

 Technology peripheralsAIDepth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving
Technology peripheralsAIDepth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous drivingDepth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving

Written before & personal understanding
Multi-view depth estimation has achieved high performance in various benchmark tests. However, almost all current multi-view systems rely on a given ideal camera pose, which is unavailable in many real-world scenarios, such as autonomous driving. This work proposes a new robustness benchmark to evaluate depth estimation systems under various noisy pose settings. Surprisingly, it is found that current multi-view depth estimation methods or single-view and multi-view fusion methods fail when given noisy pose settings. To address this challenge, here we propose AFNet, a single-view and multi-view fused depth estimation system that adaptively integrates high-confidence multi-view and single-view results to achieve robust and accurate depth estimation. The adaptive fusion module performs fusion by dynamically selecting high-confidence regions between the two branches based on the parcel confidence map. Therefore, when faced with textureless scenes, inaccurate calibration, dynamic objects, and other degraded or challenging conditions, the system tends to choose the more reliable branch. Under robustness tests, the method outperforms state-of-the-art multi-view and fusion methods. Additionally, state-of-the-art performance is achieved on challenging benchmarks (KITTI and DDAD).
Paper link: https://arxiv.org/pdf/2403.07535.pdf
Paper name: Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Field Background
Image depth estimation has always been a challenge in the field of computer vision and has a wide range of applications. For vision-based autonomous driving systems, depth perception is key, helping to understand objects on the road and build 3D maps of the environment. With the application of deep neural networks in various visual problems, methods based on convolutional neural networks (CNN) have become the mainstream of depth estimation tasks.
According to the input format, it is mainly divided into multi-view depth estimation and single-view depth estimation. The assumption behind multi-view methods for estimating depth is that, given correct depth, camera calibration, and camera pose, pixels across views should be similar. They rely on epipolar geometry to triangulate high-quality depth measurements. However, the accuracy and robustness of multi-view methods strongly depend on the geometric configuration of the camera and the corresponding matching between views. First, the camera needs to translate enough to allow for triangulation. In a self-driving scenario, the self-vehicle may stop at a traffic light or turn without moving forward, which can cause triangulation to fail. In addition, multi-view methods suffer from the problems of dynamic targets and textureless areas, which are prevalent in autonomous driving scenarios. Another issue is SLAM attitude optimization on moving vehicles. In existing SLAM methods, noise is inevitable, not to mention challenging and unavoidable situations. For example, a robot or self-driving car can be deployed for years without recalibration, resulting in noisy poses. In contrast, since single-view methods rely on semantic understanding of the scene and perspective projection cues, they are more robust to textureless regions, dynamic objects, and do not rely on camera pose. However, due to the ambiguity of scale, its performance still falls far behind multi-view methods. Here, we tend to consider whether the advantages of these two methods can be well combined for robust and accurate monocular video depth estimation in autonomous driving scenarios.
AFNet network structure
The AFNet structure is as follows. It consists of three parts: single-view branch, multi-view branch and adaptive fusion (AF) module. The two branches share the feature extraction network and have their own prediction and confidence maps, i.e., , , and , and are then fused by the AF module to obtain the final accurate and robust prediction. The green background in the AF module represents the single-view branch and The output of the multi-view branch.
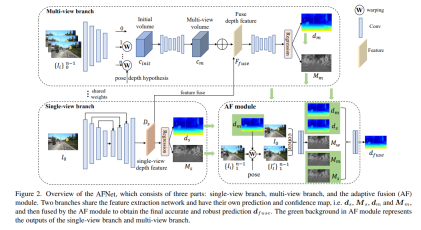
Loss function:
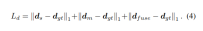
Single view and multi-view depth module
In order to merge backbone features and obtain deep features Ds, AFNet builds a multi-scale decoder. In this process, a softmax operation is performed on the first 256 channels of Ds to obtain the depth probability volume Ps. The last channel in the depth feature is used as the single-view depth confidence map Ms. Finally, the single-view depth is calculated through soft weighting.
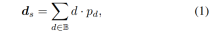
Multi-view branch
The multi-view branch shares the backbone with the single-view branch to extract features of the reference image and the source image. We adopt deconvolution to deconvolve the low-resolution features to quarter-resolution and combine them with the initial quarter-features used to construct the cost volume. A feature volume is formed by wrapping the source features into a hypothetical plane followed by the reference camera. For robust matching that does not require too much information, the channel dimension of the feature is retained in the calculation and a 4D cost volume is constructed, and then the number of channels is reduced to 1 through two 3D convolutional layers.
The sampling method of the depth hypothesis is consistent with the single-view branch, but the number of samples is only 128, and then a stacked 2D hourglass network is used for regularization to obtain the final multi-view cost volume. In order to supplement the rich semantic information of single-view features and the details lost due to cost regularization, a residual structure is used to combine single-view depth features Ds and cost volume to obtain fused depth features, as follows:
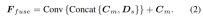
Adaptive fusion module
In order to obtain the final accurate and robust prediction, the AF module is designed to adaptively select the best value between the two branches. The accurate depth is used as the final output, as shown in Figure 2. Fusion mapping is performed through three confidences, two of which are the confidence maps Ms and Mm generated by the two branches respectively. The most critical one is the confidence map Mw generated by forward wrapping to determine whether the prediction of the multi-view branch is reliable. .
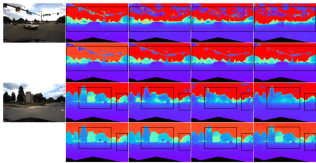
Experimental Results
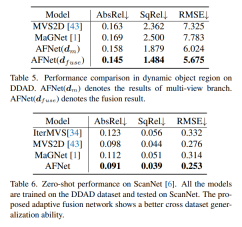
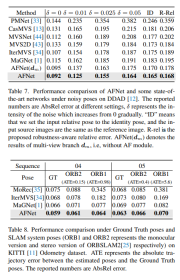
DDAD (Dense Depth for Autonomous Driving) is a new autonomous driving benchmark for dense depth in challenging and diverse urban conditions estimate. It is captured by 6 synchronized cameras and contains accurate ground depth (entire 360-degree field of view) generated by high-density lidar. It has 12650 training samples and 3950 validation samples in a single camera view with a resolution of 1936×1216. All data from 6 cameras are used for training and testing. The KITTI data set provides stereoscopic images of outdoor scenes shot on moving vehicles and corresponding 3D laser scans, with a resolution of approximately 1241×376.
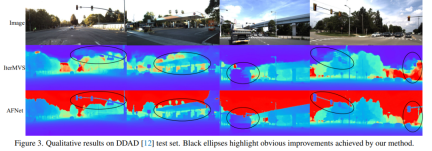
Comparison of evaluation results on DDAD and KITTI. Note that * marks results replicated using their open source code, other reported numbers are from the corresponding original papers.
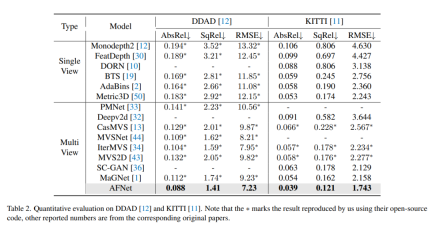
Ablation experimental results for each strategy in the method on DDAD. Single represents the result of single-view branch prediction, Multi- represents the result of multi-view branch prediction, and Fuse represents the fusion result dfuse.
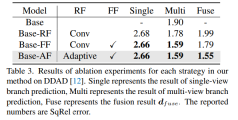
#A method to share network parameters and extract matching information for feature extraction of ablation results.
The above is the detailed content of Depth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

 What is Graph of Thought in Prompt EngineeringApr 13, 2025 am 11:53 AM
What is Graph of Thought in Prompt EngineeringApr 13, 2025 am 11:53 AMIntroduction In prompt engineering, “Graph of Thought” refers to a novel approach that uses graph theory to structure and guide AI’s reasoning process. Unlike traditional methods, which often involve linear s
 Optimize Your Organisation's Email Marketing with GenAI AgentsApr 13, 2025 am 11:44 AM
Optimize Your Organisation's Email Marketing with GenAI AgentsApr 13, 2025 am 11:44 AMIntroduction Congratulations! You run a successful business. Through your web pages, social media campaigns, webinars, conferences, free resources, and other sources, you collect 5000 email IDs daily. The next obvious step is
 Real-Time App Performance Monitoring with Apache PinotApr 13, 2025 am 11:40 AM
Real-Time App Performance Monitoring with Apache PinotApr 13, 2025 am 11:40 AMIntroduction In today’s fast-paced software development environment, ensuring optimal application performance is crucial. Monitoring real-time metrics such as response times, error rates, and resource utilization can help main
 ChatGPT Hits 1 Billion Users? 'Doubled In Just Weeks' Says OpenAI CEOApr 13, 2025 am 11:23 AM
ChatGPT Hits 1 Billion Users? 'Doubled In Just Weeks' Says OpenAI CEOApr 13, 2025 am 11:23 AM“How many users do you have?” he prodded. “I think the last time we said was 500 million weekly actives, and it is growing very rapidly,” replied Altman. “You told me that it like doubled in just a few weeks,” Anderson continued. “I said that priv
 Pixtral-12B: Mistral AI's First Multimodal Model - Analytics VidhyaApr 13, 2025 am 11:20 AM
Pixtral-12B: Mistral AI's First Multimodal Model - Analytics VidhyaApr 13, 2025 am 11:20 AMIntroduction Mistral has released its very first multimodal model, namely the Pixtral-12B-2409. This model is built upon Mistral’s 12 Billion parameter, Nemo 12B. What sets this model apart? It can now take both images and tex
 Agentic Frameworks for Generative AI Applications - Analytics VidhyaApr 13, 2025 am 11:13 AM
Agentic Frameworks for Generative AI Applications - Analytics VidhyaApr 13, 2025 am 11:13 AMImagine having an AI-powered assistant that not only responds to your queries but also autonomously gathers information, executes tasks, and even handles multiple types of data—text, images, and code. Sounds futuristic? In this a
 Applications of Generative AI in the Financial SectorApr 13, 2025 am 11:12 AM
Applications of Generative AI in the Financial SectorApr 13, 2025 am 11:12 AMIntroduction The finance industry is the cornerstone of any country’s development, as it drives economic growth by facilitating efficient transactions and credit availability. The ease with which transactions occur and credit
 Guide to Online Learning and Passive-Aggressive AlgorithmsApr 13, 2025 am 11:09 AM
Guide to Online Learning and Passive-Aggressive AlgorithmsApr 13, 2025 am 11:09 AMIntroduction Data is being generated at an unprecedented rate from sources such as social media, financial transactions, and e-commerce platforms. Handling this continuous stream of information is a challenge, but it offers an


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

WebStorm Mac version
Useful JavaScript development tools

