

 Technology peripheralsAICMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds
Technology peripheralsAICMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 secondsCMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds

A simple sketch can be transformed into a multi-style painting with one click, and additional descriptions can be added. This was achieved in a study jointly launched by CMU and Adobe.
CMU Assistant Professor Junyan Zhu is an author of the study, and his team published a related study at the ICCV 2021 conference. This study shows how an existing GAN model can be customized with a single or a few hand-drawn sketches to generate images that match the sketch.

- Paper address: https://arxiv.org/pdf/2403.12036.pdf
- GitHub address: https://github.com/GaParmar/img2img-turbo
- Trial address: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
- Paper title: One-Step Image Translation with Text -to-Image Models
How effective is it? We tried it out and came to the conclusion that it is very playable. The output image styles are diverse, including cinematic style, 3D models, animation, digital art, photography style, pixel art, fantasy school, neon punk and comics.
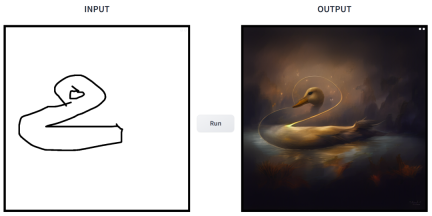
prompt is "duck".

prompt is "a small house surrounded by vegetation".

prompt is "Chinese boys playing basketball".
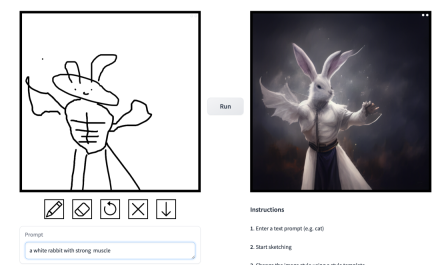
prompt is "Muscle Man Rabbit".

 #
#
In this work, researchers have made targeted improvements to the problems existing in the application of conditional diffusion models in image synthesis. Such models allow users to generate images based on spatial conditions and text prompts, with precise control over scene layout, user sketches, and human poses.
But the problem is that the iteration of the diffusion model causes the inference speed to slow down, limiting real-time applications, such as interactive Sketch2Photo. In addition, model training usually requires large-scale paired data sets, which brings huge costs to many applications and is not feasible for some other applications.
In order to solve the problems of the conditional diffusion model, researchers have introduced a general method that uses adversarial learning objectives to adapt the single-step diffusion model to new tasks and new fields. Specifically, they integrate individual modules of a vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, thereby enhancing the model's ability to preserve the structure of the input image while reducing overfitting.
Researchers have launched the CycleGAN-Turbo model. In an unpaired setting, this model can outperform existing GAN and diffusion-based methods in various scene conversion tasks, such as day and night. Convert, add or remove weather effects such as fog, snow, rain.
At the same time, in order to verify the versatility of their own architecture, the researchers conducted experiments on paired settings. The results show that their model pix2pix-Turbo achieves visual effects comparable to Edge2Image and Sketch2Photo, and reduces the inference step to 1 step.
In summary, this work demonstrates that one-step pre-trained text-to-image models can serve as a powerful, versatile backbone for many downstream image generation tasks.
Method introduction
This study proposes a general method that combines a single-step diffusion model (such as SD-Turbo) with adversarial learning Adapt to new tasks and domains. This leverages the internal knowledge of the pre-trained diffusion model while enabling efficient inference (e.g., 0.29 seconds on the A6000 and 0.11 seconds on the A100 for a 512x512 image).
Additionally, the single-step conditional models CycleGAN-Turbo and pix2pix-Turbo can perform a variety of image-to-image translation tasks, suitable for both pairwise and non-pairwise settings. CycleGAN-Turbo surpasses existing GAN-based and diffusion-based methods, while pix2pix-Turbo is on par with recent work such as ControlNet for Sketch2Photo and Edge2Image, but with the advantage of single-step inference.
Add conditional input
In order to convert the text-to-image model into an image-conversion model, the first thing to do is Find an efficient way to incorporate the input image x into the model.
A common strategy for incorporating conditional inputs into Diffusion models is to introduce additional adapter branches, as shown in Figure 3.

Specifically, this study initializes a second encoder and labels it as a condition encoder (Condition Encoder). The Control Encoder accepts the input image x and outputs feature maps of multiple resolutions to the pre-trained Stable Diffusion model through residual connections. This method achieves remarkable results in controlling diffusion models.
As shown in Figure 3, this study uses two encoders (U-Net encoder and conditional encoder) in a single-step model to process noisy images and input image encounters challenges. Unlike multi-step diffusion models, the noise map in single-step models directly controls the layout and pose of the generated image, which often contradicts the structure of the input image. Therefore, the decoder receives two sets of residual features representing different structures, which makes the training process more challenging.
Direct conditional input. Figure 3 also illustrates that the image structure generated by the pre-trained model is significantly affected by the noise map z. Based on this insight, the study recommends feeding conditional inputs directly to the network. To adapt the backbone model to new conditions, the study added several LoRA weights to various layers of U-Net (see Figure 2).
Preserve input details
Latent diffusion models (LDMs) image encoders work by spatially resolving the input image into The rate compression is 8 times while increasing the number of channels from 3 to 4 to speed up the training and inference process of the diffusion model. While this design can speed up training and inference, it may not be ideal for image conversion tasks that require preserving the details of the input image. Figure 4 illustrates this problem, where we take an input image of daytime driving (left) and convert it to a corresponding image of nighttime driving, using an architecture that does not use skip connections (center). It can be observed that fine-grained details such as text, street signs, and distant cars are not preserved. In contrast, the resulting transformed image using an architecture that includes skip connections (right) does a better job of preserving these complex details.
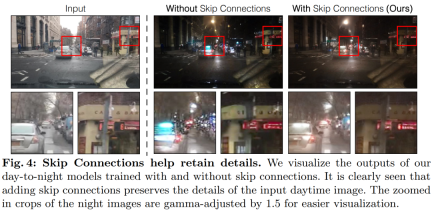
To capture the fine-grained visual details of the input image, the study added skip connections between the encoder and decoder networks (see Figure 2 ). Specifically, the study extracts four intermediate activations after each downsampling block within the encoder and processes them through a 1 × 1 zero convolutional layer before feeding them into the corresponding upsampling block in the decoder. . This approach ensures that intricate details are preserved during image conversion.

Experiment
This study combines CycleGAN-Turbo with previous GAN-based non-paired images Conversion methods were compared. From a qualitative analysis, Figure 5 and Figure 6 show that neither the GAN-based method nor the diffusion-based method can achieve a balance between output image realism and maintaining structure.


The study also compared CycleGAN-Turbo to CycleGAN and CUT. Tables 1 and 2 present the results of quantitative comparisons on eight unpaired switching tasks.


##CycleGAN and CUT on simpler, object-centric data On the set, such as horse → zebra (Fig. 13), it shows effective performance and achieves low FID and DINO-Structure scores. Our method slightly outperforms these methods in FID and DINO-Structure distance metrics.

As shown in Table 1 and Figure 14, in the object-centered data set (such as horse → zebra) These methods can generate realistic zebras, but have difficulties in accurately matching object poses.
On the driving dataset, these editing methods perform significantly worse for three reasons: (1) the model has difficulty generating complex scenes containing multiple objects, (2) these methods ( Except for Instruct-pix2pix) the image needs to be inverted into a noise map first, introducing potential human error, (3) the pre-trained model cannot synthesize street view images similar to those captured by the driving dataset. Table 2 and Figure 16 show that on all four driving transition tasks, these methods output images of poor quality and do not follow the structure of the input image.


The above is the detailed content of CMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds. For more information, please follow other related articles on the PHP Chinese website!

 Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AM
Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AMCyberattacks are evolving. Gone are the days of generic phishing emails. The future of cybercrime is hyper-personalized, leveraging readily available online data and AI to craft highly targeted attacks. Imagine a scammer who knows your job, your f
 Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AM
Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AMIn his inaugural address to the College of Cardinals, Chicago-born Robert Francis Prevost, the newly elected Pope Leo XIV, discussed the influence of his namesake, Pope Leo XIII, whose papacy (1878-1903) coincided with the dawn of the automobile and
 FastAPI-MCP Tutorial for Beginners and Experts - Analytics VidhyaMay 11, 2025 am 10:56 AM
FastAPI-MCP Tutorial for Beginners and Experts - Analytics VidhyaMay 11, 2025 am 10:56 AMThis tutorial demonstrates how to integrate your Large Language Model (LLM) with external tools using the Model Context Protocol (MCP) and FastAPI. We'll build a simple web application using FastAPI and convert it into an MCP server, enabling your L
 Dia-1.6B TTS : Best Text-to-Dialogue Generation Model - Analytics VidhyaMay 11, 2025 am 10:27 AM
Dia-1.6B TTS : Best Text-to-Dialogue Generation Model - Analytics VidhyaMay 11, 2025 am 10:27 AMExplore Dia-1.6B: A groundbreaking text-to-speech model developed by two undergraduates with zero funding! This 1.6 billion parameter model generates remarkably realistic speech, including nonverbal cues like laughter and sneezes. This article guide
 3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AM
3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AMI wholeheartedly agree. My success is inextricably linked to the guidance of my mentors. Their insights, particularly regarding business management, formed the bedrock of my beliefs and practices. This experience underscores my commitment to mentor
 AI Unearths New Potential In The Mining IndustryMay 10, 2025 am 11:16 AM
AI Unearths New Potential In The Mining IndustryMay 10, 2025 am 11:16 AMAI Enhanced Mining Equipment The mining operation environment is harsh and dangerous. Artificial intelligence systems help improve overall efficiency and security by removing humans from the most dangerous environments and enhancing human capabilities. Artificial intelligence is increasingly used to power autonomous trucks, drills and loaders used in mining operations. These AI-powered vehicles can operate accurately in hazardous environments, thereby increasing safety and productivity. Some companies have developed autonomous mining vehicles for large-scale mining operations. Equipment operating in challenging environments requires ongoing maintenance. However, maintenance can keep critical devices offline and consume resources. More precise maintenance means increased uptime for expensive and necessary equipment and significant cost savings. AI-driven
 Why AI Agents Will Trigger The Biggest Workplace Revolution In 25 YearsMay 10, 2025 am 11:15 AM
Why AI Agents Will Trigger The Biggest Workplace Revolution In 25 YearsMay 10, 2025 am 11:15 AMMarc Benioff, Salesforce CEO, predicts a monumental workplace revolution driven by AI agents, a transformation already underway within Salesforce and its client base. He envisions a shift from traditional markets to a vastly larger market focused on
 AI HR Is Going To Rock Our Worlds As AI Adoption SoarsMay 10, 2025 am 11:14 AM
AI HR Is Going To Rock Our Worlds As AI Adoption SoarsMay 10, 2025 am 11:14 AMThe Rise of AI in HR: Navigating a Workforce with Robot Colleagues The integration of AI into human resources (HR) is no longer a futuristic concept; it's rapidly becoming the new reality. This shift impacts both HR professionals and employees, dem


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

