

 Technology peripheralsAIComplete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals
Technology peripheralsAIComplete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals
Advances in large language models (LLMs) have largely driven the field of code generation. In previous research, reinforcement learning (RL) and compiler feedback signals were combined to explore the output space of LLMs to optimize the quality of code generation.
But there are still two problems:
#1. Reinforcement learning exploration is difficult to directly adapt to "complex human needs". That is, LLMs are required to generate "long sequence code";
2. Since unit tests may not cover complex code, it is ineffective to use unexecuted code snippets to optimize LLMs.
To address these challenges, the researchers proposed a new reinforcement learning framework called StepCoder, which was jointly developed by experts from Fudan University, Huazhong University of Science and Technology, and Royal Institute of Technology. StepCoder contains two key components designed to improve the efficiency and quality of code generation.
1. CCCSAddresses exploration challenges by breaking long sequence code generation tasks into code completion sub-task courses;
2. FGOOptimizes the model by masking unexecuted code segments to provide fine-grained optimization.

Paper link: https://arxiv.org/pdf/2402.01391.pdf
Project Link: https://github.com/Ablustrund/APPS_Plus
The researchers also built the APPS data set for reinforcement learning training and manually verified it to ensure the correctness of the unit tests.
Experimental results show that the method improves the ability to explore the output space and outperforms state-of-the-art methods on corresponding benchmarks.
StepCoder
In the code generation process, ordinary reinforcement learning exploration (exploration) is difficult to handle "environments with sparse and delayed rewards" and "long sequences". Complex needs".
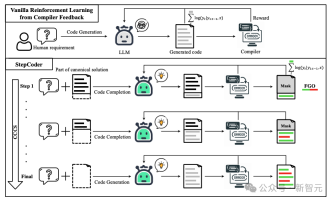
In the CCCS (Curriculum of Code Completion Subtasks) stage, researchers decompose complex exploration problems into a series of subtasks. Using a portion of the canonical solution as a prompt, LLM can start exploring from simple sequences.
The calculation of rewards is only related to executable code fragments, so it is inaccurate to use the entire code (red part in the figure) to optimize LLM (gray part in the figure).
In the FGO (Fine-Grained Optimization) stage, researchers mask the unexecuted tokens (red part) in the unit test and only use the executed tokens (green part) Computes a loss function, which can provide fine-grained optimization.
Preliminary knowledge
Assume that  is a training data set used for code generation, where x, y, and u represent human needs (i.e., task description), standard solutions, and unit test samples respectively.
is a training data set used for code generation, where x, y, and u represent human needs (i.e., task description), standard solutions, and unit test samples respectively.
 is a list of conditional statements obtained by automatically analyzing the abstract syntax tree of the standard solution yi, where st and en represent the starting position and ending position of the statement respectively.
is a list of conditional statements obtained by automatically analyzing the abstract syntax tree of the standard solution yi, where st and en represent the starting position and ending position of the statement respectively.
For human needs x, its standard solution y can be expressed as  ; in the code generation stage, given human needs x, the final state is through the unit A collection of codes that test u.
; in the code generation stage, given human needs x, the final state is through the unit A collection of codes that test u.
Method details
StepCoder integrates two key components: CCCS and FGO, where the purpose of CCCS is to Courses in which code generation tasks are decomposed into code completion subtasks can alleviate exploration challenges in RL; FGO is designed specifically for code generation tasks and provides fine-grained optimization by only calculating the loss of executed code fragments.
CCCS
In the code generation process, to solve complex human needs, policy models usually need to adopt relatively complex Long action sequences. At the same time, the compiler's feedback is delayed and sparse, that is, the policy model only receives rewards after the entire code has been generated. In this case, exploration is very difficult.
The core of the method is to decompose such a long list of exploration problems into a series of short, easy-to-explore subtasks. The researchers reduced code generation into code completion subtasks, where Subtasks are automatically constructed from typical solutions in the training dataset.
For human needs x, in the early training stage of CCCS, the starting point s* for exploration is a state near the final state.
Specifically, the researchers provide the human need x and the first half of the standard solution  , and train a policy model to predict xp) complete the code.
, and train a policy model to predict xp) complete the code.
Assuming that y^ is the combined sequence of xp and the output trajectory τ, that is, yˆ=(xp,τ), the reward model is provided based on the correctness of the code fragment τ with y^ as input Reward r.

The researchers used the proximal policy optimization (PPO) algorithm to optimize the policy model πθ by utilizing the reward r and trajectory τ.
During the optimization phase, the canonical solution code segment xp used to provide hints will be masked so that it will not have an impact on the gradient of the policy model πθ update.
CCCS optimizes the policy model πθ by maximizing the opposition function, where π^ref is the reference model in PPO and is initialized by the SFT model.

As training progresses, the starting point s* of exploration will gradually move toward the starting point of the standard solution. Specifically, a threshold ρ is set for each training sample. When the cumulative accuracy rate of the code segments generated by πθ is greater than ρ, the starting point is moved to beginning.
In the later stages of training, the exploration process of this method is equivalent to that of original reinforcement learning, that is, s*=0, and the policy model only generates code with human needs as input.
Sample the initial recognition point s* at the starting position of the conditional statement to complete the remaining unwritten code segment.
Specifically, the more conditional statements, the more independent paths the program has, and the higher the logic complexity. The complexity requires more frequent sampling to improve the training quality, and Programs with fewer conditional statements do not need to sample as frequently.
This sampling method can evenly extract representative code structures while taking into account both complex and simple semantic structures in the training data set.
To speed up the training phase, the researchers set the number of courses for the i-th sample to  , where Ei is the number of its conditional statements. The training course span of the i-th sample is
, where Ei is the number of its conditional statements. The training course span of the i-th sample is  , not 1.
, not 1.
The main points of CCCS can be summarized as follows:
1. It is easy to start exploring from a state close to the goal (i.e. the final state);
2. Exploration from a state further away from the goal is challenging, but exploration becomes easier if you can take advantage of states that have already learned how to reach the goal.
FGO
The relationship between rewards and actions in code generation is different from other reinforcement learning tasks (such as Atari ), in code generation it is possible to exclude a set of actions that are not relevant for calculating the reward in the generated code.
Specifically, for unit testing, the compiler’s feedback is only related to the executed code fragment. However, in the ordinary RL optimization goal, all actions on the trajectory will participate in the gradient calculation. , and the gradient calculation is imprecise.
In order to improve the optimization accuracy, the researchers shielded the unexecuted actions (i.e. tokens) in the unit test and the loss of the strategy model.

Experimental part
APPS data set
Reinforcement learning requires a large amount of high-quality training data. During the investigation, the researchers found that among the currently available open source data sets, only APPS meets this requirement.
But there are some incorrect instances in APPS, such as missing input, output or standard solution, where the standard solution may not compile or execute, or there may be differences in execution output.
To complete the APPS dataset, the researchers filtered out instances with missing inputs, outputs, or standard solutions, and then standardized the formats of inputs and outputs to facilitate the execution of unit tests. and comparison; each instance was then unit tested and manually analyzed, eliminating instances with incomplete or irrelevant code, syntax errors, API misuse, or missing library dependencies.
For differences in output, researchers manually review the problem description, correct the expected output, or eliminate the instance.
Finally, the APPS data set was constructed, containing 7456 instances. Each instance includes programming problem description, standard solution, function name, unit test (i.e. input and output) and Startup code (i.e. the beginning of a standard solution).

Experimental results
To evaluate the performance of other LLMs and StepCoder in code generation, researchers Experiments were conducted on the APPS dataset.
The results show that the RL-based model outperforms other language models, including the base model and the SFT model.
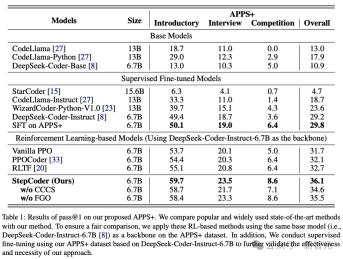
#The researchers have reason to infer that reinforcement learning can further improve performance by more efficiently browsing the model's output space, guided by compiler feedback. The quality of code generation.
Furthermore, StepCoder surpassed all baseline models, including other RL-based methods, and achieved the highest score.
Specifically, this method achieved 59.7%, High scores of 23.5% and 8.6%.
Compared with other reinforcement learning-based methods, this method performs well in exploring the output space by simplifying complex code generation tasks into code completion subtasks, and the FGO process performs well in Played a key role in accurately optimizing the strategy model.
It can also be found that on the APPS data set based on the same architecture network, the performance of StepCoder is better than the supervised LLM for fine-tuning; compared with the backbone network, the latter has almost no Improve the pass rate of generated code, which also directly shows that using compiler feedback to optimize the model can improve the quality of generated code more than the next token prediction in code generation.
The above is the detailed content of Complete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals. For more information, please follow other related articles on the PHP Chinese website!

 解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM
解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM译者 | 布加迪审校 | 孙淑娟目前,没有用于构建和管理机器学习(ML)应用程序的标准实践。机器学习项目组织得不好,缺乏可重复性,而且从长远来看容易彻底失败。因此,我们需要一套流程来帮助自己在整个机器学习生命周期中保持质量、可持续性、稳健性和成本管理。图1. 机器学习开发生命周期流程使用质量保证方法开发机器学习应用程序的跨行业标准流程(CRISP-ML(Q))是CRISP-DM的升级版,以确保机器学习产品的质量。CRISP-ML(Q)有六个单独的阶段:1. 业务和数据理解2. 数据准备3. 模型
 人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM
人工智能的环境成本和承诺Apr 08, 2023 pm 04:31 PM人工智能(AI)在流行文化和政治分析中经常以两种极端的形式出现。它要么代表着人类智慧与科技实力相结合的未来主义乌托邦的关键,要么是迈向反乌托邦式机器崛起的第一步。学者、企业家、甚至活动家在应用人工智能应对气候变化时都采用了同样的二元思维。科技行业对人工智能在创建一个新的技术乌托邦中所扮演的角色的单一关注,掩盖了人工智能可能加剧环境退化的方式,通常是直接伤害边缘人群的方式。为了在应对气候变化的过程中充分利用人工智能技术,同时承认其大量消耗能源,引领人工智能潮流的科技公司需要探索人工智能对环境影响的
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM
条形统计图用什么呈现数据Jan 20, 2021 pm 03:31 PM条形统计图用“直条”呈现数据。条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条,然后把这些直条按一定的顺序排列起来;从条形统计图中很容易看出各种数量的多少。条形统计图分为:单式条形统计图和复式条形统计图,前者只表示1个项目的数据,后者可以同时表示多个项目的数据。
 自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PM
自动驾驶车道线检测分类的虚拟-真实域适应方法Apr 08, 2023 pm 02:31 PMarXiv论文“Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving“,2022年5月,加拿大滑铁卢大学的工作。虽然自主驾驶的监督检测和分类框架需要大型标注数据集,但光照真实模拟环境生成的合成数据推动的无监督域适应(UDA,Unsupervised Domain Adaptation)方法则是低成本、耗时更少的解决方案。本文提出对抗性鉴别和生成(adversarial d
 数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM
数据通信中的信道传输速率单位是bps,它表示什么Jan 18, 2021 pm 02:58 PM数据通信中的信道传输速率单位是bps,它表示“位/秒”或“比特/秒”,即数据传输速率在数值上等于每秒钟传输构成数据代码的二进制比特数,也称“比特率”。比特率表示单位时间内传送比特的数目,用于衡量数字信息的传送速度;根据每帧图像存储时所占的比特数和传输比特率,可以计算数字图像信息传输的速度。
 数据分析方法有哪几种Dec 15, 2020 am 09:48 AM
数据分析方法有哪几种Dec 15, 2020 am 09:48 AM数据分析方法有4种,分别是:1、趋势分析,趋势分析一般用于核心指标的长期跟踪;2、象限分析,可依据数据的不同,将各个比较主体划分到四个象限中;3、对比分析,分为横向对比和纵向对比;4、交叉分析,主要作用就是从多个维度细分数据。
 聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM
聊一聊Python 实现数据的序列化操作Apr 12, 2023 am 09:31 AM在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块。这两个模块主要区别如下:json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式;json 是我们可以直观阅读的,而 pickle 不可以;json 是可互操作的,在 Python 系统之外广泛使用,而 pickle 则是 Python 专用的;默认情况下,json 只能表示 Python 内置类型的子集,不能表示自定义的


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Notepad++7.3.1
Easy-to-use and free code editor

