
Home >Technology peripherals >AI >Sora is not open source, Microsoft will open source it for you! The world's closest Sora video model is born, with realistic and explosive effects in 12 seconds
Sora is not open source, Microsoft will open source it for you! The world's closest Sora video model is born, with realistic and explosive effects in 12 seconds

- PHPzforward
- 2024-03-22 23:10:32715browse
Microsoft version of Sora is born!
Although Sora is popular, it is closed source, which has brought considerable challenges to the academic community. Scholars can only try to use reverse engineering to reproduce or extend Sora.
Although Diffusion Transformer and spatial patch strategies have been proposed, it is still difficult to achieve the performance of Sora, not to mention the lack of computing power and data sets.
However, a new wave of charges launched by researchers to reproduce Sora is coming!
Just now, Lehigh University teamed up with the Microsoft team to develop a new multi-AI agent framework—Mora.

Paper address: https://arxiv.org/abs/2403.13248
Yes, The idea of Lehigh University and Microsoft is to rely on AI agents.
Mora is more like Sora's generalist video generation. By integrating multiple SOTA visual AI agents, the universal video generation capabilities demonstrated by Sora can be reproduced.

Specifically, Mora is able to utilize multiple visual agents to successfully simulate Sora’s video generation capabilities in a variety of tasks, including:
- Text to video generation
- Image to video generation based on text conditions
- Extend generated video
- Video to video editing
- Stitch video
- Simulation Digital World
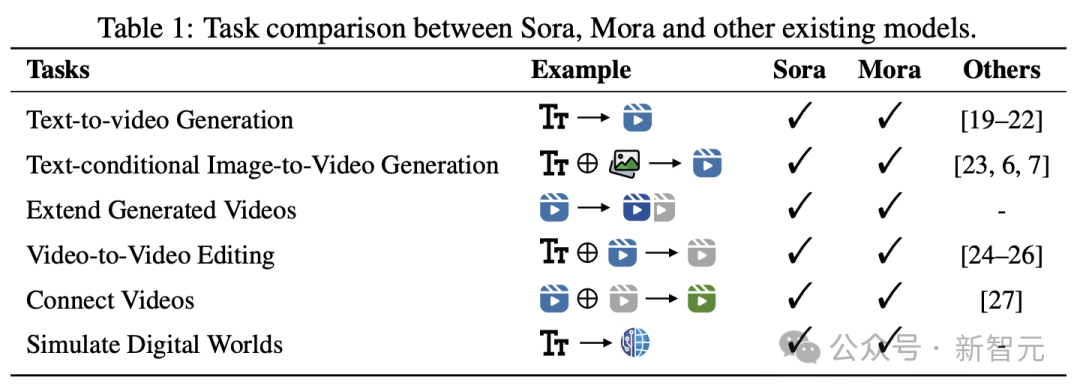
Experimental results show that Mora achieves performance close to Sora in these tasks.
It is worth mentioning that its performance in text-to-video generation tasks surpasses existing open source models and ranks second among all models, second only to Sora.
However, in terms of overall performance, there is still a clear gap with Sora.

Mora can generate high-resolution, time-coherent videos based on text prompts, with a resolution of 1024 × 576, a duration of 12 seconds, and a total of 75 frames. .
Restore all Sora's abilities
Mora basically restores all Sora's abilities. How to embody it?
Text to video generation

Tip: A vibrant coral reef teeming with life under the crystal-clear blue ocean, with colorful fish swimming among the coral, rays of sunlight filtering through the water, and a gentle current moving the sea plants.

Tip: A majestic mountain range covered in snow, with the peaks touching the clouds and a crystal-clear lake at its base, reflecting the mountains and the sky, creating a breathtaking natural mirror.

## Tip: In the middle of a vast desert, a golden desert city appears on the horizon, its architecture a blend of ancient Egyptian and futuristic elements.The city is surrounded by a radiant energy barrier, while in the air, seve
based on Text conditional image to video generation
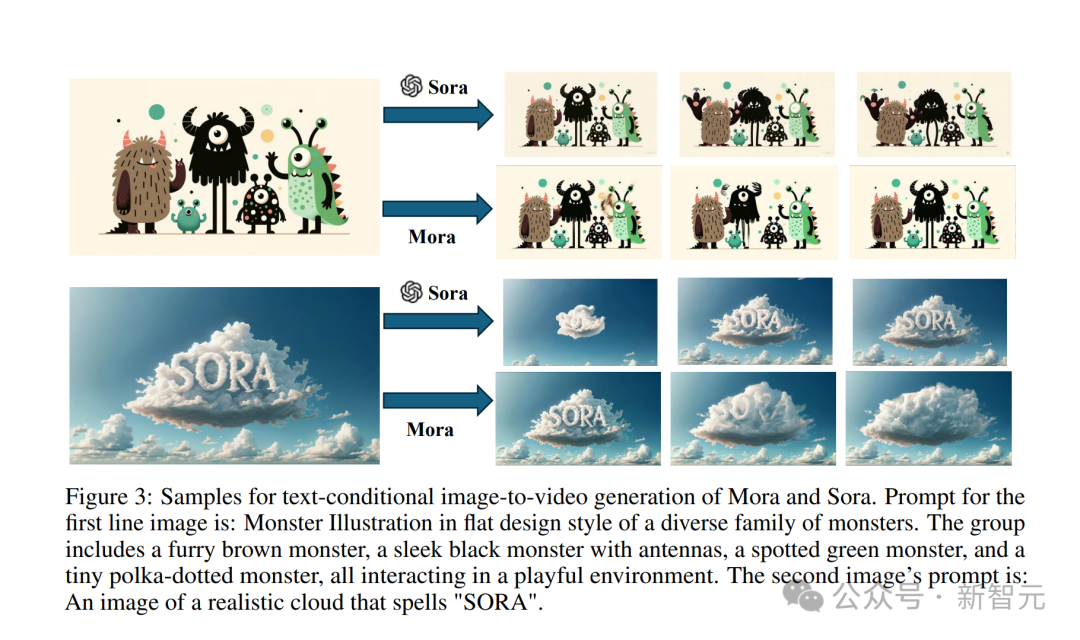
Enter this classic "realistic cloud image with the word SORA".

Tips: An image of a realistic cloud that spells “SORA”.
Sora model generation The effect is like this.

The video generated by Mora is not bad at all.

Also enter a picture of a little monster.

Tip: Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas , a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
Sora converted it into video effects to make these little monsters come alive .
Although Mora also makes the little monsters move, it is obviously a little unstable, and the cartoon characters in the picture do not look consistent.

Expand the generated video
Give a video first

#Sora can generate stable AI videos with consistent styles.

#But in the video generated by Mora, the cyclist in front ended up with his bike gone and the person deformed, so the effect was not very good.

Video to video editor
Give me a prompt "Convert the scene Switch to 1920s Vintage Cars" and enter a video. 
#After Sora's style replacement, the overall look is very silky.

#Mora The generation of old-fashioned cars is a bit unreal because they are so shabby.

Splicing video
Enter two videos and finish it Splicing.


Mora’s spliced video

Analog Digital World

Overall close, but not as good as Sora
After a large number of demonstrations, everyone has a certain understanding of Mora’s video generation capabilities.
Compared with OpenAI Sora, Mora's performance in six tasks is very close, but there are also big shortcomings.
Text-to-video generation
Specifically, Mora’s video quality score of 0.792 was second only to first Sora's 0.797, and exceeds the current best open source model (such as VideoCrafter1).
In terms of object consistency, Mora scored 0.95, which is the same as Sora, showing excellent consistency throughout the video.
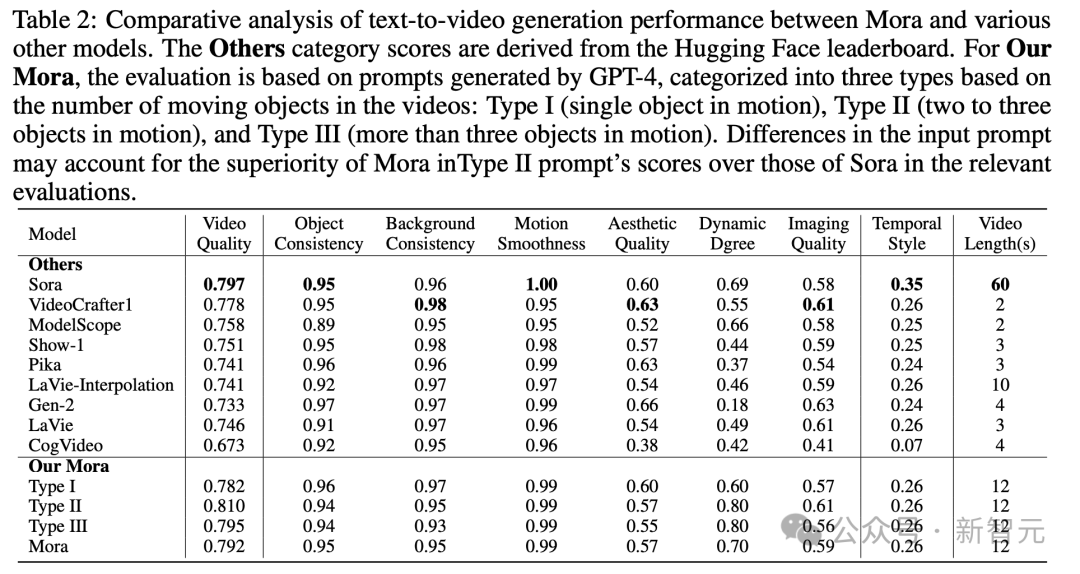
In the image below, the visual fidelity of Mora text-to-video generation is very striking, reflecting the high-resolution images and attention to detail. Keen attention, and vivid depiction of the scene.

In the image generation task based on text conditions, Sora is definitely the best model in terms of its ability to convert pictures and text instructions into coherent videos. perfect.
But Mora’s results are very different from Sora’s.
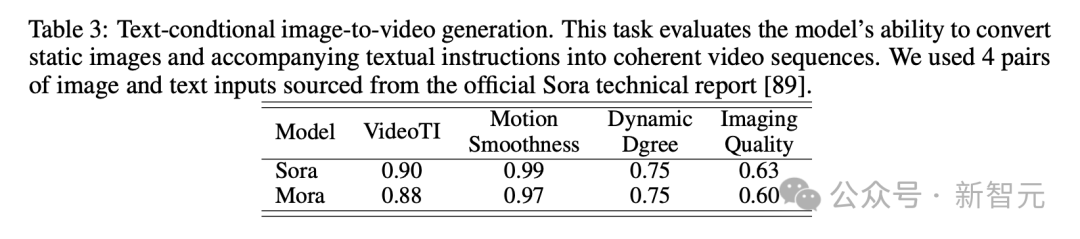
Extension generated video
Looking at the extended generation video test, the results in terms of continuity and quality are also that Mora is relatively close to Sora.
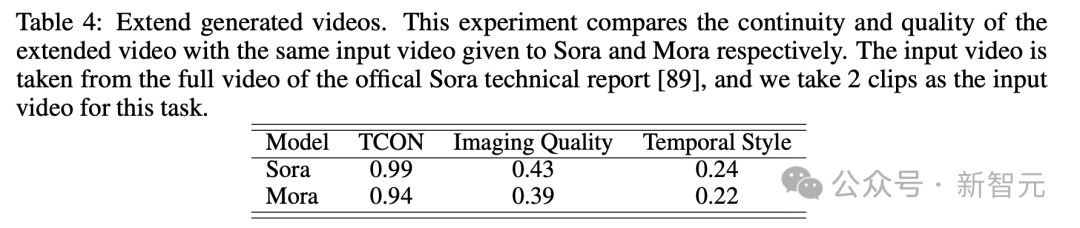
Despite Sora's lead, Mora's ability, especially in following chronological styles and extending existing videos without significant loss of quality, Proven its effectiveness in the field of video extension.

Video to Video Editing Video Stitching
For video to video editing, Mora keeps the visual and Close to Sora in terms of ability for stylistic coherence. In the video splicing task, Mora can also seamlessly splice different videos.
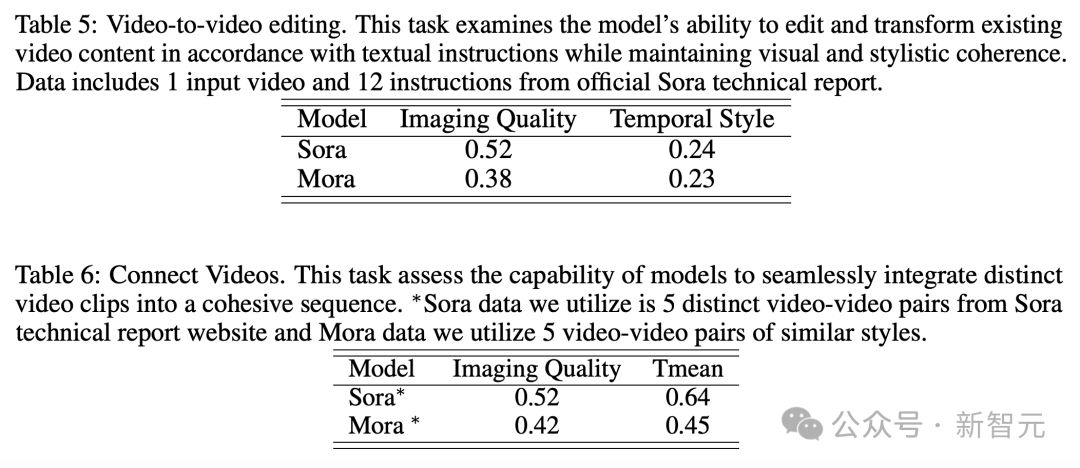
In this example, both Sora and Mora were instructed to modify the settings to a 1920s style while keeping the car's red color.


##Analog Digital World
There is also the final task of simulating the digital world. Mora can also have the ability to create a virtual environment world like Sora. However, in terms of quality, it is worse than Sora.


Mora is a multi-agent framework , how to solve the limitations of current video generation models?
The key is to flexibly complete a series of video generation tasks by decomposing the video generation process into multiple subtasks and assigning dedicated agents to each task to meet the needs of Diverse needs of users.
During the inference process, Mora generates an intermediate image or video, thereby maintaining the visual variety, style, and quality found in text-to-image models and enhancing editing capabilities.

Intelligence by efficiently coordinating the processing of conversion tasks from text to image, from image to image, from image to video, and from video to video Overall, Mora is capable of handling a range of complex video generation tasks, providing outstanding editing flexibility and visual realism.
In summary, the team’s main contributions are as follows:
- Innovative multi-agent framework and an intuitive interface to facilitate users to configure different components and arrange task processes.
- The author found that through the collaborative work of multiple agents (including converting text into images, images into videos, etc.), the quality of video generation can be significantly improved. The process starts with text, which is converted into images, then the images and text together are converted into videos, and finally the videos are optimized and edited.
- Mora demonstrated superior performance in 6 video-related tasks, surpassing existing open source models. This not only proves Mora's efficiency, but also demonstrates its potential as a multi-purpose framework.
Definition of Agent
In different tasks of video generation, multiple agents with different expertise are usually required to work together. Each agent provides output in its area of expertise.
To this end, the author defines 5 basic types of agents: prompt selection and generation, text-to-image generation, image-to-image generation, image-to-video generation, and video-to-video generate.
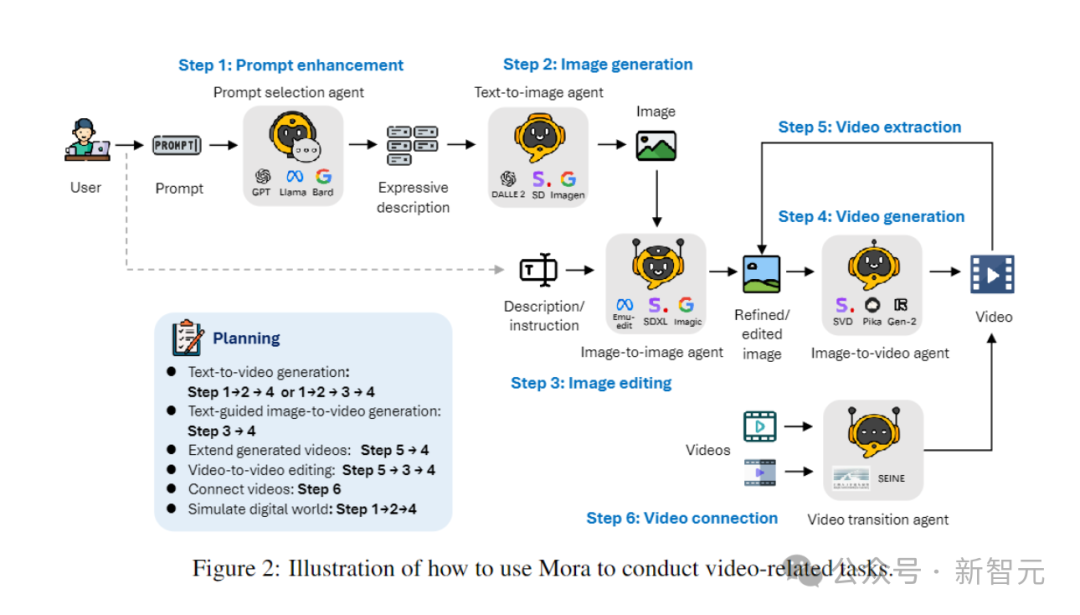
- Prompt for selecting and generating agents:
Text prompt before starting to generate the initial image It will go through a series of rigorous processing and optimization steps. This agent can leverage large language models (such as GPT-4) to accurately analyze text, extract key information and actions, and greatly improve the relevance and quality of generated images.
- Text-to-Image Generation Agent:
This agent is responsible for converting rich text descriptions into high-quality images. Its core functionality is to deeply understand and visualize complex text input, enabling the creation of detailed, accurate visual images based on the provided text descriptions.
- Image-to-image generation agent:
Modify an existing source image based on specific text instructions. It accurately interprets text cues and adjusts source images accordingly, from subtle modifications to complete transformations. By using pre-trained models, it can effectively splice text descriptions and visual representations, enabling the integration of new elements, adjustments to visual styles, or changes in image composition.
- Image to Video Generation Agent:
After the initial image generation, this agent is responsible for converting static images into dynamic videos. It analyzes the content and style of the initial image to generate subsequent frames to ensure the coherence and visual consistency of the video, demonstrating the model's ability to understand, replicate the initial image, and foresee and implement the logical development of the scene.
-Video splicing agent:
This agent ensures smoothness and smoothness between them by selectively using key frames of two videos. Visually consistent transitions. It accurately identifies common elements and styles in two videos, producing a video that is both coherent and visually appealing.
Realization of the agent
Text to image generation
Researchers use pre-training A large text-to-image model to generate high-quality and representative first images.
The first implementation uses Stable Diffusion XL.
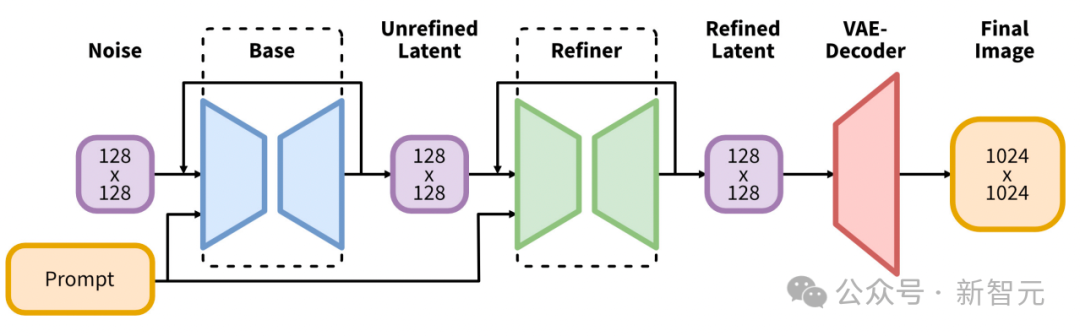
It introduces a significant evolution in the architecture and methods of latent diffusion models for text-to-image synthesis, setting a new benchmark in the field.
At the core of its architecture is an expanded UNet backbone network that is three times larger than the backbone used in previous versions of Stable Diffusion 2.
This expansion is mainly achieved by increasing the number of attention blocks and a wider range of cross-attention contexts, and by integrating bi-text encoder system to facilitate.
The first encoder is based on OpenCLIP ViT-bigG, while the second encoder utilizes CLIP ViT-L, allowing text input to be modified by splicing the output of these encoders. A richer, more nuanced explanation.

This architectural innovation is complemented by the introduction of a variety of novel adjustment schemes that do not require external supervision, thus enhancing the flexibility of the model and the ability to generate images across multiple aspect ratios.
Additionally, SDXL features a refinement model that employs post hoc image-to-image transformation to improve the visual quality of the generated images.
This refinement process utilizes noise denoising technology to further refine the output image without affecting the efficiency or speed of the generation process.
Image-to-image generation
In this process, the researcher used the initial framework to implement InstructPix2Pix As an image-to-image generative agent.

InstructPix2Pix is carefully designed for effective image editing based on natural language instructions.
The core of the system integrates the extensive knowledge of two pre-trained models: GPT-3 is used to generate editing instructions and edited titles based on text descriptions; Stable Diffusion is used to combine these Text-based input is converted into visual output.
This ingenious approach first fine-tunes GPT-3 on a curated dataset of image captions and corresponding editing instructions, resulting in a model that can creatively suggest sensible edits and generate modified captions.
After this, the Stable Diffusion model enhanced by Prompt-to-Prompt technology generates image pairs (before and after editing) based on the subtitles generated by GPT-3.
Then train the conditional diffusion model of InstructPix2Pix core on the generated dataset.
InstructPix2Pix directly leverages text instructions and input images to perform editing in a single forward pass.
This efficiency is further improved by employing classifier-free guidance for image and instruction conditions, allowing the model to balance raw image fidelity and compliance with editing instructions.
Image-to-video generation
#In the text-to-video generation agent, the video generation agent ensures that the video Quality and consistency play an important role.
The researcher’s first implementation is to use the current SOTA video generation model Stable Video Diffusion to generate videos.

The SVD architecture leverages the strengths of Stable Diffusion v2.1, an LDMs originally developed for image synthesis, extending its functionality to handle the inherent time complexity, thus introducing an advanced method for generating high-resolution videos.
The core of the SVD model follows a three-stage training system, starting from text to image correlation, and the model learns a robust visual representation from a set of different images. This foundation enables the model to understand and generate complex visual patterns and textures.
In the second stage, video pre-training, the model is exposed to large amounts of video data, enabling it to learn temporally by combining temporal convolution and attention layers with their spatial counterparts Dynamic and Sport modes.
Training is performed on system-managed datasets, ensuring the model learns from high-quality and relevant video content.
The final stage is high-quality video fine-tuning, which focuses on improving the model's ability to generate videos with higher resolution and fidelity using smaller but higher-quality datasets.
This layered training strategy, supplemented by a novel data management process, enables SVD to excel in producing state-of-the-art text-to-video and image-to-video synthesis over time. , with extraordinary detail, authenticity and coherence.
Splicing videos
For this task, the researchers used SEINE to stitch the videos.
SEINE is built based on the pre-trained T2V model LaVie agent.
SEINE centers on a stochastic masked video diffusion model that generates transitions based on textual descriptions.
By integrating images of different scenes with text-based controls, SEINE can generate transition videos that maintain coherence and visual quality.
Additionally, the model can be extended to tasks such as image-to-video animation and white regression video prediction.
Discussion
Advantages
- Innovation Framework and Flexibility:
Mora introduces a revolutionary multi-agent video generation framework that greatly expands the possibilities in this field, making it possible to perform a variety of tasks.
It not only simplifies the process of converting text into video, but also simulates the digital world, showing unprecedented flexibility and efficiency.
- Open Source Contribution:
Mora’s open source nature is an important contribution to the AI community by providing a solid foundation to encourage Further development and improvement lay the foundation for future research.
This will not only make advanced video generation technology more popular, but also promote cooperation and innovation in this field.
Limitations
- Video data is crucial:
Want to capture human movements Subtle differences require high-resolution, smooth video sequences. This allows all aspects of dynamics to be shown in detail, including balance, posture and interaction with the environment.
But high-quality video data sets mostly come from professional sources such as movies, TV shows, and proprietary game footage. They often contain copyrighted material that is difficult to legally collect or use.
The lack of these data sets makes it difficult for video generative models like Mora to simulate human actions in real-world environments, such as walking or riding a bicycle.
- Gap between mass and length:
Although Mora can complete tasks similar to Sora, in scenes involving the movement of a large number of objects, The quality of the resulting video is noticeably low, with quality decreasing as the length of the video increases, especially after it exceeds 12 seconds.
- Instruction following ability:
Although Mora can include all objects specified by the prompt in the video, it is difficult to accurately explain and demonstrate Movement dynamics described in the tip, such as movement speed.
In addition, Mora cannot control the direction of movement of the object. For example, it cannot make the object move left or right.
These limitations are mainly due to the fact that Mora's video generation is based on the image-to-video method, rather than directly obtaining instructions from text prompts.
- Human preference alignment:
Due to the lack of human annotation information in the video field, experimental results may not always conform to human visual preferences .
For example, one of the video splicing tasks above requires generating a transition video of a man gradually turning into a woman, which seems very illogical.
The above is the detailed content of Sora is not open source, Microsoft will open source it for you! The world's closest Sora video model is born, with realistic and explosive effects in 12 seconds. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- How to query data in redis
- What are the database types?
- Another revolution in reinforcement learning! DeepMind proposes 'algorithm distillation': an explorable pre-trained reinforcement learning Transformer
- Programmers are in danger! It is said that OpenAI recruits outsourcing troops globally and trains ChatGPT code farmers step by step
- What video editing software is available?