

 Technology peripheralsAITsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars
Technology peripheralsAITsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K starsTsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars

In natural language processing, a lot of information is actually repeated.
If the prompt words can be effectively compressed, it is equivalent to expanding the length of the context supported by the model to some extent.
Existing information entropy methods reduce this redundancy by removing certain words or phrases.
However, the calculation based on information entropy only covers the one-way context of the text and may ignore key information required for compression; moreover, the calculation method of information entropy is not fully consistent with the compression tips the actual purpose of the word.
To meet these challenges, researchers from Tsinghua University and Microsoft jointly proposed a new data processing process called LLMLingua-2. It aims to extract knowledge from large language models (LLM) and achieve information refinement by compressing prompt words while ensuring that key information is not lost.

The project has gained 3.1k stars on GitHub
The results show that LLMLingua-2 can The text length is significantly reduced to the original 20%, effectively reducing processing time and costs.
In addition, LLMLingua 2’s processing speed is increased by 3 to 6 times compared to the previous version of LLMLingua and other similar technologies.

Paper address: https://arxiv.org/abs/2403.12968
In this process , raw text is first fed into the model.
The model will evaluate the importance of each word and decide whether to retain or delete it, while also taking into account the relationship between words.
Finally, the model will select those words with the highest scores to form a shorter prompt word.

The team tested the LLMLingua-2 model on multiple datasets including MeetingBank, LongBench, ZeroScrolls, GSM8K and BBH.
Although this model is small, it achieves significant performance improvements in benchmark tests and demonstrates its performance on different large language models (from GPT-3.5 to Mistral- 7B) Excellent generalization ability across languages (from English to Chinese).
System prompt:
As an outstanding linguist, you are good at converting long Condensing paragraphs of text into brief expressions by removing unimportant words while retaining as much information as possible.
User Tips:
Please compress the given text into A short expression that allows you (GPT-4) to restore the original text as accurately as possible. Different from regular text compression, I need you to follow the following five conditions:
1. Only remove unimportant words.
2. Keep the order of the original words unchanged.
3. Keep the original vocabulary unchanged.
4. Do not use any abbreviations or emoticons.
5. Do not add any new words or symbols.
Please compress the original text as much as possible while retaining as much information as possible. If you understand, please compress the following text: {Text to be compressed}
The compressed text is: [...]
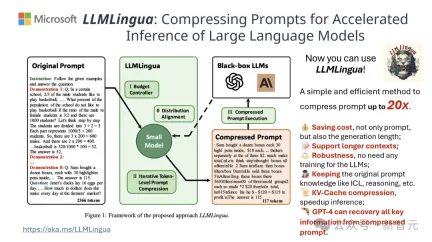
The results show that LLMLingua-2 significantly outperforms the original LLMLingua model and other selective context strategies in multiple language tasks such as question and answer, summary writing, and logical reasoning.
It is worth mentioning that this compression method is equally effective for different large language models (from GPT-3.5 to Mistral-7B) and different languages (from English to Chinese) .
Moreover, the deployment of LLMLingua-2 can be achieved with just two lines of code.
Currently, the model has been integrated into the widely used RAG frameworks LangChain and LlamaIndex.
Implementation method
In order to overcome the problems faced by existing information entropy-based text compression methods, LLMLingua-2 adopts an innovation data extraction strategy.
This strategy extracts essential information from large language models such as GPT-4, achieving efficient text editing without losing key content and avoiding adding erroneous information. compression.
Prompt Design
To fully utilize the text compression potential of GPT-4, the key lies in how to set the precise compression instructions.
That is, when compressing text, instruct GPT-4 to only remove those words that are not so important in the original text, while avoiding the introduction of any new words in the process.
The purpose of this is to ensure that the compressed text maintains the authenticity and integrity of the original text as much as possible.

##Annotation and filtering
The researchers used the GPT-4 Using the knowledge extracted from large language models, a novel data annotation algorithm was developed.
This algorithm can mark each word in the original text and clearly indicate which words must be retained during the compression process.
In order to ensure the high quality of the constructed data set, they also designed two quality monitoring mechanisms specifically to identify and exclude those data samples with poor quality.

Compressor
Finally, the researchers solved the problem of text compression It is transformed into a task of classifying each word (Token), and a powerful Transformer is used as the feature extractor.
This tool can understand the context of text to accurately capture the information critical for text compression.
By training on a carefully constructed data set, the researchers' model is able to calculate a probability value to decide whether a word should be retained based on its importance. In the final compressed text, it should still be discarded.

Performance Evaluation
The researchers tested the performance of LLMLingua-2 on a range of tasks, These tasks include context learning, text summarization, dialogue generation, multi- and single-document question answering, code generation, and synthesis tasks, including both in-domain and out-of-domain datasets.
Test results show that the researchers’ method reduces minimal performance loss while maintaining high performance, and performs outstandingly among task-unspecific text compression methods.
- In-domain test (MeetingBank)
The researchers compared the performance of LLMLingua-2 on the MeetingBank test set with Other powerful baseline methods are compared.
Although their model size is much smaller than the LLaMa-2-7B used in the baseline, the researchers' method not only significantly improved performance on question answering and text summarization tasks, but also was consistent with The original text prompts performed similarly.

##-Out-of-domain testing (LongBench, GSM8K and BBH)
Considering that the researchers’ model was only trained on MeetingBank’s meeting record data, the researchers further explored its generalization capabilities in different scenarios such as long text, logical reasoning, and contextual learning.
It is worth mentioning that although LLMLingua-2 was only trained on one dataset, in out-of-domain testing, its performance was not only comparable to the current state-of-the-art task-independent compression The methods are comparable, and in some cases even better.

Even the researchers’ smaller model (BERT-base size) was able to achieve comparable performance to the original hint, in some cases Down or even slightly above the original tip.
While the researchers’ approach achieved promising results, it still has shortcomings when compared with other task-aware compression methods, such as LongLLMlingua on Longbench.
The researchers attribute this performance gap to the extra information they get from the questions. However, the researchers' model is task-agnostic, making it an efficient option with good generalizability when deployed in different scenarios.
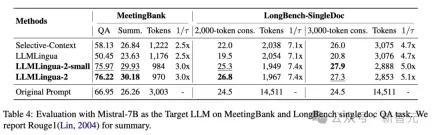
Table 4 above lists the results of different methods using Mistral-7Bv0.1 4 as the target LLM.
Compared with other baseline methods, the researchers' method has a significant improvement in performance, demonstrating its good generalization ability on the target LLM.
It is worth noting that LLMLingua-2 performs even better than the original prompt.
Researchers speculate that Mistral-7B may not be as good at managing long contexts as GPT-3.5-Turbo.
The researchers’ approach effectively improves Mistral7B’s final inference performance by providing short hints with higher information density.
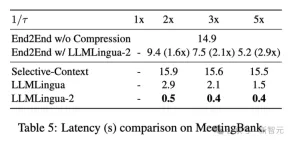
Table 5 above shows the latency of different systems on the V100-32G GPU with different compression ratios.
The results show that compared with other compression methods, LLMLlingua2 has much less computational overhead and can achieve an end-to-end speed improvement of 1.6 times to 2.9 times.
In addition, the researchers' method can reduce GPU memory costs by 8 times, thus reducing the demand for hardware resources.
Context-Aware Observations The researchers observed that as the compression ratio increases, LLMLingua-2 can effectively maintain the most informative words with complete context.
This is thanks to the adoption of a bidirectional context-aware feature extractor and a strategy that is explicitly optimized towards the goal of timely compression.

The researchers observed that as the compression ratio increases, LLMLingua-2 can effectively maintain the most informative words related to the complete context. .
This is thanks to the adoption of a bidirectional context-aware feature extractor and a strategy that is explicitly optimized towards the goal of timely compression.

Finally the researchers had GPT-4 reconstruct the original tones from the LLMLlingua-2 compression prompts.
The results show that GPT-4 can effectively reconstruct the original tip, indicating that no essential information is lost during LLMLingua-2 compression.
The above is the detailed content of Tsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars. For more information, please follow other related articles on the PHP Chinese website!

 From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AM
From Friction To Flow: How AI Is Reshaping Legal WorkMay 09, 2025 am 11:29 AMThe legal tech revolution is gaining momentum, pushing legal professionals to actively embrace AI solutions. Passive resistance is no longer a viable option for those aiming to stay competitive. Why is Technology Adoption Crucial? Legal professional
 This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AM
This Is What AI Thinks Of You And Knows About YouMay 09, 2025 am 11:24 AMMany assume interactions with AI are anonymous, a stark contrast to human communication. However, AI actively profiles users during every chat. Every prompt, every word, is analyzed and categorized. Let's explore this critical aspect of the AI revo
 7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AM
7 Steps To Building A Thriving, AI-Ready Corporate CultureMay 09, 2025 am 11:23 AMA successful artificial intelligence strategy cannot be separated from strong corporate culture support. As Peter Drucker said, business operations depend on people, and so does the success of artificial intelligence. For organizations that actively embrace artificial intelligence, building a corporate culture that adapts to AI is crucial, and it even determines the success or failure of AI strategies. West Monroe recently released a practical guide to building a thriving AI-friendly corporate culture, and here are some key points: 1. Clarify the success model of AI: First of all, we must have a clear vision of how AI can empower business. An ideal AI operation culture can achieve a natural integration of work processes between humans and AI systems. AI is good at certain tasks, while humans are good at creativity and judgment
 Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI's Game Changers, Neuralink Valued At $8.5 BillionMay 09, 2025 am 11:22 AMMeta upgrades AI assistant application, and the era of wearable AI is coming! The app, designed to compete with ChatGPT, offers standard AI features such as text, voice interaction, image generation and web search, but has now added geolocation capabilities for the first time. This means that Meta AI knows where you are and what you are viewing when answering your question. It uses your interests, location, profile and activity information to provide the latest situational information that was not possible before. The app also supports real-time translation, which completely changed the AI experience on Ray-Ban glasses and greatly improved its usefulness. The imposition of tariffs on foreign films is a naked exercise of power over the media and culture. If implemented, this will accelerate toward AI and virtual production
 Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AM
Take These Steps Today To Protect Yourself Against AI CybercrimeMay 09, 2025 am 11:19 AMArtificial intelligence is revolutionizing the field of cybercrime, which forces us to learn new defensive skills. Cyber criminals are increasingly using powerful artificial intelligence technologies such as deep forgery and intelligent cyberattacks to fraud and destruction at an unprecedented scale. It is reported that 87% of global businesses have been targeted for AI cybercrime over the past year. So, how can we avoid becoming victims of this wave of smart crimes? Let’s explore how to identify risks and take protective measures at the individual and organizational level. How cybercriminals use artificial intelligence As technology advances, criminals are constantly looking for new ways to attack individuals, businesses and governments. The widespread use of artificial intelligence may be the latest aspect, but its potential harm is unprecedented. In particular, artificial intelligence
 A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AM
A Symbiotic Dance: Navigating Loops Of Artificial And Natural PerceptionMay 09, 2025 am 11:13 AMThe intricate relationship between artificial intelligence (AI) and human intelligence (NI) is best understood as a feedback loop. Humans create AI, training it on data generated by human activity to enhance or replicate human capabilities. This AI
 AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AM
AI's Biggest Secret — Creators Don't Understand It, Experts SplitMay 09, 2025 am 11:09 AMAnthropic's recent statement, highlighting the lack of understanding surrounding cutting-edge AI models, has sparked a heated debate among experts. Is this opacity a genuine technological crisis, or simply a temporary hurdle on the path to more soph
 Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AM
Bulbul-V2 by Sarvam AI: India's Best TTS ModelMay 09, 2025 am 10:52 AMIndia is a diverse country with a rich tapestry of languages, making seamless communication across regions a persistent challenge. However, Sarvam’s Bulbul-V2 is helping to bridge this gap with its advanced text-to-speech (TTS) t


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Linux new version
SublimeText3 Linux latest version

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

Dreamweaver Mac version
Visual web development tools

