

 Technology peripheralsAICLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Technology peripheralsAICLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performanceCLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance

Written before&The author’s personal understanding
Currently, in the entire autonomous driving system, the perception module plays a vital role when driving on the road Only after the autonomous driving vehicle obtains accurate sensing results through the perception module can the downstream control module in the autonomous driving system make timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks.
The BEV perception algorithm based on pure vision has received widespread attention from industry and academia because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks. . In recent years, many visual perception algorithms based on BEV space have emerged one after another and have demonstrated excellent perception performance on public data sets.
Currently, perception algorithms based on BEV space can be roughly divided into two types of algorithm models based on the way to construct BEV features:
- One type is the forward BEV feature represented by the LSS algorithm Construction method: This type of perception algorithm model first uses the depth estimation network in the perception model to predict the semantic feature information and discrete depth probability distribution of each pixel of the feature map, and then uses external methods to combine the obtained semantic feature information and discrete depth probability. The semantic frustum features are constructed by product operation, and BEV pooling and other methods are used to finally complete the construction process of BEV spatial features.
- The other type is the reverse BEV feature construction method represented by the BEVFormer algorithm. This type of perception algorithm model first explicitly generates 3D voxel coordinate points in the perceived BEV space, and then uses the camera's The internal and external parameters project the 3D voxel coordinate points back to the image coordinate system, and extract and aggregate the pixel features at the corresponding feature positions to construct the BEV features in the BEV space.
Although both algorithms can accurately generate features in BEV space and achieve 3D perception results, there are the following two problems in current 3D target perception algorithms based on BEV space, such as the BEVFormer algorithm. :
- Question 1: Since the overall framework of the BEVFormer perception algorithm model adopts the Encoder-Decoder network structure, the main idea is to use the Encoder module to obtain the features in the BEV space, and then use the Decoder module to predict the final perception result. And by calculating the loss between the output perception result and the true value target, the process of predicting the BEV spatial characteristics of the model is realized. However, the parameter update method of this network model will rely too much on the perceptual performance of the Decoder module, which may lead to the problem that the BEV features output by the model are not aligned with the true value BEV features, thus further restricting the final performance of the perceptual model.
- Question 2: Since the Decoder module of the BEVFormer perception algorithm model still uses the self-attention module->cross-attention module-> feedforward neural network steps in the Transformer to complete the construction of Query features and output the final As for the detection results, the entire process is still a black box model, lacking good interpretability. At the same time, there is also great uncertainty in the one-to-one matching process between Object Query and the true value target during the model training process.
In order to solve the problems of the BEVFormer perception algorithm model, we improved it and proposed a 3D detection algorithm model CLIP-BEVFormer based on surround images. By introducing the contrastive learning method, we enhanced the model's ability to construct BEV features and achieved leading-level perceptual performance on the nuScenes data set.
Article link: https://arxiv.org/pdf/2403.08919.pdf
Overall architecture & details of the network model
In details Before introducing the details of the CLIP-BEVFormer perception algorithm model proposed in this article, the following figure shows the overall network structure of the CLIP-BEVFormer algorithm.
 The overall flow chart of the CLIP-BEVFormer perception algorithm model proposed in this article
The overall flow chart of the CLIP-BEVFormer perception algorithm model proposed in this article
It can be seen from the overall flow chart of the algorithm that the CLIP-BEVFormer algorithm model proposed in this article is based on the BEVFormer algorithm model. Based on the improvement, here is a brief review of the implementation process of the BEVFormer perception algorithm model. First, the BEVFormer algorithm model inputs the surround image data collected by the camera sensor, and uses the 2D image feature extraction network to extract the multi-scale semantic feature information of the input surround image. Secondly, the Encoder module containing temporal self-attention and spatial cross-attention is used to complete the conversion process of 2D image features to BEV spatial features. Then, a set of Object Query is generated in the form of normal distribution in the 3D perception space and sent to the Decoder module to complete the interactive utilization of spatial features with the BEV space features output by the Encoder module. Finally, the feedforward neural network is used to predict the semantic features queried by Object Query, and the final classification and regression results of the network model are output. At the same time, during the training process of the BEVFormer algorithm model, the one-to-one Hungarian matching strategy is used to complete the distribution process of positive and negative samples, and classification and regression losses are used to complete the update process of the overall network model parameters. The overall detection process of the BEVFormer algorithm model can be expressed by the following mathematical formula:
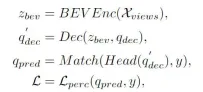
Among them, in the formula represents the Encoder feature extraction module in the BEVFormer algorithm, represents the Decoder decoding module in the BEVFormer algorithm, represents the true value target label in the data set, and represents the current BEVFormer algorithm model. Output 3D perception results.
Generation of true value BEV
As mentioned above, most of the existing 3D target detection algorithms based on BEV space do not have explicit alignment The generated BEV spatial features are supervised, which leads to the problem that the BEV features generated by the model may be inconsistent with the real BEV features. This difference in the distribution of BEV spatial features will restrict the final perceptual performance of the model. Based on this consideration, we proposed the Ground Truth BEV module. Our core idea in designing this module is to enable the BEV features generated by the model to be aligned with the current true value BEV features, thereby improving the performance of the model.
Specifically, as shown in the overall network framework diagram, we use a ground truth encoder () to encode the category label and spatial bounding box position information of any ground truth instance on the BEV feature map. Encoding, the process can be expressed by a formula in the following form:
The formula has a feature dimension of the same size as the generated BEV feature map, representing the encoded feature information of a true value target. During the encoding process, we adopted two forms, one is a large language model (LLM), and the other is a multi-layer perceptron (MLP). Through experimental results, we found that the two methods basically achieved the same performance.
In addition, in order to further enhance the boundary information of the true value target on the BEV feature map, we crop the true value target on the BEV feature map according to its spatial position, and perform the cropping The features use pooling operations to construct the corresponding feature information representation. The process can be expressed in the following form:
Finally, in order to further align the BEV features generated by the model with the true value BEV features, we adopted The comparative learning method is used to optimize the element relationship and distance between the two types of BEV features. The optimization process can be expressed in the following form:
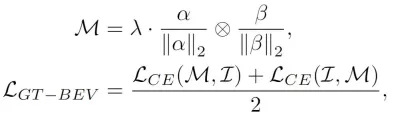
where the and in the formula represent respectively The similarity matrix between the generated BEV features and the true value BEV features represents the logical scale factor in contrastive learning, represents the multiplication operation between matrices, and represents the cross-entropy loss function. Through the above contrastive learning method, the method we propose can provide clearer feature guidance for the generated BEV features and improve the perceptual ability of the model.
True value target query interaction
This part is also mentioned in the previous article. The Object Query in the BEVFormer perception algorithm model interacts with the generated BEV features through the Decoder module to obtain the corresponding target query characteristics, but the process as a whole is still a black box process, lacking a complete process understanding. To address this problem, we introduced the truth value query interaction module, which uses the truth value target to execute the BEV feature interaction of the Decoder module to stimulate the learning process of model parameters. Specifically, we introduce the truth target encoding information output by the truth encoder () module into Object Query to participate in the decoding process of the Decoder module. As normal Object Query, we participate in the same self-attention module, cross-attention module and The feedforward neural network outputs the final perception result. However, it should be noted that during the decoding process, all Object Query uses parallel computing to prevent the leakage of true value target information. The entire truth value target query interaction process can be abstractly expressed in the following form:
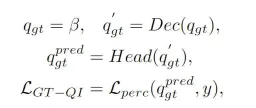
Among them, in the formula represents the initialized Object Query, and represents the truth value Object Query process respectively. The output results of the Decoder module and the sensing detection head. By introducing the interaction process of the true value target in the model training process, the true value target query interaction module we proposed can realize the interaction between the true value target query and the true value BEV feature, thereby assisting the parameter update process of the model Decoder module.
Experimental results & evaluation indicators
Quantitative analysis part
In order to verify the effectiveness of the CLIP-BEVFormer algorithm model we proposed sex, we conducted relevant experiments on the nuScenes data set from the perspectives of 3D perception effects, long-tail distribution of target categories in the data set, and robustness. The following table shows the differences between our proposed algorithm model and other 3D perception algorithm models. Accuracy comparison on nuScenes dataset.
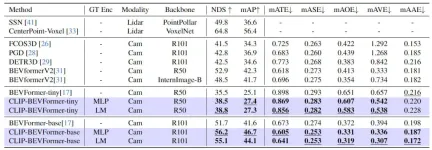
Comparative results between the method proposed in this article and other perception algorithm models
In this part of the experiment, we evaluated the perceived performance under different model configurations. Specifically, we applied the CLIP-BEVFormer algorithm model to the tiny and base variants of BEVFormer. In addition, we also explored the impact of using pre-trained CLIP models or MLP layers as ground truth target encoders on model perceptual performance. It can be seen from the experimental results that whether it is the original tiny or base variant, after applying the CLIP-BEVFormer algorithm we proposed, the NDS and mAP indicators have stable performance improvements. In addition, through the experimental results, we can find that the algorithm model we proposed is not sensitive to whether the MLP layer or the language model is selected for the ground truth target encoder. This flexibility can make the CLIP-BEVFormer algorithm we proposed more efficient. Adaptable and easy to deploy on the vehicle. In summary, the performance indicators of various variants of our proposed algorithm model consistently indicate that the proposed CLIP-BEVFormer algorithm model has good perceptual robustness and can achieve excellent detection performance under different model complexity and parameter amounts. .
In addition to verifying the performance of our proposed CLIP-BEVFormer on 3D perception tasks, we also conducted long-tail distribution experiments to evaluate the robustness of our algorithm in the face of long-tail distributions in the data set. Stickiness and generalization ability, the experimental results are summarized in the following table
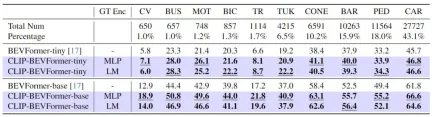
Performance of the proposed CLIP-BEVFormer algorithm model on long-tail problems
passed the above It can be seen from the experimental results in the table that the nuScenes data set shows a huge imbalance in the number of categories. Some categories such as (construction vehicles, buses, motorcycles, bicycles, etc.) account for a very low proportion, but for cars The proportion is very high. We evaluate the perceptual performance of the proposed CLIP-BEVFormer algorithm model on feature categories by conducting relevant experiments with long-tail distributions, thereby verifying its processing ability to solve less common categories. It can be seen from the above experimental data that the proposed CLIP-BEVFormer algorithm model has achieved performance improvements in all categories, and in categories that account for a very small proportion, the CLIP-BEVFormer algorithm model has demonstrated obvious substantive performance Improve.
Considering that autonomous driving systems in real environments need to face problems such as hardware failures, severe weather conditions, or sensor failures that are easily caused by man-made obstacles, we further experimentally verified the robustness of the proposed algorithm model. Specifically, in order to simulate the sensor failure problem, we randomly blocked the camera of a camera during the model implementation inference process, so as to simulate the scene where the camera may fail. The relevant experimental results are shown in the table below
 Robustness experimental results of the proposed CLIP-BEVFormer algorithm model
Robustness experimental results of the proposed CLIP-BEVFormer algorithm model
It can be seen from the experimental results that no matter under the model parameter configuration of tiny or base, the CLIP-BEVFormer algorithm model we proposed is always better than the baseline model of the same configuration of BEVFormer, which verifies that our algorithm model performs well in simulation Superior performance and excellent robustness under sensor failure conditions.
Qualitative analysis part
The following figure shows the visual comparison of the perception results of our proposed CLIP-BEVFormer algorithm model and the BEVFormer algorithm model. It can be seen from the visual results that the perception results of the CLIP-BEVFormer algorithm model we proposed are closer to the true value target, indicating the effectiveness of the true value BEV feature generation module and the true value target query interaction module we proposed.

Visual comparison of the perception results of the proposed CLIP-BEVFormer algorithm model and the BEVFormer algorithm model
Conclusion
In this article, in view of the lack of display supervision in the process of generating BEV feature maps in the original BEVFormer algorithm and the uncertainty of interactive query between Object Query and BEV features in the Decoder module, we proposed the CLIP-BEVFormer algorithm model and started from Experiments were conducted on the 3D perception performance of the algorithm model, target long-tail distribution, and robustness to sensor failures. A large number of experimental results show the effectiveness of the CLIP-BEVFormer algorithm model we proposed.
The above is the detailed content of CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance. For more information, please follow other related articles on the PHP Chinese website!

 Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AM
Gemma Scope: Google's Microscope for Peering into AI's Thought ProcessApr 17, 2025 am 11:55 AMExploring the Inner Workings of Language Models with Gemma Scope Understanding the complexities of AI language models is a significant challenge. Google's release of Gemma Scope, a comprehensive toolkit, offers researchers a powerful way to delve in
 Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AM
Who Is a Business Intelligence Analyst and How To Become One?Apr 17, 2025 am 11:44 AMUnlocking Business Success: A Guide to Becoming a Business Intelligence Analyst Imagine transforming raw data into actionable insights that drive organizational growth. This is the power of a Business Intelligence (BI) Analyst – a crucial role in gu
 How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMIntroduction Imagine a bustling office where two professionals collaborate on a critical project. The business analyst focuses on the company's objectives, identifying areas for improvement, and ensuring strategic alignment with market trends. Simu
 What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
What are COUNT and COUNTA in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel data counting and analysis: detailed explanation of COUNT and COUNTA functions Accurate data counting and analysis are critical in Excel, especially when working with large data sets. Excel provides a variety of functions to achieve this, with the COUNT and COUNTA functions being key tools for counting the number of cells under different conditions. Although both functions are used to count cells, their design targets are targeted at different data types. Let's dig into the specific details of COUNT and COUNTA functions, highlight their unique features and differences, and learn how to apply them in data analysis. Overview of key points Understand COUNT and COU
 Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AM
Chrome is Here With AI: Experiencing Something New Everyday!!Apr 17, 2025 am 11:29 AMGoogle Chrome's AI Revolution: A Personalized and Efficient Browsing Experience Artificial Intelligence (AI) is rapidly transforming our daily lives, and Google Chrome is leading the charge in the web browsing arena. This article explores the exciti
 AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AM
AI's Human Side: Wellbeing And The Quadruple Bottom LineApr 17, 2025 am 11:28 AMReimagining Impact: The Quadruple Bottom Line For too long, the conversation has been dominated by a narrow view of AI’s impact, primarily focused on the bottom line of profit. However, a more holistic approach recognizes the interconnectedness of bu
 5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AM
5 Game-Changing Quantum Computing Use Cases You Should Know AboutApr 17, 2025 am 11:24 AMThings are moving steadily towards that point. The investment pouring into quantum service providers and startups shows that industry understands its significance. And a growing number of real-world use cases are emerging to demonstrate its value out


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Atom editor mac version download
The most popular open source editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Dreamweaver CS6
Visual web development tools

