

 Technology peripheralsAIImproving generative zero-shot learning capabilities, the visually enhanced dynamic semantic prototyping method was selected for CVPR 2024
Technology peripheralsAIImproving generative zero-shot learning capabilities, the visually enhanced dynamic semantic prototyping method was selected for CVPR 2024
Although I have never met you, it is possible for me to "know" you - this is the state that people hope for artificial intelligence to achieve after "first sight".
In order to achieve this goal, in traditional image recognition tasks, people train algorithm models on a large number of image samples with different category labels, so that the model can acquire the ability to recognize these images. . In the zero-shot learning (ZSL) task, people hope that the model can draw inferences and identify categories that have not seen image samples in the training stage.
Generative zero-shot learning (GZSL) is considered an effective method for zero-shot learning. In GZSL, the first step is to train a generator to synthesize visual features of unseen categories. This generation process is driven by leveraging semantic descriptions such as attribute labels as conditions. Once these virtual visual features are generated, you can start training a classification model that can recognize unseen classes just like you would a traditional classifier.
The training of the generator is crucial for generative zero-shot learning algorithms. Ideally, the visual feature samples of an unseen category generated by the generator based on the semantic description should have the same distribution as the visual features of real samples of that category. This means that the generator needs to be able to accurately capture the relationships and patterns between visual features in order to generate samples with a high degree of consistency and credibility. By training the generator, it can effectively learn the visual feature differences between different categories, and
In the existing generative zero-shot learning method, the generator is During training and use, Gaussian noise and the semantic description of the entire category are conditioned, which limits the generator to only optimize the entire category instead of describing each sample instance, so it is difficult to accurately reflect the visual characteristics of real samples. distribution, resulting in poor generalization performance of the model. In addition, the visual information of the data set shared by seen classes and unseen classes, that is, domain knowledge, is not fully utilized in the training process of the generator, which limits the transfer of knowledge from seen classes to unseen classes.
In order to solve these problems, graduate students from Huazhong University of Science and Technology and technical experts from Alibaba’s Yintai Commercial Group proposed a method called Visually Enhanced Dynamic Semantic Prototyping (VADS). This approach more fully introduces visual features of seen classes into semantic conditions, allowing the push generator to learn accurate semantic-visual mappings. This research paper "Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning" has been accepted by CVPR 2024, the top international academic conference in the field of computer vision.
Specifically, the above research presents three innovative points:
In zero-shot learning, visual features are used to enhance the generator , in order to generate reliable visual features, which is an innovative method.
The research also introduced two components, VDKL and VOSU. With the help of these components, the visual prior of the data set is effectively obtained, and by dynamically updating the visual features of the image, the prediction The semantic description of defined categories has been updated. This method effectively utilizes visual features.
The experimental results show that the effect of using visual features to enhance the generator in this study is very significant. Not only is this plug-and-play approach highly versatile, it also excels at improving generator performance.
Research details
VADS consists of two modules: (1) Visual perceptual domain knowledge learning module (VDKL) learns local deviations and global priors of visual features, That is, domain visual knowledge, which replaces pure Gaussian noise and provides richer prior noise information; (2) The vision-oriented semantic update module (VOSU) learns how to update its semantic prototype according to the visual representation of the sample, and the updated Domain visual knowledge is also included in the semantic prototype.
Finally, the research team concatenated the outputs of the two modules into a dynamic semantic prototype vector as the condition of the generator. A large number of experiments show that the VADS method achieves significantly better performance than existing methods on commonly used zero-shot learning data sets, and can be combined with other generative zero-shot learning methods to obtain general improvements in accuracy.
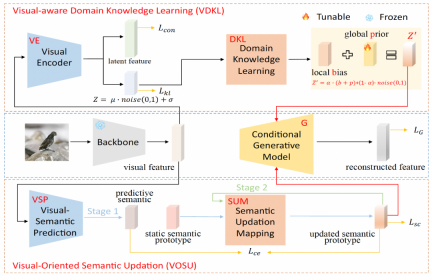
In the visual perception domain knowledge learning module (VDKL), the research team designed a visual encoder (VE) and a domain knowledge learning network (DKL). Among them, VE encodes visual features into latent features and latent encoding. By using contrastive loss to train VE using seen class image samples during the generator training stage, VE can enhance the class separability of visual features.
When training the ZSL classifier, the unseen visual features generated by the generator are also input to VE, and the obtained latent features are connected with the generated visual features as the final visual feature sample . The other output of VE, that is, the latent encoding, forms a local deviation b after DKL transformation. Together with the learnable global prior p and random Gaussian noise, it is combined into domain-related visual prior noise to replace other generative zero samples. Pure Gaussian noise commonly used in learning as part of the generator generation conditions.
In the Vision-Oriented Semantic Update Module (VOSU), the research team designed a visual semantic predictor VSP and a semantic update mapping network SUM. In the training phase of VOSU, VSP takes image visual features as input to generate a predicted semantic vector that can capture the visual pattern of the target image. At the same time, SUM takes the category semantic prototype as input, updates it, and obtains the updated semantic prototype, and then VSP and SUM are trained by minimizing the cross-entropy loss between the predicted semantic vector and the updated semantic prototype. The VOSU module can dynamically adjust the semantic prototype based on visual features, allowing the generator to rely on more accurate instance-level semantic information when synthesizing new category features.
In the experimental part, the above research used three ZSL data sets commonly used in academia: Animals with Attributes 2 (AWA2), SUN Attribute (SUN) and Caltech-USCD Birds-200 -2011 (CUB), a comprehensive comparison of the main indicators of traditional zero-shot learning and generalized zero-shot learning with other recent representative methods.
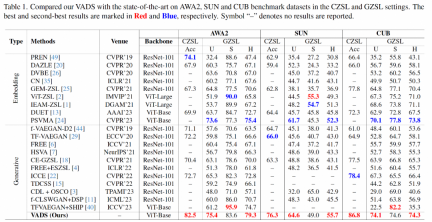
In terms of the Acc indicator of traditional zero-shot learning, the method studied in this study has achieved significant accuracy improvements compared with existing methods. Leading by 8.4%, 10.3% and 8.4% respectively on the three data sets. In the generalized zero-shot learning scenario, the above research method is also in a leading position in the harmonic mean index H of unseen class and seen class accuracy.
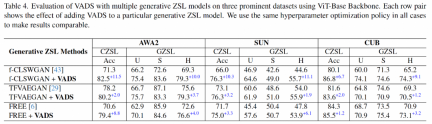
The VADS method can also be combined with other generative zero-shot learning methods. For example, after combining with the three methods of CLSWGAN, TF-VAEGAN and FREE, the Acc and H indicators on the three data sets are significantly improved, and the average improvement of the three data sets is 7.4%/5.9%, 5.6% /6.4% and 3.3%/4.2%.
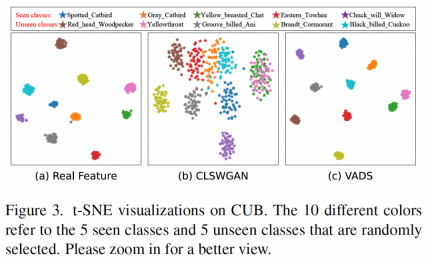
By visualizing the visual features generated by the generator, it can be seen that the features of some categories were originally confused together, such as the following figure (b ), the two types of features shown in the seen class "Yellow breasted Chat" and the unseen class "Yellowthroat" can be clearly separated into two clusters in Figure (c) after using the VADS method, thus avoiding the need for classification Confusion during machine training.
Can be extended to the fields of intelligent security and large models
Machine Heart learned that the above research The zero-shot learning that the research team focuses on aims to enable the model to recognize new categories without image samples in the training stage, which has potential value in the field of intelligent security.
First, deal with emerging risks in security scenarios. Since new threat types or unusual behavior patterns will continue to appear in security scenarios, they may appear in previous training data. Never appeared in . Zero-shot learning enables security systems to quickly identify and respond to new risk types, thereby improving security.
Second, reduce the dependence on sample data: Obtaining enough annotated data to train an effective security system is expensive and time-consuming. Zero-shot learning reduces the system’s dependence on a large number of image samples. dependence, thus saving R&D costs.
Third, improve the stability in dynamic environments: zero-shot learning uses semantic description to recognize unseen class patterns. Compared with traditional methods that rely entirely on image features, Changes in the visual environment are naturally more stable.
As the underlying technology to solve image classification problems, this technology can also be implemented in scenarios that rely on visual classification technology, such as attribute recognition of people, goods, vehicles, and objects, behavior recognition, etc. Especially in scenarios where new categories to be identified need to be quickly added and there is no time to collect training samples, or it is difficult to collect a large number of samples (such as risk identification), zero-shot learning technology has great advantages over traditional methods.
Does this research technology have any reference for the development of current large models?
Researchers believe that the core idea of generative zero-shot learning is to align the semantic space and the visual feature space, which is consistent with the visual language model (such as CLIP) in current multi-modal large models. The research objectives are consistent.
The biggest difference between them is that generative zero-shot learning is trained and used on pre-defined limited category data sets, while the visual language large model is trained on large The learning of data acquires universal semantic and visual representation capabilities, which are not limited to limited categories. As a basic model, it has a wider range of applications.
If the application scenario of the technology is a specific field, you can choose to adapt and fine-tune the large model to this field. In the process, work in the same or similar research direction as this article, theory It can bring some useful inspiration.
Introduction to the author
Hou Wenjin is a master’s student at Huazhong University of Science and Technology. His research interests include computer vision, generative modeling, few-shot learning, etc. He is working at Alibaba - Completed this thesis work during my internship at Yintai Business.
Wang Yan, Alibaba-Intime Commercial Technology Director, Algorithm Leader of Shenzhen Xiang Intelligent Team.
Feng Xuetao, Alibaba-Intime Business senior algorithm expert, mainly focuses on the application of visual and multi-modal algorithms in offline retail and other industries.
The above is the detailed content of Improving generative zero-shot learning capabilities, the visually enhanced dynamic semantic prototyping method was selected for CVPR 2024. For more information, please follow other related articles on the PHP Chinese website!

 How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AM
How to Run LLM Locally Using LM Studio? - Analytics VidhyaApr 19, 2025 am 11:38 AMRunning large language models at home with ease: LM Studio User Guide In recent years, advances in software and hardware have made it possible to run large language models (LLMs) on personal computers. LM Studio is an excellent tool to make this process easy and convenient. This article will dive into how to run LLM locally using LM Studio, covering key steps, potential challenges, and the benefits of having LLM locally. Whether you are a tech enthusiast or are curious about the latest AI technologies, this guide will provide valuable insights and practical tips. Let's get started! Overview Understand the basic requirements for running LLM locally. Set up LM Studi on your computer
 Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AM
Guy Peri Helps Flavor McCormick's Future Through Data TransformationApr 19, 2025 am 11:35 AMGuy Peri is McCormick’s Chief Information and Digital Officer. Though only seven months into his role, Peri is rapidly advancing a comprehensive transformation of the company’s digital capabilities. His career-long focus on data and analytics informs
 What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AM
What is the Chain of Emotion in Prompt Engineering? - Analytics VidhyaApr 19, 2025 am 11:33 AMIntroduction Artificial intelligence (AI) is evolving to understand not just words, but also emotions, responding with a human touch. This sophisticated interaction is crucial in the rapidly advancing field of AI and natural language processing. Th
 12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AM
12 Best AI Tools for Data Science Workflow - Analytics VidhyaApr 19, 2025 am 11:31 AMIntroduction In today's data-centric world, leveraging advanced AI technologies is crucial for businesses seeking a competitive edge and enhanced efficiency. A range of powerful tools empowers data scientists, analysts, and developers to build, depl
 AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AM
AV Byte: OpenAI's GPT-4o Mini and Other AI InnovationsApr 19, 2025 am 11:30 AMThis week's AI landscape exploded with groundbreaking releases from industry giants like OpenAI, Mistral AI, NVIDIA, DeepSeek, and Hugging Face. These new models promise increased power, affordability, and accessibility, fueled by advancements in tr
 Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AM
Perplexity's Android App Is Infested With Security Flaws, Report FindsApr 19, 2025 am 11:24 AMBut the company’s Android app, which offers not only search capabilities but also acts as an AI assistant, is riddled with a host of security issues that could expose its users to data theft, account takeovers and impersonation attacks from malicious
 Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AM
Everyone's Getting Better At Using AI: Thoughts On Vibe CodingApr 19, 2025 am 11:17 AMYou can look at what’s happening in conferences and at trade shows. You can ask engineers what they’re doing, or consult with a CEO. Everywhere you look, things are changing at breakneck speed. Engineers, and Non-Engineers What’s the difference be
 Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AM
Rocket Launch Simulation and Analysis using RocketPy - Analytics VidhyaApr 19, 2025 am 11:12 AMSimulate Rocket Launches with RocketPy: A Comprehensive Guide This article guides you through simulating high-power rocket launches using RocketPy, a powerful Python library. We'll cover everything from defining rocket components to analyzing simula


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Dreamweaver Mac version
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

