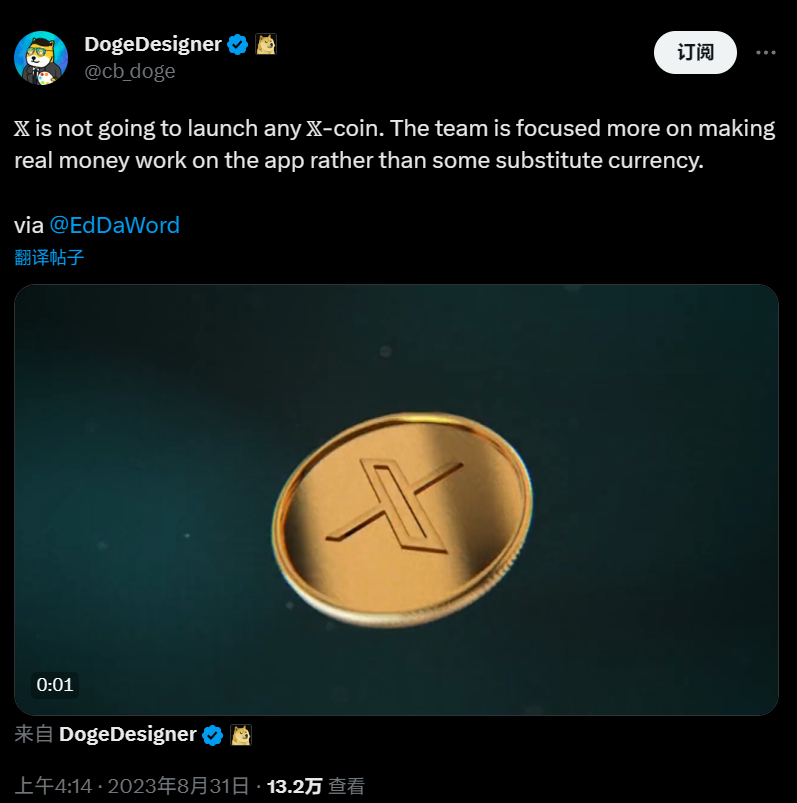 马斯克:致力于在 X 平台上实现“真正的金钱”运作,不计划推出自家加密货币Sep 14, 2023 pm 09:53 PM
马斯克:致力于在 X 平台上实现“真正的金钱”运作,不计划推出自家加密货币Sep 14, 2023 pm 09:53 PM马斯克昨日在X平台上引用了此前设计了X平台图标的设计师的发言。他表示,X平台将专注于让真正的金钱在平台上运行,同时不会开发自己的加密货币据悉,X用户“DogeDesigner”昨日发布贴文声称:“X不会推出任何X币。该团队更专注于让真正的金钱在这个App上运作,而不是一些‘替代货币’。”▲图源X用户“DogeDesigner”的发言对此,马斯克回应称:“正确”。▲图源马斯克的发言我们之前报道过,这位“DogeDesigner”实际上是一家加密货币公司的首席执行官,同时也是X平台图标的设计师。马斯
 马斯克:人工智能毁灭人类的可能性很小,但绝非不可能May 29, 2023 pm 08:02 PM
马斯克:人工智能毁灭人类的可能性很小,但绝非不可能May 29, 2023 pm 08:02 PM5月24日消息,美国当地时间周二,亿万富翁埃隆·马斯克(ElonMusk)参加《华尔街日报》CEO委员会伦敦峰会时表示,他认为有必要建立能与谷歌和微软竞争的人工智能公司,这可能涉及其商业帝国的不同部分,包括推特。在伦敦峰会开幕式上,马斯克表示他去年斥资440亿美元收购推特的努力正在取得成果。他说,推特目前还不是很赚钱,但最快下个月就可能实现现金流正增长。自马斯克将其私有化以来,推特不再公开报告财务业绩,自2019年以来始终没有盈利。马斯克表示,推特可能是他创建人工智能业务的重要组成部分。特斯拉也


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

